 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamOV: Streaming Omni-Video Understanding via Evidence-Guided Memory and Response Triggering
May 25, 2026While streaming omni-video understanding demands continuous perception and proactive, real-time interaction, this crucial area remains largely under-explored. Current omni-modal methods are inherently designed for offline settings, limiting their applicability in streaming scenarios due to two fundamental flaws. First, they lack robust mechanisms to manage continuously growing audio-visual context over long horizons and cannot autonomously initiate responses at opportune moments. Second, existing benchmarks are predominantly confined to offline, single-turn question answering, failing to capture continuous, multi-turn streaming interactions. To bridge these gaps, we propose StreamOV, a novel Streaming Omni-Video understanding framework for efficient online audio-visual reasoning with bounded memory and proactive response triggering. Specifically, StreamOV introduces a multimodal evidence-guided long-short term memory that condenses historical audio-visual context into compact informative evidence under a fixed budget. It further employs a hidden-state-driven trigger to decide when to respond, avoiding explicit silence-token generation and external routers. We also curate SOVBench, the first comprehensive benchmark for online, multi-turn omni-modal evaluation. Extensive experiments show that StreamOV achieves state-of-the-art performance across diverse streaming and omni-video benchmarks, demonstrating its effectiveness for both online and offline video understanding.
Rethinking Where to Edit: Task-Aware Localization for Instruction-Based Image Editing
Apr 22, 2026Instruction-based image editing (IIE) aims to modify images according to textual instructions while preserving irrelevant content. Despite recent advances in diffusion transformers, existing methods often suffer from over-editing, introducing unintended changes to regions unrelated to the desired edit. We identify that this limitation arises from the lack of an explicit mechanism for edit localization. In particular, different editing operations (e.g., addition, removal and replacement) induce distinct spatial patterns, yet current IIE models typically treat localization in a task-agnostic manner. To address this limitation, we propose a training-free, task-aware edit localization framework that exploits the intrinsic source and target image streams within IIE models. For each image stream, We first obtain attention-based edit cues, and then construct feature centroids based on these attentive cues to partition tokens into edit and non-edit regions. Based on the observation that optimal localization is inherently task-dependent, we further introduce a unified mask construction strategy that selectively leverages source and target image streams for different editing tasks. We provide a systematic analysis for our proposed insights and approaches. Extensive experiments on EdiVal-Bench demonstrate our framework consistently improves non-edit region consistency while maintaining strong instruction-following performance on top of powerful recent image editing backbones, including Step1X-Edit and Qwen-Image-Edit.
VTAM: Video-Tactile-Action Models for Complex Physical Interaction Beyond VLAs
Mar 24, 2026Video-Action Models (VAMs) have emerged as a promising framework for embodied intelligence, learning implicit world dynamics from raw video streams to produce temporally consistent action predictions. Although such models demonstrate strong performance on long-horizon tasks through visual reasoning, they remain limited in contact-rich scenarios where critical interaction states are only partially observable from vision alone. In particular, fine-grained force modulation and contact transitions are not reliably encoded in visual tokens, leading to unstable or imprecise behaviors. To bridge this gap, we introduce the Video-Tactile Action Model (VTAM), a multimodal world modeling framework that incorporates tactile perception as a complementary grounding signal. VTAM augments a pretrained video transformer with tactile streams via a lightweight modality transfer finetuning, enabling efficient cross-modal representation learning without tactile-language paired data or independent tactile pretraining. To stabilize multimodal fusion, we introduce a tactile regularization loss that enforces balanced cross-modal attention, preventing visual latent dominance in the action model. VTAM demonstrates superior performance in contact-rich manipulation, maintaining a robust success rate of 90 percent on average. In challenging scenarios such as potato chip pick-and-place requiring high-fidelity force awareness, VTAM outperforms the pi 0.5 baseline by 80 percent. Our findings demonstrate that integrating tactile feedback is essential for correcting visual estimation errors in world action models, providing a scalable approach to physically grounded embodied foundation models.
HiCI: Hierarchical Construction-Integration for Long-Context Attention
Mar 21, 2026Long-context language modeling is commonly framed as a scalability challenge of token-level attention, yet local-to-global information structuring remains largely implicit in existing approaches. Drawing on cognitive theories of discourse comprehension, we propose HiCI (Hierarchical Construction--Integration), a hierarchical attention module that constructs segment-level representations, integrates them into a shared global context, and broadcasts both to condition segment-level attention. We validate HiCI through parameter-efficient adaptation of LLaMA-2 with only <5.5% additional parameters, extending context from 4K to 100K tokens (7B) and 64K tokens (13B). Across language modeling, retrieval, and instruction-following benchmarks, HiCI yields consistent improvements over strong baselines, including matching proprietary models on topic retrieval and surpassing GPT-3.5-Turbo-16K on code comprehension. These results demonstrate the effectiveness of explicit hierarchical structuring as an inductive bias for long-context modeling.
RIVER: A Real-Time Interaction Benchmark for Video LLMs
Mar 04, 2026The rapid advancement of multimodal large language models has demonstrated impressive capabilities, yet nearly all operate in an offline paradigm, hindering real-time interactivity. Addressing this gap, we introduce the Real-tIme Video intERaction Bench (RIVER Bench), designed for evaluating online video comprehension. RIVER Bench introduces a novel framework comprising Retrospective Memory, Live-Perception, and Proactive Anticipation tasks, closely mimicking interactive dialogues rather than responding to entire videos at once. We conducted detailed annotations using videos from diverse sources and varying lengths, and precisely defined the real-time interactive format. Evaluations across various model categories reveal that while offline models perform well in single question-answering tasks, they struggle with real-time processing. Addressing the limitations of existing models in online video interaction, especially their deficiencies in long-term memory and future perception, we proposed a general improvement method that enables models to interact with users more flexibly in real time. We believe this work will significantly advance the development of real-time interactive video understanding models and inspire future research in this emerging field. Datasets and code are publicly available at https://github.com/OpenGVLab/RIVER.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Apr 10, 2025Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
Make Your Training Flexible: Towards Deployment-Efficient Video Models
Mar 18, 2025



Popular video training methods mainly operate on a fixed number of tokens sampled from a predetermined spatiotemporal grid, resulting in sub-optimal accuracy-computation trade-offs due to inherent video redundancy. They also lack adaptability to varying computational budgets for downstream tasks, hindering applications of the most competitive model in real-world scenes. We thus propose a new test setting, Token Optimization, for maximized input information across budgets, which optimizes the size-limited set of input tokens through token selection from more suitably sampled videos. To this end, we propose a novel augmentation tool termed Flux. By making the sampling grid flexible and leveraging token selection, it is easily adopted in most popular video training frameworks, boosting model robustness with nearly no additional cost. We integrate Flux in large-scale video pre-training, and the resulting FluxViT establishes new state-of-the-art results across extensive tasks at standard costs. Notably, with 1/4 tokens only, it can still match the performance of previous state-of-the-art models with Token Optimization, yielding nearly 90\% savings. All models and data are available at https://github.com/OpenGVLab/FluxViT.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025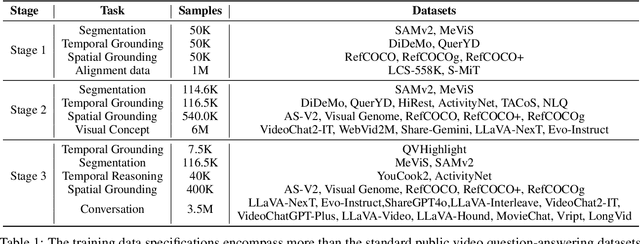
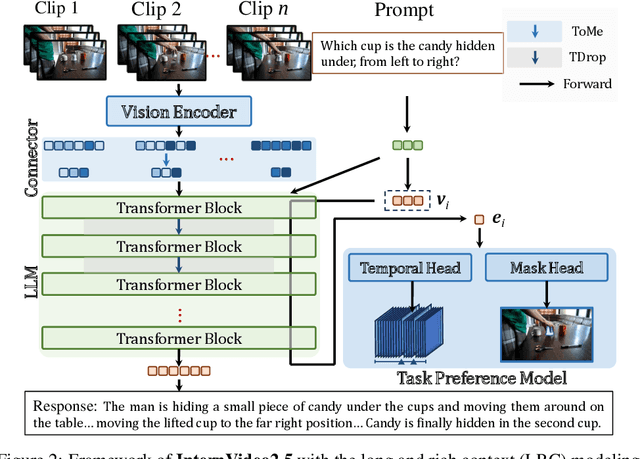
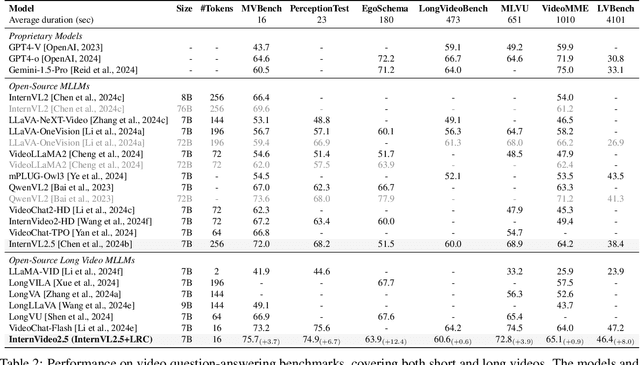
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024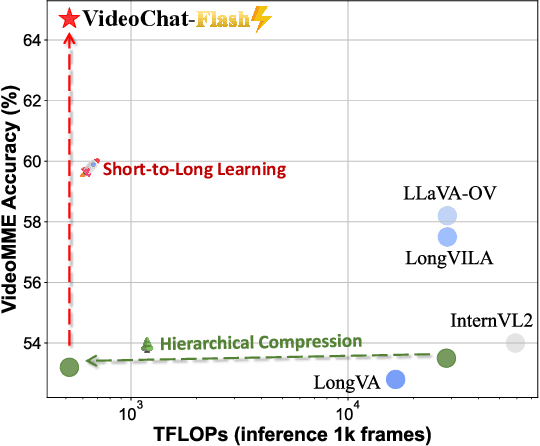
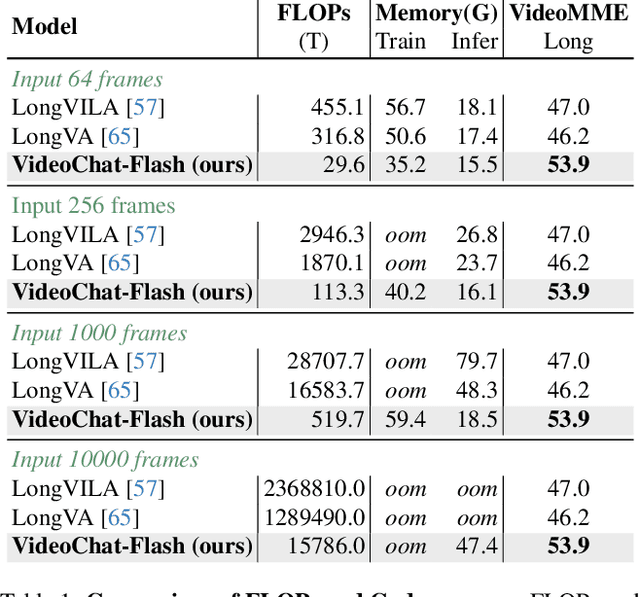

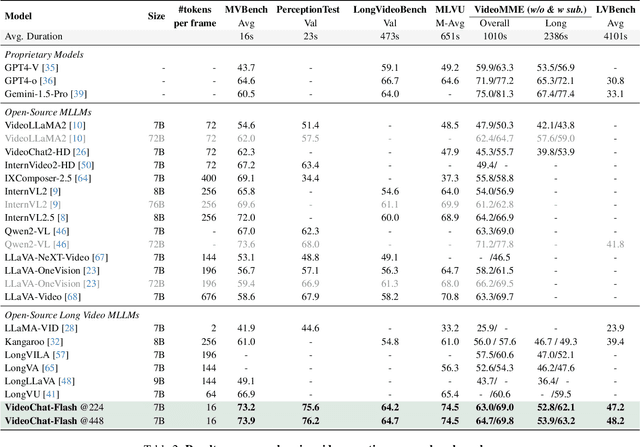
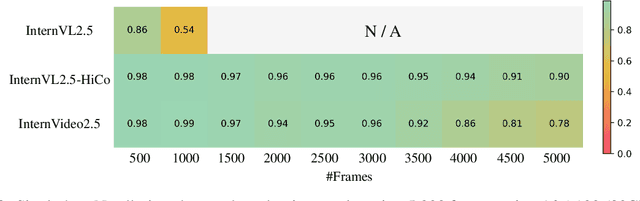
Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.