 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiG-Avatar: Hierarchical Neural-Field-Guided Gaussian Avatars
May 20, 2026Existing Gaussian avatar methods typically parameterize geometry on a body-template surface, which entangles the avatar's representation space with the template's deformation space and limits the capture of layered, off-body, and non-rigid clothing geometry. We present PiG-Avatar, which addresses this limitation by using the parametric body model solely for kinematic transport, while representing the avatar as Gaussians anchored in a volumetric canonical space governed by a continuous neural field. This decouples representation from template topology, avoiding the geometric constraints of surface-based parameterizations. Kinematic coherence is maintained through 3D barycentric anchor transport, which guides motion without constraining geometry and allows anchors to deviate freely from the template surface, yielding dense, stable temporal surface correspondences by construction. To make this unconstrained formulation tractable, we introduce dual-level spatially coherent optimization, combining Sobolev-preconditioned neural-field updates with a novel KNN-based preconditioning of canonical anchor geometry. Together, these mechanisms induce an emergent self-organization of anchor density: anchors migrate toward regions of high curvature, appearance variation, and non-coherent motion without explicit heuristics. As a result, complex clothing geometry and layered surfaces emerge as natural, high-fidelity outputs. This single representation further supports hierarchical reconstruction across multiple levels of detail, with coarse-level supervision propagating to finer levels through the shared field and coupled anchor graph. On established benchmarks featuring subjects with complex clothing and challenging non-rigid motion, PiG-Avatar achieves state-of-the-art rendering quality, generalizes robustly to imperfect body model initialization, and renders in real time across all detail levels.
Transformer-Based Inpainting for Real-Time 3D Streaming in Sparse Multi-Camera Setups
Mar 05, 2026High-quality 3D streaming from multiple cameras is crucial for immersive experiences in many AR/VR applications. The limited number of views - often due to real-time constraints - leads to missing information and incomplete surfaces in the rendered images. Existing approaches typically rely on simple heuristics for the hole filling, which can result in inconsistencies or visual artifacts. We propose to complete the missing textures using a novel, application-targeted inpainting method independent of the underlying representation as an image-based post-processing step after the novel view rendering. The method is designed as a standalone module compatible with any calibrated multi-camera system. For this we introduce a multi-view aware, transformer-based network architecture using spatio-temporal embeddings to ensure consistency across frames while preserving fine details. Additionally, our resolution-independent design allows adaptation to different camera setups, while an adaptive patch selection strategy balances inference speed and quality, allowing real-time performance. We evaluate our approach against state-of-the-art inpainting techniques under the same real-time constraints and demonstrate that our model achieves the best trade-off between quality and speed, outperforming competitors in both image and video-based metrics.
Neu-PiG: Neural Preconditioned Grids for Fast Dynamic Surface Reconstruction on Long Sequences
Feb 25, 2026Temporally consistent surface reconstruction of dynamic 3D objects from unstructured point cloud data remains challenging, especially for very long sequences. Existing methods either optimize deformations incrementally, risking drift and requiring long runtimes, or rely on complex learned models that demand category-specific training. We present Neu-PiG, a fast deformation optimization method based on a novel preconditioned latent-grid encoding that distributes spatial features parameterized on the position and normal direction of a keyframe surface. Our method encodes entire deformations across all time steps at various spatial scales into a multi-resolution latent grid, parameterized by the position and normal direction of a reference surface from a single keyframe. This latent representation is then augmented for time modulation and decoded into per-frame 6-DoF deformations via a lightweight multilayer perceptron (MLP). To achieve high-fidelity, drift-free surface reconstructions in seconds, we employ Sobolev preconditioning during gradient-based training of the latent space, completely avoiding the need for any explicit correspondences or further priors. Experiments across diverse human and animal datasets demonstrate that Neu-PiG outperforms state-the-art approaches, offering both superior accuracy and scalability to long sequences while running at least 60x faster than existing training-free methods and achieving inference speeds on the same order as heavy pretrained models.
Moment-Based 3D Gaussian Splatting: Resolving Volumetric Occlusion with Order-Independent Transmittance
Dec 12, 2025
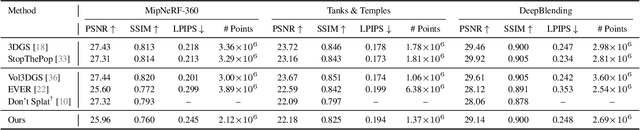

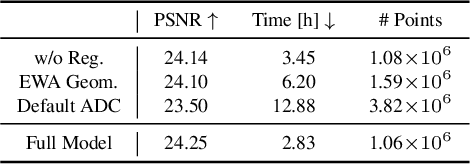
The recent success of 3D Gaussian Splatting (3DGS) has reshaped novel view synthesis by enabling fast optimization and real-time rendering of high-quality radiance fields. However, it relies on simplified, order-dependent alpha blending and coarse approximations of the density integral within the rasterizer, thereby limiting its ability to render complex, overlapping semi-transparent objects. In this paper, we extend rasterization-based rendering of 3D Gaussian representations with a novel method for high-fidelity transmittance computation, entirely avoiding the need for ray tracing or per-pixel sample sorting. Building on prior work in moment-based order-independent transparency, our key idea is to characterize the density distribution along each camera ray with a compact and continuous representation based on statistical moments. To this end, we analytically derive and compute a set of per-pixel moments from all contributing 3D Gaussians. From these moments, a continuous transmittance function is reconstructed for each ray, which is then independently sampled within each Gaussian. As a result, our method bridges the gap between rasterization and physical accuracy by modeling light attenuation in complex translucent media, significantly improving overall reconstruction and rendering quality.
SAFT: Shape and Appearance of Fabrics from Template via Differentiable Physical Simulations from Monocular Video
Sep 10, 2025The reconstruction of three-dimensional dynamic scenes is a well-established yet challenging task within the domain of computer vision. In this paper, we propose a novel approach that combines the domains of 3D geometry reconstruction and appearance estimation for physically based rendering and present a system that is able to perform both tasks for fabrics, utilizing only a single monocular RGB video sequence as input. In order to obtain realistic and high-quality deformations and renderings, a physical simulation of the cloth geometry and differentiable rendering are employed. In this paper, we introduce two novel regularization terms for the 3D reconstruction task that improve the plausibility of the reconstruction by addressing the depth ambiguity problem in monocular video. In comparison with the most recent methods in the field, we have reduced the error in the 3D reconstruction by a factor of 2.64 while requiring a medium runtime of 30 min per scene. Furthermore, the optimized motion achieves sufficient quality to perform an appearance estimation of the deforming object, recovering sharp details from this single monocular RGB video.
Capture Stage Environments: A Guide to Better Matting
Jul 10, 2025



Capture stages are high-end sources of state-of-the-art recordings for downstream applications in movies, games, and other media. One crucial step in almost all pipelines is the matting of images to isolate the captured performances from the background. While common matting algorithms deliver remarkable performance in other applications like teleconferencing and mobile entertainment, we found that they struggle significantly with the peculiarities of capture stage content. The goal of our work is to share insights into those challenges as a curated list of those characteristics along with a constructive discussion for proactive intervention and present a guideline to practitioners for an improved workflow to mitigate unresolved challenges. To this end, we also demonstrate an efficient pipeline to adapt state-of-the-art approaches to such custom setups without the need of extensive annotations, both offline and real-time. For an objective evaluation, we propose a validation methodology based on a leading diffusion model that highlights the benefits of our approach.
Real-time Image-based Lighting of Glints
Jul 03, 2025Image-based lighting is a widely used technique to reproduce shading under real-world lighting conditions, especially in real-time rendering applications. A particularly challenging scenario involves materials exhibiting a sparkling or glittering appearance, caused by discrete microfacets scattered across their surface. In this paper, we propose an efficient approximation for image-based lighting of glints, enabling fully dynamic material properties and environment maps. Our novel approach is grounded in real-time glint rendering under area light illumination and employs standard environment map filtering techniques. Crucially, our environment map filtering process is sufficiently fast to be executed on a per-frame basis. Our method assumes that the environment map is partitioned into few homogeneous regions of constant radiance. By filtering the corresponding indicator functions with the normal distribution function, we obtain the probabilities for individual microfacets to reflect light from each region. During shading, these probabilities are utilized to hierarchically sample a multinomial distribution, facilitated by our novel dual-gated Gaussian approximation of binomial distributions. We validate that our real-time approximation is close to ground-truth renderings for a range of material properties and lighting conditions, and demonstrate robust and stable performance, with little overhead over rendering glints from a single directional light. Compared to rendering smooth materials without glints, our approach requires twice as much memory to store the prefiltered environment map.
PyEvalAI: AI-assisted evaluation of Jupyter Notebooks for immediate personalized feedback
Feb 25, 2025Grading student assignments in STEM courses is a laborious and repetitive task for tutors, often requiring a week to assess an entire class. For students, this delay of feedback prevents iterating on incorrect solutions, hampers learning, and increases stress when exercise scores determine admission to the final exam. Recent advances in AI-assisted education, such as automated grading and tutoring systems, aim to address these challenges by providing immediate feedback and reducing grading workload. However, existing solutions often fall short due to privacy concerns, reliance on proprietary closed-source models, lack of support for combining Markdown, LaTeX and Python code, or excluding course tutors from the grading process. To overcome these limitations, we introduce PyEvalAI, an AI-assisted evaluation system, which automatically scores Jupyter notebooks using a combination of unit tests and a locally hosted language model to preserve privacy. Our approach is free, open-source, and ensures tutors maintain full control over the grading process. A case study demonstrates its effectiveness in improving feedback speed and grading efficiency for exercises in a university-level course on numerics.
ROSA: Reconstructing Object Shape and Appearance Textures by Adaptive Detail Transfer
Jan 30, 2025



Reconstructing an object's shape and appearance in terms of a mesh textured by a spatially-varying bidirectional reflectance distribution function (SVBRDF) from a limited set of images captured under collocated light is an ill-posed problem. Previous state-of-the-art approaches either aim to reconstruct the appearance directly on the geometry or additionally use texture normals as part of the appearance features. However, this requires detailed but inefficiently large meshes, that would have to be simplified in a post-processing step, or suffers from well-known limitations of normal maps such as missing shadows or incorrect silhouettes. Another limiting factor is the fixed and typically low resolution of the texture estimation resulting in loss of important surface details. To overcome these problems, we present ROSA, an inverse rendering method that directly optimizes mesh geometry with spatially adaptive mesh resolution solely based on the image data. In particular, we refine the mesh and locally condition the surface smoothness based on the estimated normal texture and mesh curvature. In addition, we enable the reconstruction of fine appearance details in high-resolution textures through a pioneering tile-based method that operates on a single pre-trained decoder network but is not limited by the network output resolution.
NeRFs are Mirror Detectors: Using Structural Similarity for Multi-View Mirror Scene Reconstruction with 3D Surface Primitives
Jan 07, 2025



While neural radiance fields (NeRF) led to a breakthrough in photorealistic novel view synthesis, handling mirroring surfaces still denotes a particular challenge as they introduce severe inconsistencies in the scene representation. Previous attempts either focus on reconstructing single reflective objects or rely on strong supervision guidance in terms of additional user-provided annotations of visible image regions of the mirrors, thereby limiting the practical usability. In contrast, in this paper, we present NeRF-MD, a method which shows that NeRFs can be considered as mirror detectors and which is capable of reconstructing neural radiance fields of scenes containing mirroring surfaces without the need for prior annotations. To this end, we first compute an initial estimate of the scene geometry by training a standard NeRF using a depth reprojection loss. Our key insight lies in the fact that parts of the scene corresponding to a mirroring surface will still exhibit a significant photometric inconsistency, whereas the remaining parts are already reconstructed in a plausible manner. This allows us to detect mirror surfaces by fitting geometric primitives to such inconsistent regions in this initial stage of the training. Using this information, we then jointly optimize the radiance field and mirror geometry in a second training stage to refine their quality. We demonstrate the capability of our method to allow the faithful detection of mirrors in the scene as well as the reconstruction of a single consistent scene representation, and demonstrate its potential in comparison to baseline and mirror-aware approaches.