 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Multi-Objective Robot Navigation with Demonstrations
Paper and Code
Apr 12, 2024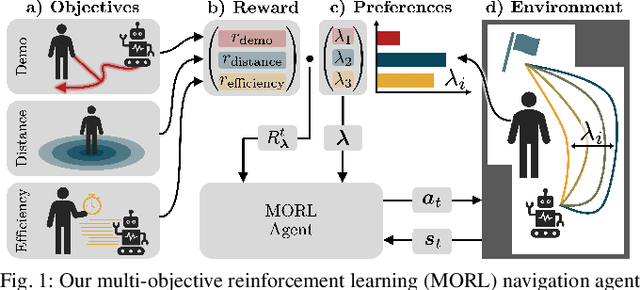
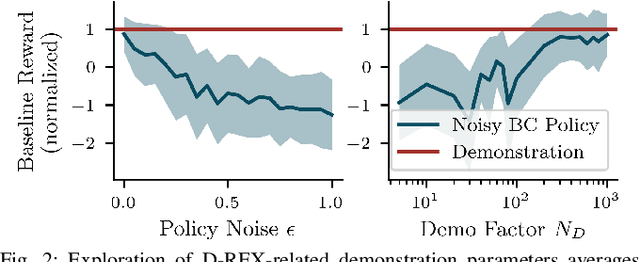
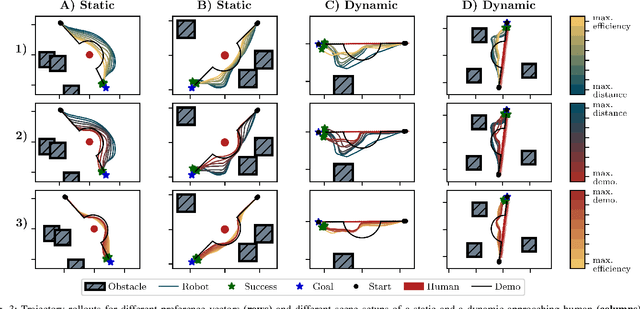
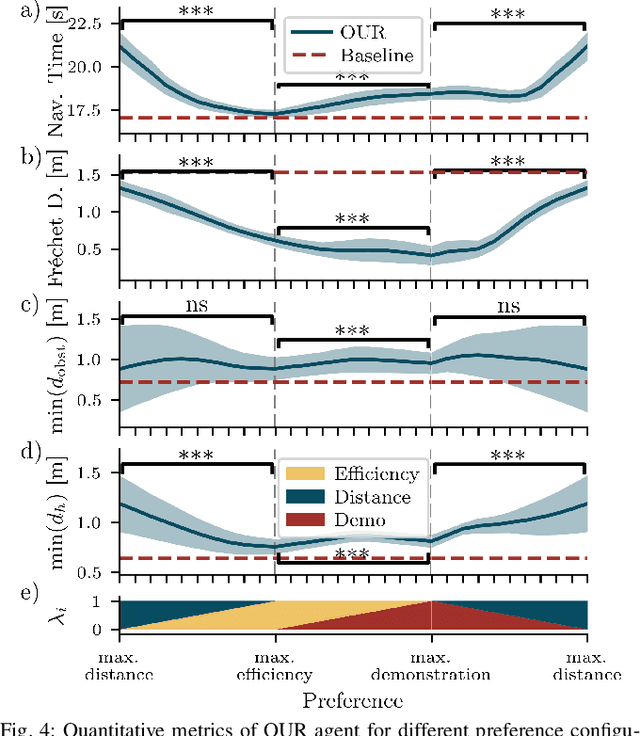
Preference-aligned robot navigation in human environments is typically achieved through learning-based approaches, utilizing demonstrations and user feedback for personalization. However, personal preferences are subject to change and might even be context-dependent. Yet traditional reinforcement learning (RL) approaches with a static reward function often fall short in adapting to these varying user preferences. This paper introduces a framework that combines multi-objective reinforcement learning (MORL) with demonstration-based learning. Our approach allows for dynamic adaptation to changing user preferences without retraining. Through rigorous evaluations, including sim-to-real and robot-to-robot transfers, we demonstrate our framework's capability to reflect user preferences accurately while achieving high navigational performance in terms of collision avoidance and goal pursuance.