 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIVER: A Real-Time Interaction Benchmark for Video LLMs
Mar 04, 2026The rapid advancement of multimodal large language models has demonstrated impressive capabilities, yet nearly all operate in an offline paradigm, hindering real-time interactivity. Addressing this gap, we introduce the Real-tIme Video intERaction Bench (RIVER Bench), designed for evaluating online video comprehension. RIVER Bench introduces a novel framework comprising Retrospective Memory, Live-Perception, and Proactive Anticipation tasks, closely mimicking interactive dialogues rather than responding to entire videos at once. We conducted detailed annotations using videos from diverse sources and varying lengths, and precisely defined the real-time interactive format. Evaluations across various model categories reveal that while offline models perform well in single question-answering tasks, they struggle with real-time processing. Addressing the limitations of existing models in online video interaction, especially their deficiencies in long-term memory and future perception, we proposed a general improvement method that enables models to interact with users more flexibly in real time. We believe this work will significantly advance the development of real-time interactive video understanding models and inspire future research in this emerging field. Datasets and code are publicly available at https://github.com/OpenGVLab/RIVER.
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
May 22, 2025Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024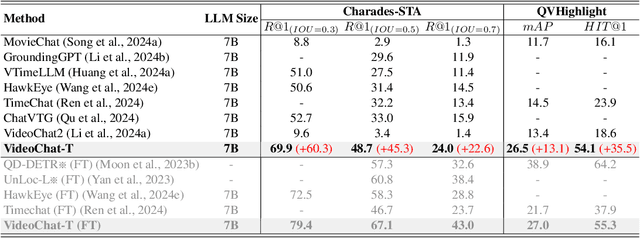
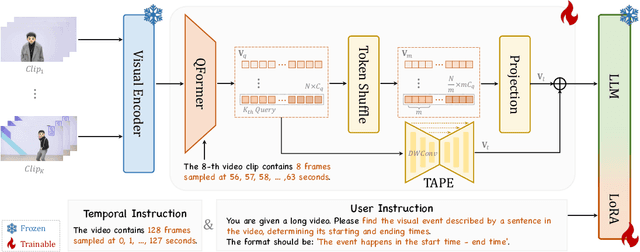
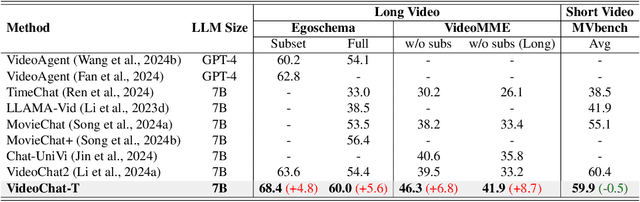
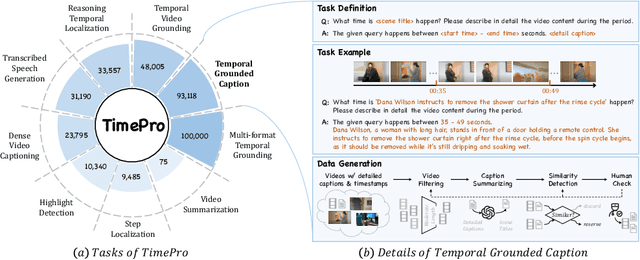
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
Collaboration and Transition: Distilling Item Transitions into Multi-Query Self-Attention for Sequential Recommendation
Nov 02, 2023



Modern recommender systems employ various sequential modules such as self-attention to learn dynamic user interests. However, these methods are less effective in capturing collaborative and transitional signals within user interaction sequences. First, the self-attention architecture uses the embedding of a single item as the attention query, which is inherently challenging to capture collaborative signals. Second, these methods typically follow an auto-regressive framework, which is unable to learn global item transition patterns. To overcome these limitations, we propose a new method called Multi-Query Self-Attention with Transition-Aware Embedding Distillation (MQSA-TED). First, we propose an $L$-query self-attention module that employs flexible window sizes for attention queries to capture collaborative signals. In addition, we introduce a multi-query self-attention method that balances the bias-variance trade-off in modeling user preferences by combining long and short-query self-attentions. Second, we develop a transition-aware embedding distillation module that distills global item-to-item transition patterns into item embeddings, which enables the model to memorize and leverage transitional signals and serves as a calibrator for collaborative signals. Experimental results on four real-world datasets show the superiority of our proposed method over state-of-the-art sequential recommendation methods.