 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROI-based Deep Image Compression with Implicit Bit Allocation
Nov 12, 2025Region of Interest (ROI)-based image compression has rapidly developed due to its ability to maintain high fidelity in important regions while reducing data redundancy. However, existing compression methods primarily apply masks to suppress background information before quantization. This explicit bit allocation strategy, which uses hard gating, significantly impacts the statistical distribution of the entropy model, thereby limiting the coding performance of the compression model. In response, this work proposes an efficient ROI-based deep image compression model with implicit bit allocation. To better utilize ROI masks for implicit bit allocation, this paper proposes a novel Mask-Guided Feature Enhancement (MGFE) module, comprising a Region-Adaptive Attention (RAA) block and a Frequency-Spatial Collaborative Attention (FSCA) block. This module allows for flexible bit allocation across different regions while enhancing global and local features through frequencyspatial domain collaboration. Additionally, we use dual decoders to separately reconstruct foreground and background images, enabling the coding network to optimally balance foreground enhancement and background quality preservation in a datadriven manner. To the best of our knowledge, this is the first work to utilize implicit bit allocation for high-quality regionadaptive coding. Experiments on the COCO2017 dataset show that our implicit-based image compression method significantly outperforms explicit bit allocation approaches in rate-distortion performance, achieving optimal results while maintaining satisfactory visual quality in the reconstructed background regions.
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO
Convex Combination Consistency between Neighbors for Weakly-supervised Action Localization
May 01, 2022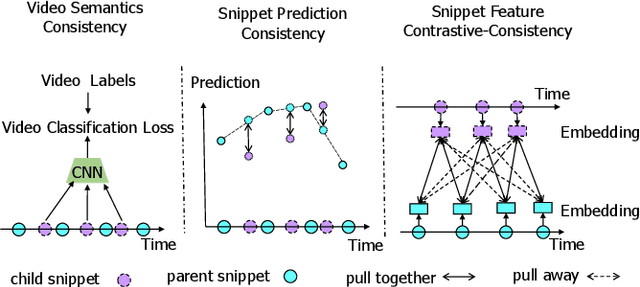
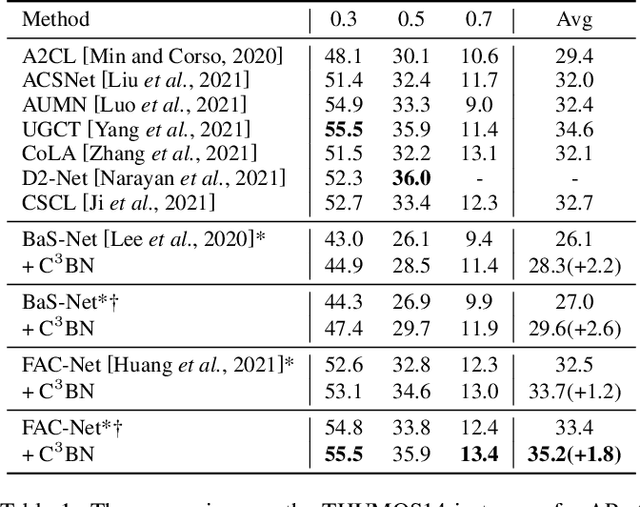
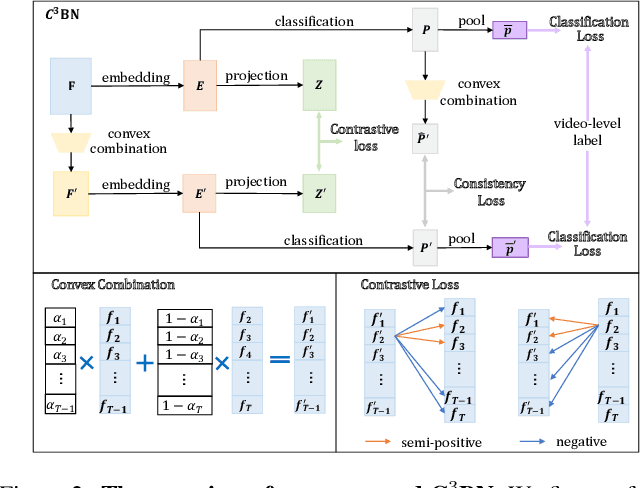
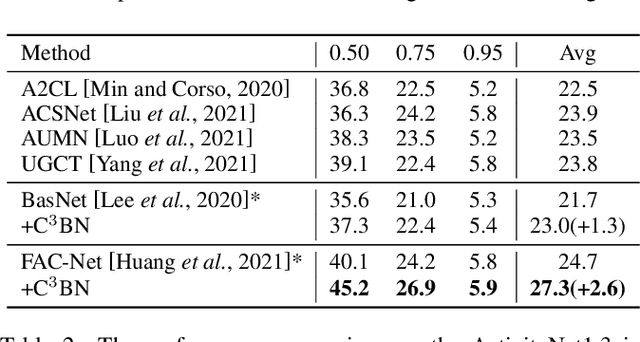
In weakly-supervised temporal action localization (WS-TAL), the methods commonly follow the "localization by classification" procedure, which uses the snippet predictions to form video class scores and then optimizes a video classification loss. In this procedure, the snippet predictions (or snippet attention weights) are used to separate foreground and background. However, the snippet predictions are usually inaccurate due to absence of frame-wise labels, and then the overall performance is hindered. In this paper, we propose a novel C$^3$BN to achieve robust snippet predictions. C$^3$BN includes two key designs by exploring the inherent characteristics of video data. First, because of the natural continuity of adjacent snippets, we propose a micro data augmentation strategy to increase the diversity of snippets with convex combination of adjacent snippets. Second, we propose a macro-micro consistency regularization strategy to force the model to be invariant (or equivariant) to the transformations of snippets with respect to video semantics, snippet predictions and snippet features. Experimental results demonstrate the effectiveness of our proposed method on top of baselines for the WS-TAL tasks with video-level and point-level supervision.