 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimate-based Pre-screening of Self-sustaining Regreening Opportunities in Drylands: A Case Study for Saudi Arabia
May 05, 2026Large-scale restoration in drylands is widely promoted to address land degradation and biodiversity loss, yet many efforts rely on long-term irrigation, limiting sustainability in water-scarce regions. A key challenge is identifying locations where native vegetation can persist without intensive management while minimizing costly field campaigns. A scalable pre-screening framework is presented that integrates climate and remote sensing data to enable cost-efficient site selection in arid environments using Saudi Arabia as a case study. A Climate Suitability Score (CSS), derived from machine learning models trained on expert-curated reference sites, captures complex climatic dependencies on vegetation persistence. Using multi-year ERA5-Land data for Saudi Arabia, national-scale prediction maps are generated and combined with vegetation indices to identify areas where climate is favorable, but vegetation remains underdeveloped. Multi-criteria screening reduces candidates to thirteen priority locations. Climatically analogous intact ecosystems provide benchmarks for restoration targets and indicate that an average 2.5 fold increase in vegetation coverage is a realistic target for restoration efforts. Overall, this approach narrows the search space, reduces costs, and supports resilient ecosystem recovery planning in water-limited regions.
Autoregressive Generation of Static and Growing Trees
Feb 07, 2025We propose a transformer architecture and training strategy for tree generation. The architecture processes data at multiple resolutions and has an hourglass shape, with middle layers processing fewer tokens than outer layers. Similar to convolutional networks, we introduce longer range skip connections to completent this multi-resolution approach. The key advantage of this architecture is the faster processing speed and lower memory consumption. We are therefore able to process more complex trees than would be possible with a vanilla transformer architecture. Furthermore, we extend this approach to perform image-to-tree and point-cloud-to-tree conditional generation and to simulate the tree growth processes, generating 4D trees. Empirical results validate our approach in terms of speed, memory consumption, and generation quality.
Harmony: A Joint Self-Supervised and Weakly-Supervised Framework for Learning General Purpose Visual Representations
May 23, 2024Vision-language contrastive learning frameworks like CLIP enable learning representations from natural language supervision, and provide strong zero-shot classification capabilities. However, due to the nature of the supervisory signal in these paradigms, they lack the ability to learn localized features, leading to degraded performance on dense prediction tasks like segmentation and detection. On the other hand, self-supervised learning methods have shown the ability to learn granular representations, complementing the high-level features in vision-language training. In this work, we present Harmony, a framework that combines vision-language training with discriminative and generative self-supervision to learn visual features that can be generalized across vision downstream tasks. Our framework is specifically designed to work on web-scraped data by not relying on negative examples and addressing the one-to-one correspondence issue using soft CLIP targets generated by an EMA model. We comprehensively evaluate Harmony across various vision downstream tasks and find that it significantly outperforms the baseline CLIP and the previously leading joint self and weakly-supervised methods, MaskCLIP and SLIP. Specifically, when comparing against these methods, Harmony shows superior performance in fine-tuning and zero-shot classification on ImageNet-1k, semantic segmentation on ADE20K, and both object detection and instance segmentation on MS-COCO, when pre-training a ViT-S/16 on CC3M. We also show that Harmony outperforms other self-supervised learning methods like iBOT and MAE across all tasks evaluated. On https://github.com/MohammedSB/Harmony our code is publicly available.
A Lennard-Jones Layer for Distribution Normalization
Feb 05, 2024

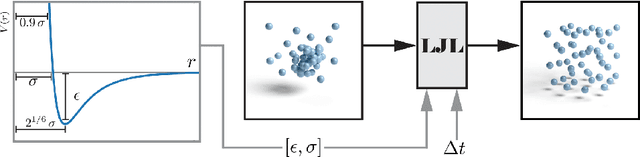

We introduce the Lennard-Jones layer (LJL) for the equalization of the density of 2D and 3D point clouds through systematically rearranging points without destroying their overall structure (distribution normalization). LJL simulates a dissipative process of repulsive and weakly attractive interactions between individual points by considering the nearest neighbor of each point at a given moment in time. This pushes the particles into a potential valley, reaching a well-defined stable configuration that approximates an equidistant sampling after the stabilization process. We apply LJLs to redistribute randomly generated point clouds into a randomized uniform distribution. Moreover, LJLs are embedded in the generation process of point cloud networks by adding them at later stages of the inference process. The improvements in 3D point cloud generation utilizing LJLs are evaluated qualitatively and quantitatively. Finally, we apply LJLs to improve the point distribution of a score-based 3D point cloud denoising network. In general, we demonstrate that LJLs are effective for distribution normalization which can be applied at negligible cost without retraining the given neural network.
Gazebo Plants: Simulating Plant-Robot Interaction with Cosserat Rods
Feb 04, 2024
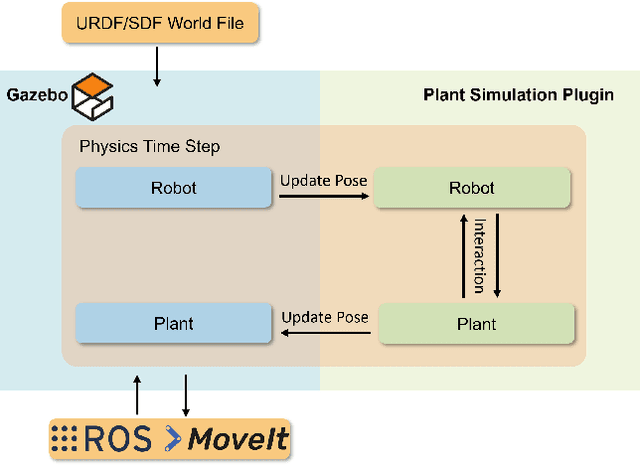
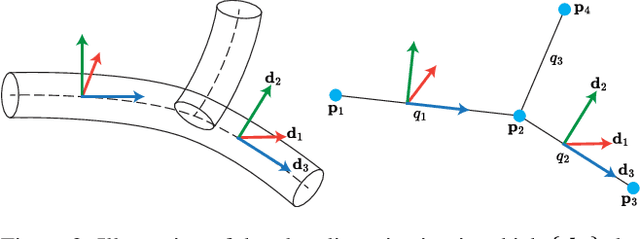
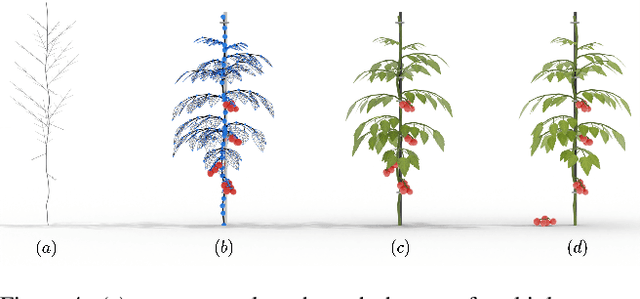
Robotic harvesting has the potential to positively impact agricultural productivity, reduce costs, improve food quality, enhance sustainability, and to address labor shortage. In the rapidly advancing field of agricultural robotics, the necessity of training robots in a virtual environment has become essential. Generating training data to automatize the underlying computer vision tasks such as image segmentation, object detection and classification, also heavily relies on such virtual environments as synthetic data is often required to overcome the shortage and lack of variety of real data sets. However, physics engines commonly employed within the robotics community, such as ODE, Simbody, Bullet, and DART, primarily support motion and collision interaction of rigid bodies. This inherent limitation hinders experimentation and progress in handling non-rigid objects such as plants and crops. In this contribution, we present a plugin for the Gazebo simulation platform based on Cosserat rods to model plant motion. It enables the simulation of plants and their interaction with the environment. We demonstrate that, using our plugin, users can conduct harvesting simulations in Gazebo by simulating a robotic arm picking fruits and achieve results comparable to real-world experiments.
Zero-Level-Set Encoder for Neural Distance Fields
Oct 10, 2023
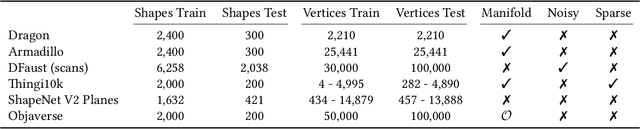
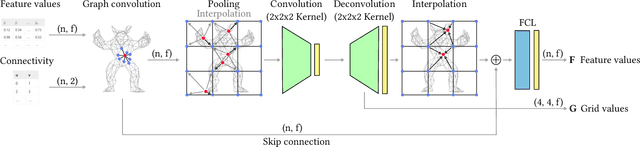
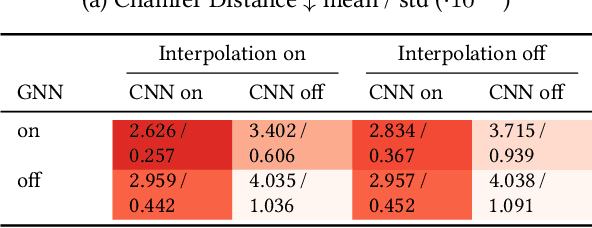
Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., to compute a signed distance or occupancy value at a specific spatial position. Previous methods tend to rely on the auto-decoder paradigm, which often requires densely-sampled and accurate signed distances to be known during training and testing, as well as an additional optimization loop during inference. This introduces a lot of computational overhead, in addition to having to compute signed distances analytically, even during testing. In this paper, we present a novel encoder-decoder neural network for embedding 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. Furthermore, the network is trained to solve the Eikonal equation and only requires knowledge of the zero-level set for training and inference. Additional volumetric samples can be generated on-the-fly, and incorporated in an unsupervised manner. This means that in contrast to most previous work, our network is able to output valid signed distance fields without explicit prior knowledge of non-zero distance values or shape occupancy. In other words, our network computes approximate solutions to the boundary-valued Eikonal equation. It also requires only a single forward pass during inference, instead of the common latent code optimization. We further propose a modification of the loss function in case that surface normals are not well defined, e.g., in the context of non-watertight surface-meshes and non-manifold geometry. We finally demonstrate the efficacy, generalizability and scalability of our method on datasets consisting of deforming 3D shapes, single class encoding and multiclass encoding, showcasing a wide range of possible applications.
Neural inverse procedural modeling of knitting yarns from images
Mar 01, 2023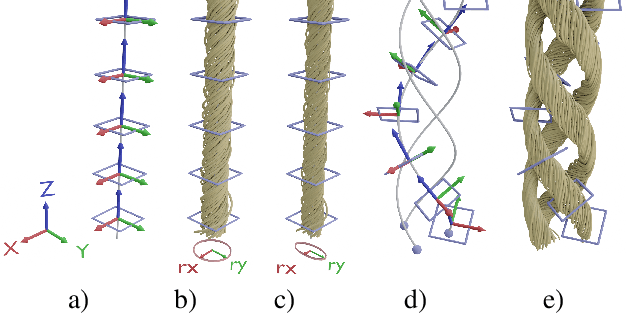
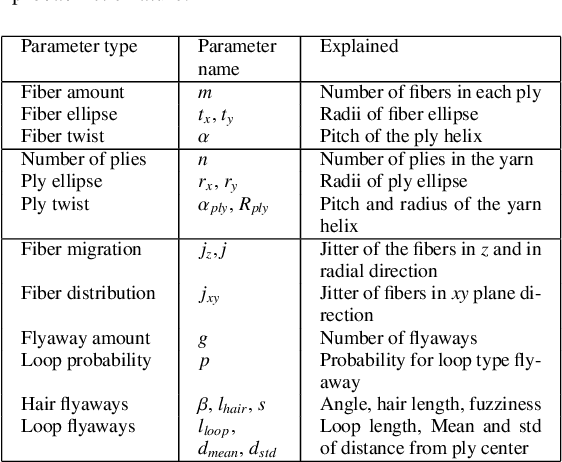

We investigate the capabilities of neural inverse procedural modeling to infer high-quality procedural yarn models with fiber-level details from single images of depicted yarn samples. While directly inferring all parameters of the underlying yarn model based on a single neural network may seem an intuitive choice, we show that the complexity of yarn structures in terms of twisting and migration characteristics of the involved fibers can be better encountered in terms of ensembles of networks that focus on individual characteristics. We analyze the effect of different loss functions including a parameter loss to penalize the deviation of inferred parameters to ground truth annotations, a reconstruction loss to enforce similar statistics of the image generated for the estimated parameters in comparison to training images as well as an additional regularization term to explicitly penalize deviations between latent codes of synthetic images and the average latent code of real images in the latent space of the encoder. We demonstrate that the combination of a carefully designed parametric, procedural yarn model with respective network ensembles as well as loss functions even allows robust parameter inference when solely trained on synthetic data. Since our approach relies on the availability of a yarn database with parameter annotations and we are not aware of such a respectively available dataset, we additionally provide, to the best of our knowledge, the first dataset of yarn images with annotations regarding the respective yarn parameters. For this purpose, we use a novel yarn generator that improves the realism of the produced results over previous approaches.
Domain Adaptation with Morphologic Segmentation
Jun 16, 2020


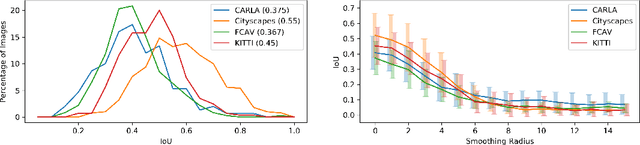
We present a novel domain adaptation framework that uses morphologic segmentation to translate images from arbitrary input domains (real and synthetic) into a uniform output domain. Our framework is based on an established image-to-image translation pipeline that allows us to first transform the input image into a generalized representation that encodes morphology and semantics - the edge-plus-segmentation map (EPS) - which is then transformed into an output domain. Images transformed into the output domain are photo-realistic and free of artifacts that are commonly present across different real (e.g. lens flare, motion blur, etc.) and synthetic (e.g. unrealistic textures, simplified geometry, etc.) data sets. Our goal is to establish a preprocessing step that unifies data from multiple sources into a common representation that facilitates training downstream tasks in computer vision. This way, neural networks for existing tasks can be trained on a larger variety of training data, while they are also less affected by overfitting to specific data sets. We showcase the effectiveness of our approach by qualitatively and quantitatively evaluating our method on four data sets of simulated and real data of urban scenes. Additional results can be found on the project website available at http://jonathank.de/research/eps/ .
A Calibration Scheme for Non-Line-of-Sight Imaging Setups
Dec 20, 2019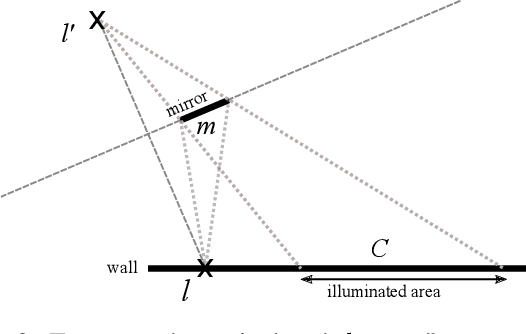
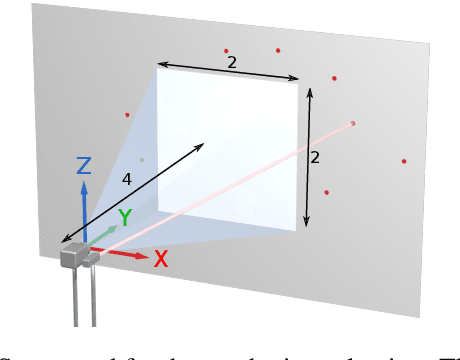
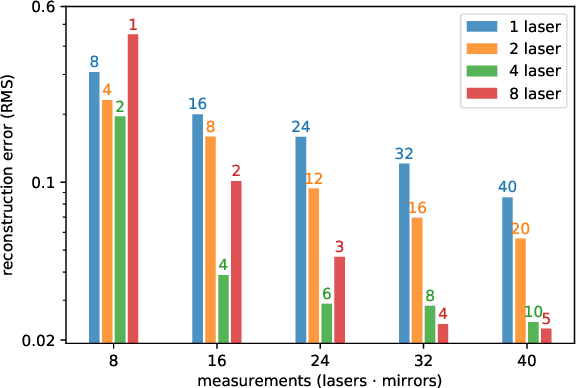
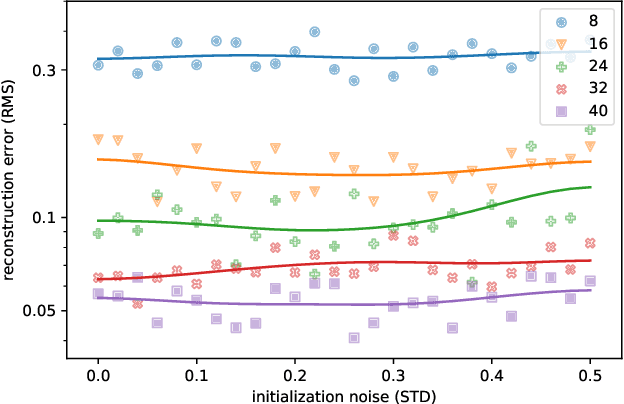
The recent years have given rise to a large number of techniques for "looking around corners", i.e., for reconstructing occluded objects from time-resolved measurements of indirect light reflections off a wall. While the direct view of cameras is routinely calibrated in computer vision applications, the calibration of non-line-of-sight setups has so far relied on manual measurement of the most important dimensions (device positions, wall position and orientation, etc.). In this paper, we propose a semi-automatic method for calibrating such systems that relies on mirrors as known targets. A roughly determined initialization is refined in order to optimize a spatio-temporal consistency. Our system is general enough to be applicable to a variety of sensing scenarios ranging from single sources/detectors via scanning arrangements to large-scale arrays. It is robust towards bad initialization and the achieved accuracy is proportional to the depth resolution of the camera system. We demonstrate this capability with a real-world setup and despite a large number of dead pixels and very low temporal resolution achieve a result that outperforms a manual calibration.
Optically lightweight tracking of objects around a corner
Jun 03, 2016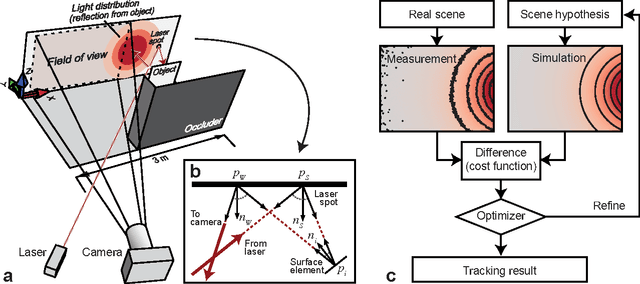

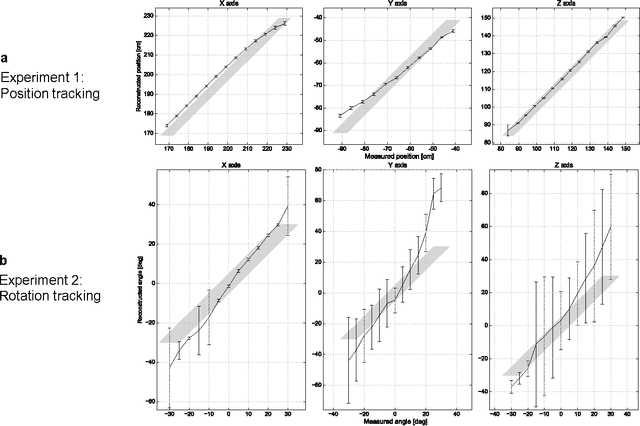
The observation of objects located in inaccessible regions is a recurring challenge in a wide variety of important applications. Recent work has shown that indirect diffuse light reflections can be used to reconstruct objects and two-dimensional (2D) patterns around a corner. However, these prior methods always require some specialized setup involving either ultrafast detectors or narrowband light sources. Here we show that occluded objects can be tracked in real time using a standard 2D camera and a laser pointer. Unlike previous methods based on the backprojection approach, we formulate the problem in an analysis-by-synthesis sense. By repeatedly simulating light transport through the scene, we determine the set of object parameters that most closely fits the measured intensity distribution. We experimentally demonstrate that this approach is capable of following the translation of unknown objects, and translation and orientation of a known object, in real time.