 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Combination Consistency between Neighbors for Weakly-supervised Action Localization
Paper and Code
May 01, 2022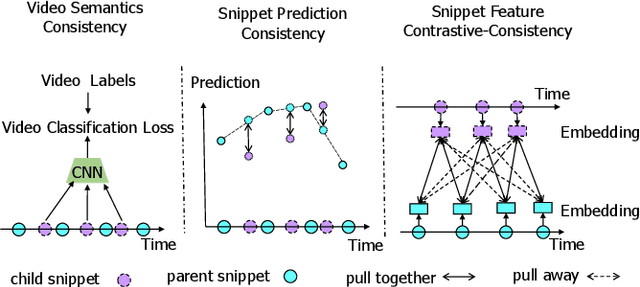
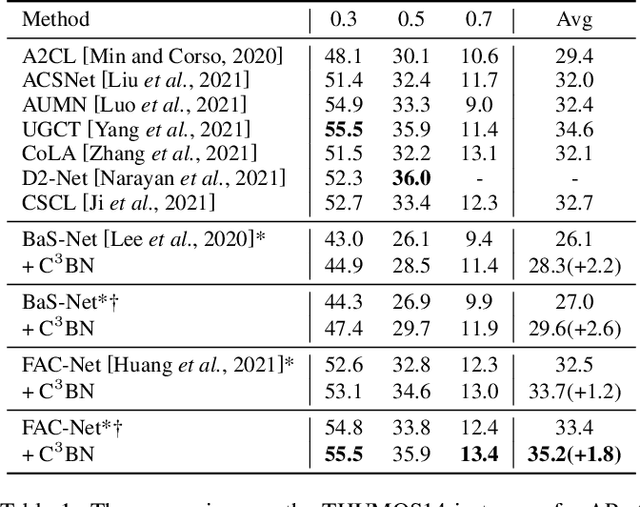
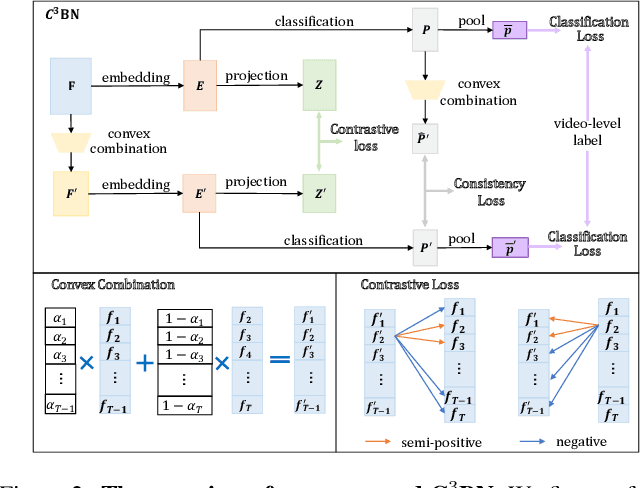
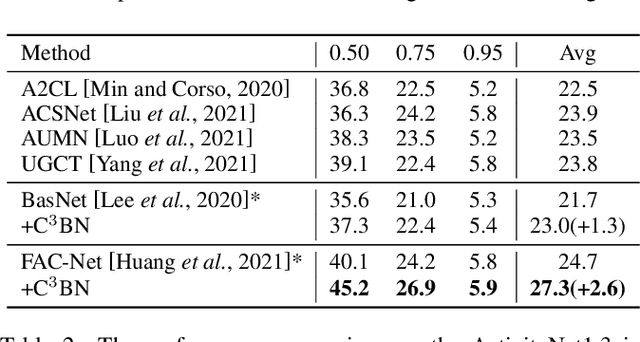
In weakly-supervised temporal action localization (WS-TAL), the methods commonly follow the "localization by classification" procedure, which uses the snippet predictions to form video class scores and then optimizes a video classification loss. In this procedure, the snippet predictions (or snippet attention weights) are used to separate foreground and background. However, the snippet predictions are usually inaccurate due to absence of frame-wise labels, and then the overall performance is hindered. In this paper, we propose a novel C$^3$BN to achieve robust snippet predictions. C$^3$BN includes two key designs by exploring the inherent characteristics of video data. First, because of the natural continuity of adjacent snippets, we propose a micro data augmentation strategy to increase the diversity of snippets with convex combination of adjacent snippets. Second, we propose a macro-micro consistency regularization strategy to force the model to be invariant (or equivariant) to the transformations of snippets with respect to video semantics, snippet predictions and snippet features. Experimental results demonstrate the effectiveness of our proposed method on top of baselines for the WS-TAL tasks with video-level and point-level supervision.