 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Generation of Static and Growing Trees
Feb 07, 2025We propose a transformer architecture and training strategy for tree generation. The architecture processes data at multiple resolutions and has an hourglass shape, with middle layers processing fewer tokens than outer layers. Similar to convolutional networks, we introduce longer range skip connections to completent this multi-resolution approach. The key advantage of this architecture is the faster processing speed and lower memory consumption. We are therefore able to process more complex trees than would be possible with a vanilla transformer architecture. Furthermore, we extend this approach to perform image-to-tree and point-cloud-to-tree conditional generation and to simulate the tree growth processes, generating 4D trees. Empirical results validate our approach in terms of speed, memory consumption, and generation quality.
Perm: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 31, 2024We present Perm, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: https://github.com/c-he/perm.
\textsc{Perm}: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 28, 2024We present \textsc{Perm}, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: \url{https://github.com/c-he/perm}.
Harmony: A Joint Self-Supervised and Weakly-Supervised Framework for Learning General Purpose Visual Representations
May 23, 2024Vision-language contrastive learning frameworks like CLIP enable learning representations from natural language supervision, and provide strong zero-shot classification capabilities. However, due to the nature of the supervisory signal in these paradigms, they lack the ability to learn localized features, leading to degraded performance on dense prediction tasks like segmentation and detection. On the other hand, self-supervised learning methods have shown the ability to learn granular representations, complementing the high-level features in vision-language training. In this work, we present Harmony, a framework that combines vision-language training with discriminative and generative self-supervision to learn visual features that can be generalized across vision downstream tasks. Our framework is specifically designed to work on web-scraped data by not relying on negative examples and addressing the one-to-one correspondence issue using soft CLIP targets generated by an EMA model. We comprehensively evaluate Harmony across various vision downstream tasks and find that it significantly outperforms the baseline CLIP and the previously leading joint self and weakly-supervised methods, MaskCLIP and SLIP. Specifically, when comparing against these methods, Harmony shows superior performance in fine-tuning and zero-shot classification on ImageNet-1k, semantic segmentation on ADE20K, and both object detection and instance segmentation on MS-COCO, when pre-training a ViT-S/16 on CC3M. We also show that Harmony outperforms other self-supervised learning methods like iBOT and MAE across all tasks evaluated. On https://github.com/MohammedSB/Harmony our code is publicly available.
LAESI: Leaf Area Estimation with Synthetic Imagery
Mar 31, 2024We introduce LAESI, a Synthetic Leaf Dataset of 100,000 synthetic leaf images on millimeter paper, each with semantic masks and surface area labels. This dataset provides a resource for leaf morphology analysis primarily aimed at beech and oak leaves. We evaluate the applicability of the dataset by training machine learning models for leaf surface area prediction and semantic segmentation, using real images for validation. Our validation shows that these models can be trained to predict leaf surface area with a relative error not greater than an average human annotator. LAESI also provides an efficient framework based on 3D procedural models and generative AI for the large-scale, controllable generation of data with potential further applications in agriculture and biology. We evaluate the inclusion of generative AI in our procedural data generation pipeline and show how data filtering based on annotation consistency results in datasets which allow training the highest performing vision models.
Generating Diverse Agricultural Data for Vision-Based Farming Applications
Mar 27, 2024



We present a specialized procedural model for generating synthetic agricultural scenes, focusing on soybean crops, along with various weeds. This model is capable of simulating distinct growth stages of these plants, diverse soil conditions, and randomized field arrangements under varying lighting conditions. The integration of real-world textures and environmental factors into the procedural generation process enhances the photorealism and applicability of the synthetic data. Our dataset includes 12,000 images with semantic labels, offering a comprehensive resource for computer vision tasks in precision agriculture, such as semantic segmentation for autonomous weed control. We validate our model's effectiveness by comparing the synthetic data against real agricultural images, demonstrating its potential to significantly augment training data for machine learning models in agriculture. This approach not only provides a cost-effective solution for generating high-quality, diverse data but also addresses specific needs in agricultural vision tasks that are not fully covered by general-purpose models.
A Lennard-Jones Layer for Distribution Normalization
Feb 05, 2024We introduce the Lennard-Jones layer (LJL) for the equalization of the density of 2D and 3D point clouds through systematically rearranging points without destroying their overall structure (distribution normalization). LJL simulates a dissipative process of repulsive and weakly attractive interactions between individual points by considering the nearest neighbor of each point at a given moment in time. This pushes the particles into a potential valley, reaching a well-defined stable configuration that approximates an equidistant sampling after the stabilization process. We apply LJLs to redistribute randomly generated point clouds into a randomized uniform distribution. Moreover, LJLs are embedded in the generation process of point cloud networks by adding them at later stages of the inference process. The improvements in 3D point cloud generation utilizing LJLs are evaluated qualitatively and quantitatively. Finally, we apply LJLs to improve the point distribution of a score-based 3D point cloud denoising network. In general, we demonstrate that LJLs are effective for distribution normalization which can be applied at negligible cost without retraining the given neural network.
Gazebo Plants: Simulating Plant-Robot Interaction with Cosserat Rods
Feb 04, 2024Robotic harvesting has the potential to positively impact agricultural productivity, reduce costs, improve food quality, enhance sustainability, and to address labor shortage. In the rapidly advancing field of agricultural robotics, the necessity of training robots in a virtual environment has become essential. Generating training data to automatize the underlying computer vision tasks such as image segmentation, object detection and classification, also heavily relies on such virtual environments as synthetic data is often required to overcome the shortage and lack of variety of real data sets. However, physics engines commonly employed within the robotics community, such as ODE, Simbody, Bullet, and DART, primarily support motion and collision interaction of rigid bodies. This inherent limitation hinders experimentation and progress in handling non-rigid objects such as plants and crops. In this contribution, we present a plugin for the Gazebo simulation platform based on Cosserat rods to model plant motion. It enables the simulation of plants and their interaction with the environment. We demonstrate that, using our plugin, users can conduct harvesting simulations in Gazebo by simulating a robotic arm picking fruits and achieve results comparable to real-world experiments.
Deep Aramaic: Towards a Synthetic Data Paradigm Enabling Machine Learning in Epigraphy
Oct 11, 2023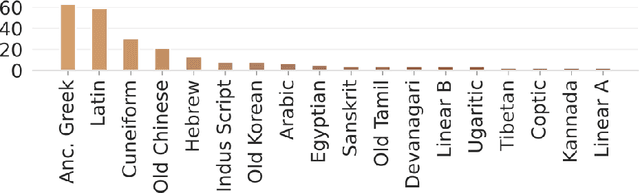



Epigraphy increasingly turns to modern artificial intelligence (AI) technologies such as machine learning (ML) for extracting insights from ancient inscriptions. However, scarce labeled data for training ML algorithms severely limits current techniques, especially for ancient scripts like Old Aramaic. Our research pioneers an innovative methodology for generating synthetic training data tailored to Old Aramaic letters. Our pipeline synthesizes photo-realistic Aramaic letter datasets, incorporating textural features, lighting, damage, and augmentations to mimic real-world inscription diversity. Despite minimal real examples, we engineer a dataset of 250,000 training and 25,000 validation images covering the 22 letter classes in the Aramaic alphabet. This comprehensive corpus provides a robust volume of data for training a residual neural network (ResNet) to classify highly degraded Aramaic letters. The ResNet model demonstrates high accuracy in classifying real images from the 8th century BCE Hadad statue inscription. Additional experiments validate performance on varying materials and styles, proving effective generalization. Our results validate the model's capabilities in handling diverse real-world scenarios, proving the viability of our synthetic data approach and avoiding the dependence on scarce training data that has constrained epigraphic analysis. Our innovative framework elevates interpretation accuracy on damaged inscriptions, thus enhancing knowledge extraction from these historical resources.
Zero-Level-Set Encoder for Neural Distance Fields
Oct 10, 2023Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., to compute a signed distance or occupancy value at a specific spatial position. Previous methods tend to rely on the auto-decoder paradigm, which often requires densely-sampled and accurate signed distances to be known during training and testing, as well as an additional optimization loop during inference. This introduces a lot of computational overhead, in addition to having to compute signed distances analytically, even during testing. In this paper, we present a novel encoder-decoder neural network for embedding 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. Furthermore, the network is trained to solve the Eikonal equation and only requires knowledge of the zero-level set for training and inference. Additional volumetric samples can be generated on-the-fly, and incorporated in an unsupervised manner. This means that in contrast to most previous work, our network is able to output valid signed distance fields without explicit prior knowledge of non-zero distance values or shape occupancy. In other words, our network computes approximate solutions to the boundary-valued Eikonal equation. It also requires only a single forward pass during inference, instead of the common latent code optimization. We further propose a modification of the loss function in case that surface normals are not well defined, e.g., in the context of non-watertight surface-meshes and non-manifold geometry. We finally demonstrate the efficacy, generalizability and scalability of our method on datasets consisting of deforming 3D shapes, single class encoding and multiclass encoding, showcasing a wide range of possible applications.