 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-VAR: Image Segmentation with Visual Autoregressive Modeling
Nov 16, 2025While visual autoregressive modeling (VAR) strategies have shed light on image generation with the autoregressive models, their potential for segmentation, a task that requires precise low-level spatial perception, remains unexplored. Inspired by the multi-scale modeling of classic Mask2Former-based models, we propose Seg-VAR, a novel framework that rethinks segmentation as a conditional autoregressive mask generation problem. This is achieved by replacing the discriminative learning with the latent learning process. Specifically, our method incorporates three core components: (1) an image encoder generating latent priors from input images, (2) a spatial-aware seglat (a latent expression of segmentation mask) encoder that maps segmentation masks into discrete latent tokens using a location-sensitive color mapping to distinguish instances, and (3) a decoder reconstructing masks from these latents. A multi-stage training strategy is introduced: first learning seglat representations via image-seglat joint training, then refining latent transformations, and finally aligning image-encoder-derived latents with seglat distributions. Experiments show Seg-VAR outperforms previous discriminative and generative methods on various segmentation tasks and validation benchmarks. By framing segmentation as a sequential hierarchical prediction task, Seg-VAR opens new avenues for integrating autoregressive reasoning into spatial-aware vision systems. Code will be available at https://github.com/rkzheng99/Seg-VAR.
SyncVIS: Synchronized Video Instance Segmentation
Dec 01, 2024



Recent DETR-based methods have advanced the development of Video Instance Segmentation (VIS) through transformers' efficiency and capability in modeling spatial and temporal information. Despite harvesting remarkable progress, existing works follow asynchronous designs, which model video sequences via either video-level queries only or adopting query-sensitive cascade structures, resulting in difficulties when handling complex and challenging video scenarios. In this work, we analyze the cause of this phenomenon and the limitations of the current solutions, and propose to conduct synchronized modeling via a new framework named SyncVIS. Specifically, SyncVIS explicitly introduces video-level query embeddings and designs two key modules to synchronize video-level query with frame-level query embeddings: a synchronized video-frame modeling paradigm and a synchronized embedding optimization strategy. The former attempts to promote the mutual learning of frame- and video-level embeddings with each other and the latter divides large video sequences into small clips for easier optimization. Extensive experimental evaluations are conducted on the challenging YouTube-VIS 2019 & 2021 & 2022, and OVIS benchmarks and SyncVIS achieves state-of-the-art results, which demonstrates the effectiveness and generality of the proposed approach. The code is available at https://github.com/rkzheng99/SyncVIS.
ViLLa: Video Reasoning Segmentation with Large Language Model
Jul 18, 2024
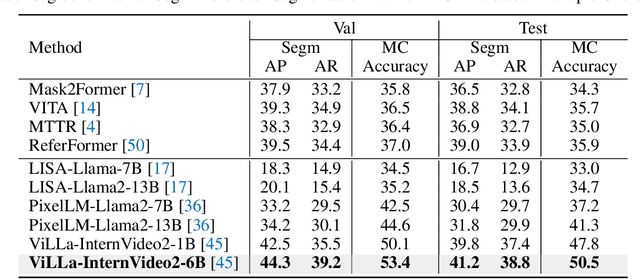
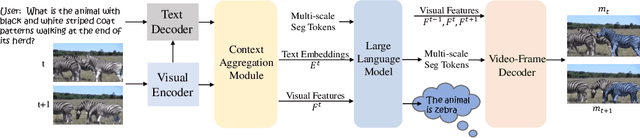
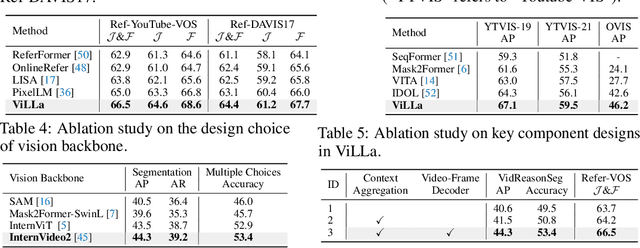
Although video perception models have made remarkable advancements in recent years, they still heavily rely on explicit text descriptions or pre-defined categories to identify target instances before executing video perception tasks. These models, however, fail to proactively comprehend and reason the user's intentions via textual input. Even though previous works attempt to investigate solutions to incorporate reasoning with image segmentation, they fail to reason with videos due to the video's complexity in object motion. To bridge the gap between image and video, in this work, we propose a new video segmentation task - video reasoning segmentation. The task is designed to output tracklets of segmentation masks given a complex input text query. What's more, to promote research in this unexplored area, we construct a reasoning video segmentation benchmark. Finally, we present ViLLa: Video reasoning segmentation with a Large Language Model, which incorporates the language generation capabilities of multimodal Large Language Models (LLMs) while retaining the capabilities of detecting, segmenting, and tracking multiple instances. We use a temporal-aware context aggregation module to incorporate contextual visual cues to text embeddings and propose a video-frame decoder to build temporal correlations across segmentation tokens. Remarkably, our ViLLa demonstrates capability in handling complex reasoning and referring video segmentation. Also, our model shows impressive ability in different temporal understanding benchmarks. Both quantitative and qualitative experiments show our method effectively unlocks new video reasoning segmentation capabilities for multimodal LLMs. The code and dataset will be available at https://github.com/rkzheng99/ViLLa.
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
TMT-VIS: Taxonomy-aware Multi-dataset Joint Training for Video Instance Segmentation
Dec 12, 2023
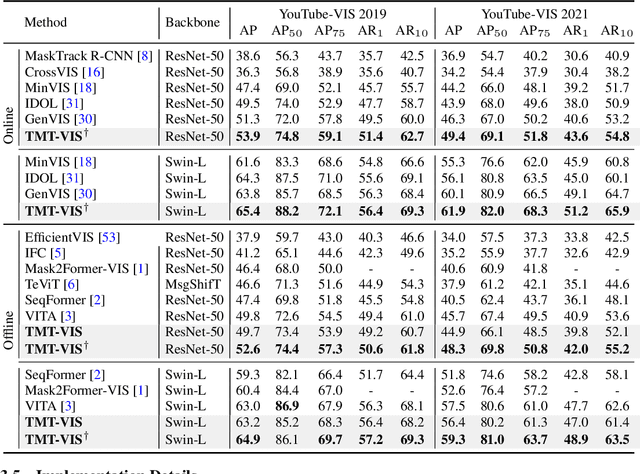
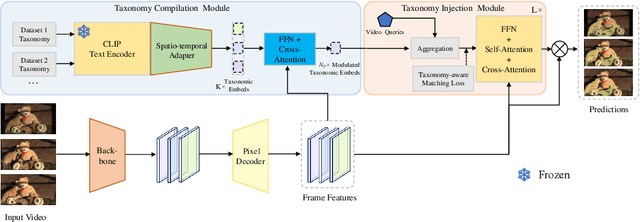
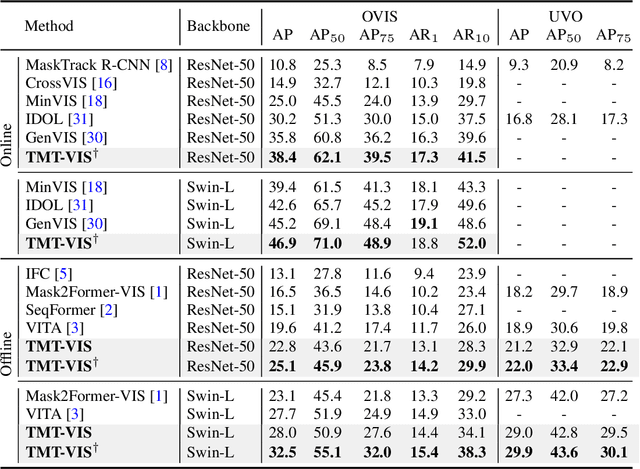
Training on large-scale datasets can boost the performance of video instance segmentation while the annotated datasets for VIS are hard to scale up due to the high labor cost. What we possess are numerous isolated filed-specific datasets, thus, it is appealing to jointly train models across the aggregation of datasets to enhance data volume and diversity. However, due to the heterogeneity in category space, as mask precision increases with the data volume, simply utilizing multiple datasets will dilute the attention of models on different taxonomies. Thus, increasing the data scale and enriching taxonomy space while improving classification precision is important. In this work, we analyze that providing extra taxonomy information can help models concentrate on specific taxonomy, and propose our model named Taxonomy-aware Multi-dataset Joint Training for Video Instance Segmentation (TMT-VIS) to address this vital challenge. Specifically, we design a two-stage taxonomy aggregation module that first compiles taxonomy information from input videos and then aggregates these taxonomy priors into instance queries before the transformer decoder. We conduct extensive experimental evaluations on four popular and challenging benchmarks, including YouTube-VIS 2019, YouTube-VIS 2021, OVIS, and UVO. Our model shows significant improvement over the baseline solutions, and sets new state-of-the-art records on all benchmarks. These appealing and encouraging results demonstrate the effectiveness and generality of our approach. The code is available at https://github.com/rkzheng99/TMT-VIS(https://github.com/rkzheng99/TMT-VIS)