 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLLa: Video Reasoning Segmentation with Large Language Model
Paper and Code

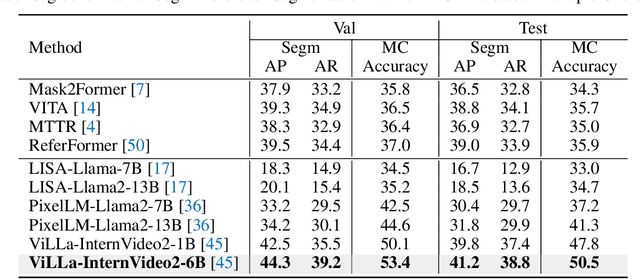
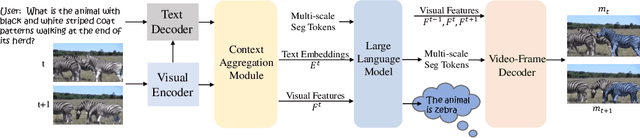
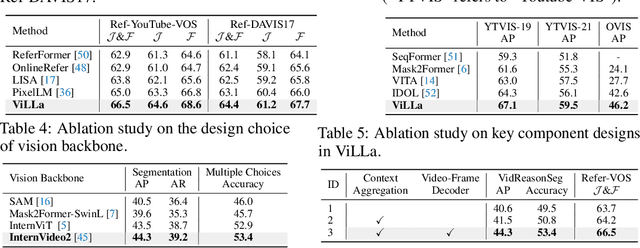
Although video perception models have made remarkable advancements in recent years, they still heavily rely on explicit text descriptions or pre-defined categories to identify target instances before executing video perception tasks. These models, however, fail to proactively comprehend and reason the user's intentions via textual input. Even though previous works attempt to investigate solutions to incorporate reasoning with image segmentation, they fail to reason with videos due to the video's complexity in object motion. To bridge the gap between image and video, in this work, we propose a new video segmentation task - video reasoning segmentation. The task is designed to output tracklets of segmentation masks given a complex input text query. What's more, to promote research in this unexplored area, we construct a reasoning video segmentation benchmark. Finally, we present ViLLa: Video reasoning segmentation with a Large Language Model, which incorporates the language generation capabilities of multimodal Large Language Models (LLMs) while retaining the capabilities of detecting, segmenting, and tracking multiple instances. We use a temporal-aware context aggregation module to incorporate contextual visual cues to text embeddings and propose a video-frame decoder to build temporal correlations across segmentation tokens. Remarkably, our ViLLa demonstrates capability in handling complex reasoning and referring video segmentation. Also, our model shows impressive ability in different temporal understanding benchmarks. Both quantitative and qualitative experiments show our method effectively unlocks new video reasoning segmentation capabilities for multimodal LLMs. The code and dataset will be available at https://github.com/rkzheng99/ViLLa.