 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Context-Aware Human Preferences for Multi-Objective Robot Navigation
Mar 18, 2026Robots operating in human-shared environments must not only achieve task-level navigation objectives such as safety and efficiency, but also adapt their behavior to human preferences. However, as human preferences are typically expressed in natural language and depend on environmental context, it is difficult to directly integrate them into low-level robot control policies. In this work, we present a pipeline that enables robots to understand and apply context-dependent navigation preferences by combining foundational models with a Multi-Objective Reinforcement Learning (MORL) navigation policy. Thus, our approach integrates high-level semantic reasoning with low-level motion control. A Vision-Language Model (VLM) extracts structured environmental context from onboard visual observations, while Large Language Models (LLM) convert natural language user feedback into interpretable, context-dependent behavioral rules stored in a persistent but updatable rule memory. A preference translation module then maps contextual information and stored rules into numerical preference vectors that parameterize a pretrained MORL policy for real-time navigation adaptation. We evaluate the proposed framework through quantitative component-level evaluations, a user study, and real-world robot deployments in various indoor environments. Our results demonstrate that the system reliably captures user intent, generates consistent preference vectors, and enables controllable behavior adaptation across diverse contexts. Overall, the proposed pipeline improves the adaptability, transparency, and usability of robots operating in shared human environments, while maintaining safe and responsive real-time control.
Auditory Localization and Assessment of Consequential Robot Sounds: A Multi-Method Study in Virtual Reality
Apr 01, 2025Mobile robots increasingly operate alongside humans but are often out of sight, so that humans need to rely on the sounds of the robots to recognize their presence. For successful human-robot interaction (HRI), it is therefore crucial to understand how humans perceive robots by their consequential sounds, i.e., operating noise. Prior research suggests that the sound of a quadruped Go1 is more detectable than that of a wheeled Turtlebot. This study builds on this and examines the human ability to localize consequential sounds of three robots (quadruped Go1, wheeled Turtlebot 2i, wheeled HSR) in Virtual Reality. In a within-subjects design, we assessed participants' localization performance for the robots with and without an acoustic vehicle alerting system (AVAS) for two velocities (0.3, 0.8 m/s) and two trajectories (head-on, radial). In each trial, participants were presented with the sound of a moving robot for 3~s and were tasked to point at its final position (localization task). Localization errors were measured as the absolute angular difference between the participants' estimated and the actual robot position. Results showed that the robot type significantly influenced the localization accuracy and precision, with the sound of the wheeled HSR (especially without AVAS) performing worst under all experimental conditions. Surprisingly, participants rated the HSR sound as more positive, less annoying, and more trustworthy than the Turtlebot and Go1 sound. This reveals a tension between subjective evaluation and objective auditory localization performance. Our findings highlight consequential robot sounds as a critical factor for designing intuitive and effective HRI, with implications for human-centered robot design and social navigation.
Immersive Explainability: Visualizing Robot Navigation Decisions through XAI Semantic Scene Projections in Virtual Reality
Apr 01, 2025End-to-end robot policies achieve high performance through neural networks trained via reinforcement learning (RL). Yet, their black box nature and abstract reasoning pose challenges for human-robot interaction (HRI), because humans may experience difficulty in understanding and predicting the robot's navigation decisions, hindering trust development. We present a virtual reality (VR) interface that visualizes explainable AI (XAI) outputs and the robot's lidar perception to support intuitive interpretation of RL-based navigation behavior. By visually highlighting objects based on their attribution scores, the interface grounds abstract policy explanations in the scene context. This XAI visualization bridges the gap between obscure numerical XAI attribution scores and a human-centric semantic level of explanation. A within-subjects study with 24 participants evaluated the effectiveness of our interface for four visualization conditions combining XAI and lidar. Participants ranked scene objects across navigation scenarios based on their importance to the robot, followed by a questionnaire assessing subjective understanding and predictability. Results show that semantic projection of attributions significantly enhances non-expert users' objective understanding and subjective awareness of robot behavior. In addition, lidar visualization further improves perceived predictability, underscoring the value of integrating XAI and sensor for transparent, trustworthy HRI.
Constrained Object Placement Using Reinforcement Learning
Apr 16, 2024
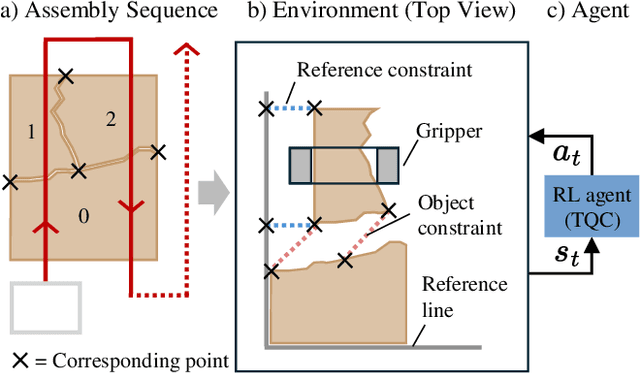
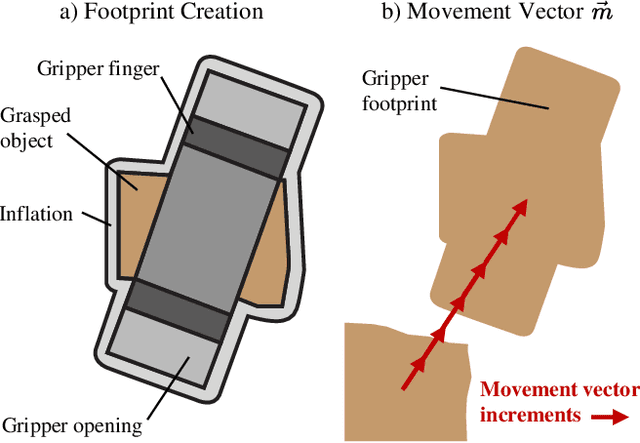
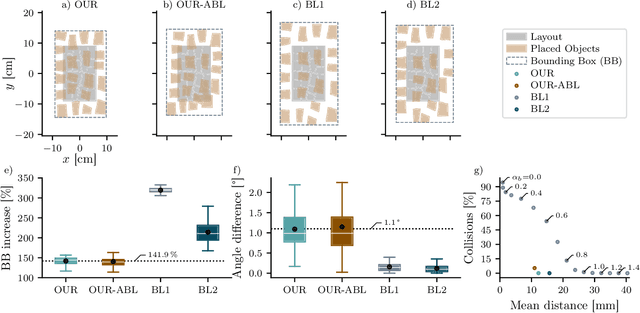
Close and precise placement of irregularly shaped objects requires a skilled robotic system. Particularly challenging is the manipulation of objects that have sensitive top surfaces and a fixed set of neighbors. To avoid damaging the surface, they have to be grasped from the side, and during placement, their neighbor relations have to be maintained. In this work, we train a reinforcement learning agent that generates smooth end-effector motions to place objects as close as possible next to each other. During the placement, our agent considers neighbor constraints defined in a given layout of the objects while trying to avoid collisions. Our approach learns to place compact object assemblies without the need for predefined spacing between objects as required by traditional methods. We thoroughly evaluated our approach using a two-finger gripper mounted to a robotic arm with six degrees of freedom. The results show that our agent outperforms two baseline approaches in terms of object assembly compactness, thereby reducing the needed space to place the objects according to the given neighbor constraints. On average, our approach reduces the distances between all placed objects by at least 60%, with fewer collisions at the same compactness compared to both baselines.
Learning Adaptive Multi-Objective Robot Navigation with Demonstrations
Apr 12, 2024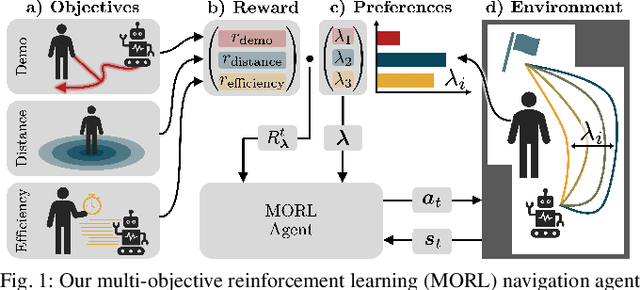
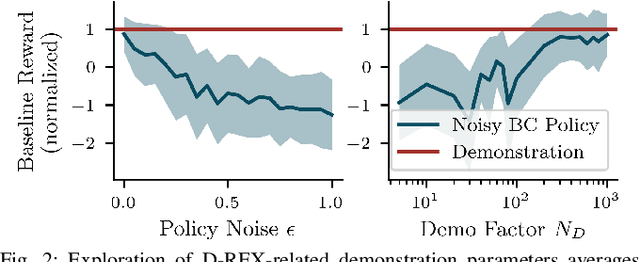
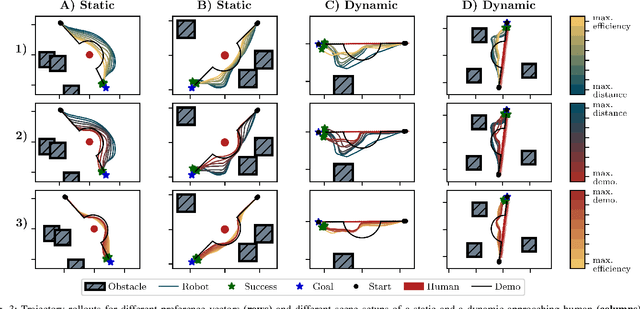
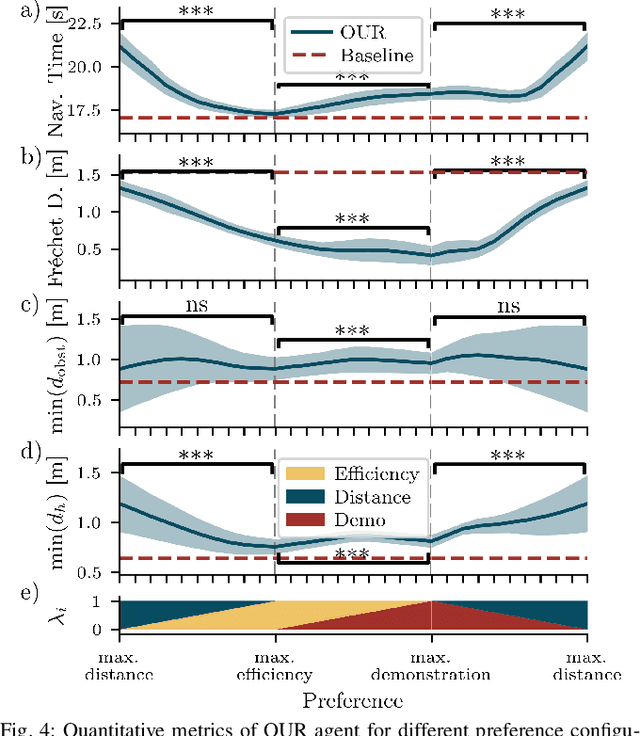
Preference-aligned robot navigation in human environments is typically achieved through learning-based approaches, utilizing demonstrations and user feedback for personalization. However, personal preferences are subject to change and might even be context-dependent. Yet traditional reinforcement learning (RL) approaches with a static reward function often fall short in adapting to these varying user preferences. This paper introduces a framework that combines multi-objective reinforcement learning (MORL) with demonstration-based learning. Our approach allows for dynamic adaptation to changing user preferences without retraining. Through rigorous evaluations, including sim-to-real and robot-to-robot transfers, we demonstrate our framework's capability to reflect user preferences accurately while achieving high navigational performance in terms of collision avoidance and goal pursuance.
Sound Matters: Auditory Detectability of Mobile Robots
Apr 10, 2024



Mobile robots are increasingly being used in noisy environments for social purposes, e.g. to provide support in healthcare or public spaces. Since these robots also operate beyond human sight, the question arises as to how different robot types, ambient noise or cognitive engagement impacts the detection of the robots by their sound. To address this research gap, we conducted a user study measuring auditory detection distances for a wheeled (Turtlebot 2i) and quadruped robot (Unitree Go 1), which emit different consequential sounds when moving. Additionally, we also manipulated background noise levels and participants' engagement in a secondary task during the study. Our results showed that the quadruped robot sound was detected significantly better (i.e., at a larger distance) than the wheeled one, which demonstrates that the movement mechanism has a meaningful impact on the auditory detectability. The detectability for both robots diminished significantly as background noise increased. But even in high background noise, participants detected the quadruped robot at a significantly larger distance. The engagement in a secondary task had hardly any impact. In essence, these findings highlight the critical role of distinguishing auditory characteristics of different robots to improve the smooth human-centered navigation of mobile robots in noisy environments.
EnQuery: Ensemble Policies for Diverse Query-Generation in Preference Alignment of Robot Navigation
Apr 07, 2024



To align mobile robot navigation policies with user preferences through reinforcement learning from human feedback (RLHF), reliable and behavior-diverse user queries are required. However, deterministic policies fail to generate a variety of navigation trajectory suggestions for a given navigation task configuration. We introduce EnQuery, a query generation approach using an ensemble of policies that achieve behavioral diversity through a regularization term. For a given navigation task, EnQuery produces multiple navigation trajectory suggestions, thereby optimizing the efficiency of preference data collection with fewer queries. Our methodology demonstrates superior performance in aligning navigation policies with user preferences in low-query regimes, offering enhanced policy convergence from sparse preference queries. The evaluation is complemented with a novel explainability representation, capturing full scene navigation behavior of the mobile robot in a single plot.
RHINO-VR Experience: Teaching Mobile Robotics Concepts in an Interactive Museum Exhibit
Mar 22, 2024



In 1997, the very first tour guide robot RHINO was deployed in a museum in Germany. With the ability to navigate autonomously through the environment, the robot gave tours to over 2,000 visitors. Today, RHINO itself has become an exhibit and is no longer operational. In this paper, we present RHINO-VR, an interactive museum exhibit using virtual reality (VR) that allows museum visitors to experience the historical robot RHINO in operation in a virtual museum. RHINO-VR, unlike static exhibits, enables users to familiarize themselves with basic mobile robotics concepts without the fear of damaging the exhibit. In the virtual environment, the user is able to interact with RHINO in VR by pointing to a location to which the robot should navigate and observing the corresponding actions of the robot. To include other visitors who cannot use the VR, we provide an external observation view to make RHINO visible to them. We evaluated our system by measuring the frame rate of the VR simulation, comparing the generated virtual 3D models with the originals, and conducting a user study. The user-study showed that RHINO-VR improved the visitors' understanding of the robot's functionality and that they would recommend experiencing the VR exhibit to others.
Spatiotemporal Attention Enhances Lidar-Based Robot Navigation in Dynamic Environments
Oct 30, 2023Foresighted robot navigation in dynamic indoor environments with cost-efficient hardware necessitates the use of a lightweight yet dependable controller. So inferring the scene dynamics from sensor readings without explicit object tracking is a pivotal aspect of foresighted navigation among pedestrians. In this paper, we introduce a spatiotemporal attention pipeline for enhanced navigation based on 2D lidar sensor readings. This pipeline is complemented by a novel lidar-state representation that emphasizes dynamic obstacles over static ones. Subsequently, the attention mechanism enables selective scene perception across both space and time, resulting in improved overall navigation performance within dynamic scenarios. We thoroughly evaluated the approach in different scenarios and simulators, finding good generalization to unseen environments. The results demonstrate outstanding performance compared to state-of-the-art methods, thereby enabling the seamless deployment of the learned controller on a real robot.
Subgoal-Driven Navigation in Dynamic Environments Using Attention-Based Deep Reinforcement Learning
Mar 02, 2023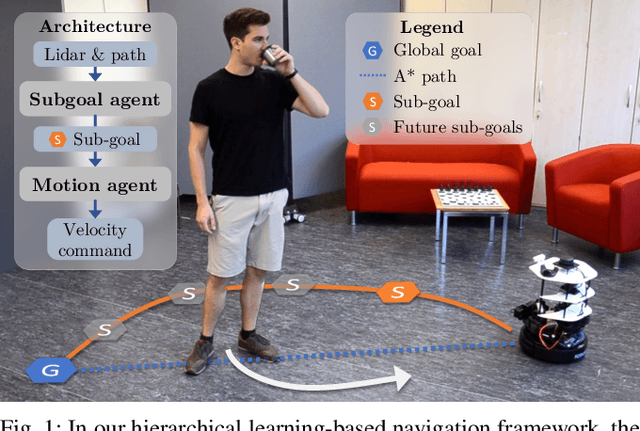
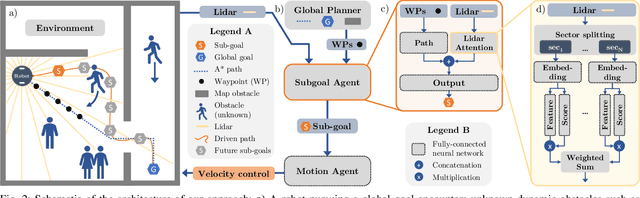
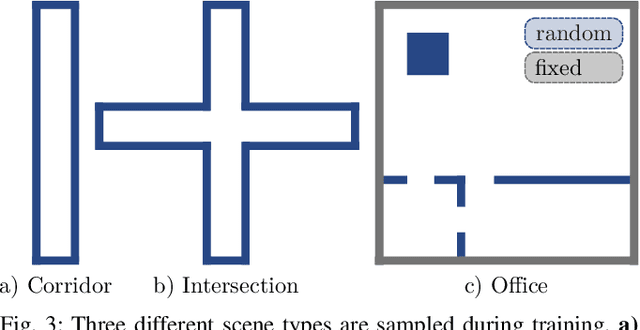
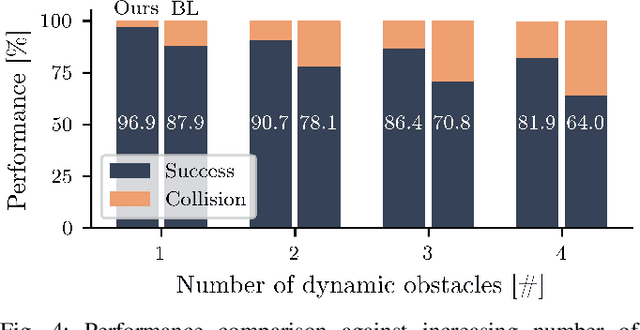
Collision-free, goal-directed navigation in environments containing unknown static and dynamic obstacles is still a great challenge, especially when manual tuning of navigation policies or costly motion prediction needs to be avoided. In this paper, we therefore propose a subgoal-driven hierarchical navigation architecture that is trained with deep reinforcement learning and decouples obstacle avoidance and motor control. In particular, we separate the navigation task into the prediction of the next subgoal position for avoiding collisions while moving toward the final target position, and the prediction of the robot's velocity controls. By relying on 2D lidar, our method learns to avoid obstacles while still achieving goal-directed behavior as well as to generate low-level velocity control commands to reach the subgoals. In our architecture, we apply the attention mechanism on the robot's 2D lidar readings and compute the importance of lidar scan segments for avoiding collisions. As we show in simulated and real-world experiments with a Turtlebot robot, our proposed method leads to smooth and safe trajectories among humans and significantly outperforms a state-of-the-art approach in terms of success rate. A supplemental video describing our approach is available online.