 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint of View: How Perspective Affects Perceived Robot Sociability
Mar 30, 2026Ensuring that robot navigation is safe and socially acceptable is crucial for comfortable human-robot interaction in shared environments. However, existing validation methods often rely on a bird's-eye (allocentric) perspective, which fails to capture the subjective first-person experience of pedestrians encountering robots in the real world. In this paper, we address the perceptual gap between allocentric validation and egocentric experience by investigating how different perspectives affect the perceived sociability and disturbance of robot trajectories. Our approach uses an immersive VR environment to evaluate identical robot trajectories across allocentric, egocentric-proximal, and egocentric-distal viewpoints in a user study. We perform this analysis for trajectories generated from two different navigation policies to understand if the observed differences are unique to a single type of trajectory or more generalizable. We further examine whether augmenting a trajectory with a head-nod gesture can bridge the perceptual gap and improve human comfort. Our experiments suggest that trajectories rated as sociable from an allocentric view may be perceived as significantly more disturbing when experienced from a first-person perspective in close proximity. Our results also demonstrate that while passing distance affects perceived disturbance, communicative social signaling, such as a head-nod, can effectively enhance the perceived sociability of the robot's behavior.
Interpreting Context-Aware Human Preferences for Multi-Objective Robot Navigation
Mar 18, 2026Robots operating in human-shared environments must not only achieve task-level navigation objectives such as safety and efficiency, but also adapt their behavior to human preferences. However, as human preferences are typically expressed in natural language and depend on environmental context, it is difficult to directly integrate them into low-level robot control policies. In this work, we present a pipeline that enables robots to understand and apply context-dependent navigation preferences by combining foundational models with a Multi-Objective Reinforcement Learning (MORL) navigation policy. Thus, our approach integrates high-level semantic reasoning with low-level motion control. A Vision-Language Model (VLM) extracts structured environmental context from onboard visual observations, while Large Language Models (LLM) convert natural language user feedback into interpretable, context-dependent behavioral rules stored in a persistent but updatable rule memory. A preference translation module then maps contextual information and stored rules into numerical preference vectors that parameterize a pretrained MORL policy for real-time navigation adaptation. We evaluate the proposed framework through quantitative component-level evaluations, a user study, and real-world robot deployments in various indoor environments. Our results demonstrate that the system reliably captures user intent, generates consistent preference vectors, and enables controllable behavior adaptation across diverse contexts. Overall, the proposed pipeline improves the adaptability, transparency, and usability of robots operating in shared human environments, while maintaining safe and responsive real-time control.
EvidMTL: Evidential Multi-Task Learning for Uncertainty-Aware Semantic Surface Mapping from Monocular RGB Images
Mar 06, 2025For scene understanding in unstructured environments, an accurate and uncertainty-aware metric-semantic mapping is required to enable informed action selection by autonomous systems.Existing mapping methods often suffer from overconfident semantic predictions, and sparse and noisy depth sensing, leading to inconsistent map representations. In this paper, we therefore introduce EvidMTL, a multi-task learning framework that uses evidential heads for depth estimation and semantic segmentation, enabling uncertainty-aware inference from monocular RGB images. To enable uncertainty-calibrated evidential multi-task learning, we propose a novel evidential depth loss function that jointly optimizes the belief strength of the depth prediction in conjunction with evidential segmentation loss. Building on this, we present EvidKimera, an uncertainty-aware semantic surface mapping framework, which uses evidential depth and semantics prediction for improved 3D metric-semantic consistency. We train and evaluate EvidMTL on the NYUDepthV2 and assess its zero-shot performance on ScanNetV2, demonstrating superior uncertainty estimation compared to conventional approaches while maintaining comparable depth estimation and semantic segmentation. In zero-shot mapping tests on ScanNetV2, EvidKimera outperforms Kimera in semantic surface mapping accuracy and consistency, highlighting the benefits of uncertainty-aware mapping and underscoring its potential for real-world robotic applications.
Map Space Belief Prediction for Manipulation-Enhanced Mapping
Feb 28, 2025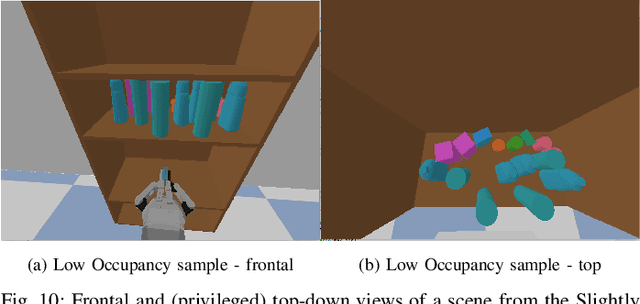
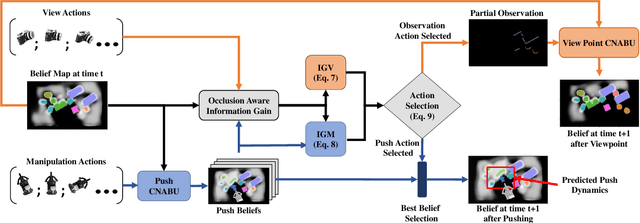
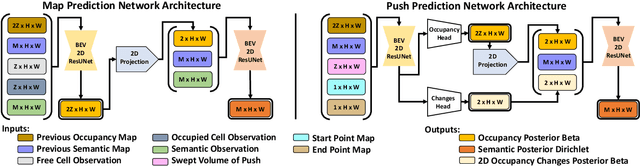

Searching for objects in cluttered environments requires selecting efficient viewpoints and manipulation actions to remove occlusions and reduce uncertainty in object locations, shapes, and categories. In this work, we address the problem of manipulation-enhanced semantic mapping, where a robot has to efficiently identify all objects in a cluttered shelf. Although Partially Observable Markov Decision Processes~(POMDPs) are standard for decision-making under uncertainty, representing unstructured interactive worlds remains challenging in this formalism. To tackle this, we define a POMDP whose belief is summarized by a metric-semantic grid map and propose a novel framework that uses neural networks to perform map-space belief updates to reason efficiently and simultaneously about object geometries, locations, categories, occlusions, and manipulation physics. Further, to enable accurate information gain analysis, the learned belief updates should maintain calibrated estimates of uncertainty. Therefore, we propose Calibrated Neural-Accelerated Belief Updates (CNABUs) to learn a belief propagation model that generalizes to novel scenarios and provides confidence-calibrated predictions for unknown areas. Our experiments show that our novel POMDP planner improves map completeness and accuracy over existing methods in challenging simulations and successfully transfers to real-world cluttered shelves in zero-shot fashion.
Constrained Object Placement Using Reinforcement Learning
Apr 16, 2024
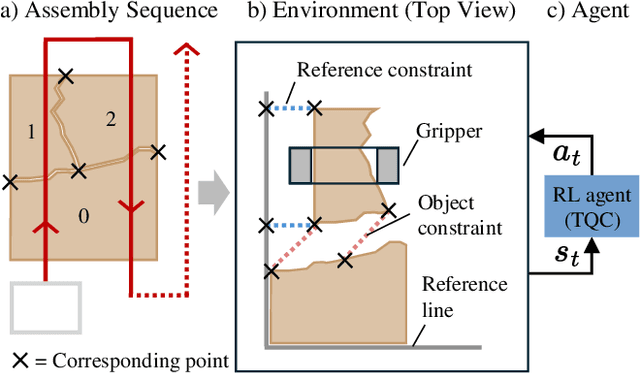
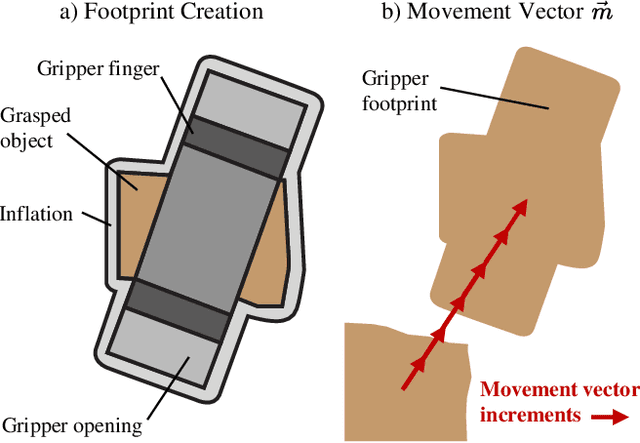
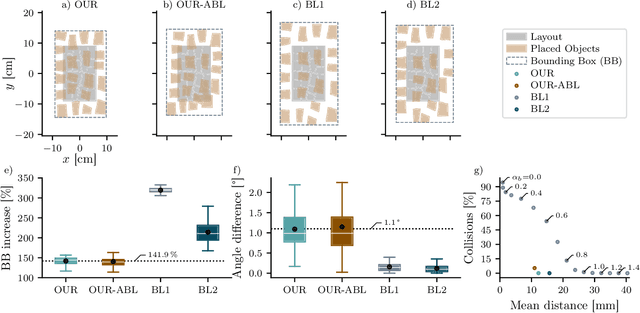
Close and precise placement of irregularly shaped objects requires a skilled robotic system. Particularly challenging is the manipulation of objects that have sensitive top surfaces and a fixed set of neighbors. To avoid damaging the surface, they have to be grasped from the side, and during placement, their neighbor relations have to be maintained. In this work, we train a reinforcement learning agent that generates smooth end-effector motions to place objects as close as possible next to each other. During the placement, our agent considers neighbor constraints defined in a given layout of the objects while trying to avoid collisions. Our approach learns to place compact object assemblies without the need for predefined spacing between objects as required by traditional methods. We thoroughly evaluated our approach using a two-finger gripper mounted to a robotic arm with six degrees of freedom. The results show that our agent outperforms two baseline approaches in terms of object assembly compactness, thereby reducing the needed space to place the objects according to the given neighbor constraints. On average, our approach reduces the distances between all placed objects by at least 60%, with fewer collisions at the same compactness compared to both baselines.
Learning Goal-Directed Object Pushing in Cluttered Scenes with Location-Based Attention
Mar 26, 2024Non-prehensile planar pushing is a challenging task due to its underactuated nature with hybrid-dynamics, where a robot needs to reason about an object's long-term behaviour and contact-switching, while being robust to contact uncertainty. The presence of clutter in the environment further complicates this task, introducing the need to include more sophisticated spatial analysis to avoid collisions. Building upon prior work on reinforcement learning (RL) with multimodal categorical exploration for planar pushing, in this paper we incorporate location-based attention to enable robust navigation through clutter. Unlike previous RL literature addressing this obstacle avoidance pushing task, our framework requires no predefined global paths and considers the target orientation of the manipulated object. Our results demonstrate that the learned policies successfully navigate through a wide range of complex obstacle configurations, including dynamic obstacles, with smooth motions, achieving the desired target object pose. We also validate the transferability of the learned policies to robotic hardware using the KUKA iiwa robot arm.
RHINO-VR Experience: Teaching Mobile Robotics Concepts in an Interactive Museum Exhibit
Mar 22, 2024



In 1997, the very first tour guide robot RHINO was deployed in a museum in Germany. With the ability to navigate autonomously through the environment, the robot gave tours to over 2,000 visitors. Today, RHINO itself has become an exhibit and is no longer operational. In this paper, we present RHINO-VR, an interactive museum exhibit using virtual reality (VR) that allows museum visitors to experience the historical robot RHINO in operation in a virtual museum. RHINO-VR, unlike static exhibits, enables users to familiarize themselves with basic mobile robotics concepts without the fear of damaging the exhibit. In the virtual environment, the user is able to interact with RHINO in VR by pointing to a location to which the robot should navigate and observing the corresponding actions of the robot. To include other visitors who cannot use the VR, we provide an external observation view to make RHINO visible to them. We evaluated our system by measuring the frame rate of the VR simulation, comparing the generated virtual 3D models with the originals, and conducting a user study. The user-study showed that RHINO-VR improved the visitors' understanding of the robot's functionality and that they would recommend experiencing the VR exhibit to others.
Safe Multi-Agent Reinforcement Learning for Formation Control without Individual Reference Targets
Dec 20, 2023



In recent years, formation control of unmanned vehicles has received considerable interest, driven by the progress in autonomous systems and the imperative for multiple vehicles to carry out diverse missions. In this paper, we address the problem of behavior-based formation control of mobile robots, where we use safe multi-agent reinforcement learning~(MARL) to ensure the safety of the robots by eliminating all collisions during training and execution. To ensure safety, we implemented distributed model predictive control safety filters to override unsafe actions. We focus on achieving behavior-based formation without having individual reference targets for the robots, and instead use targets for the centroid of the formation. This formulation facilitates the deployment of formation control on real robots and improves the scalability of our approach to more robots. The task cannot be addressed through optimization-based controllers without specific individual reference targets for the robots and information about the relative locations of each robot to the others. That is why, for our formulation we use MARL to train the robots. Moreover, in order to account for the interactions between the agents, we use attention-based critics to improve the training process. We train the agents in simulation and later on demonstrate the resulting behavior of our approach on real Turtlebot robots. We show that despite the agents having very limited information, we can still safely achieve the desired behavior.
DawnIK: Decentralized Collision-Aware Inverse Kinematics Solver for Heterogeneous Multi-Arm Systems
Jul 24, 2023Although inverse kinematics of serial manipulators is a well studied problem, challenges still exist in finding smooth feasible solutions that are also collision aware. Furthermore, with collaborative and service robots gaining traction, different robotic systems have to work in close proximity. This means that the current inverse kinematics approaches have to not only avoid collisions with themselves but also collisions with other robot arms. Therefore, we present a novel approach to compute inverse kinematics for serial manipulators that take into account different constraints while trying to reach a desired end-effector position and/or orientation that avoids collisions with themselves and other arms. Unlike other constraint based approaches, we neither perform expensive inverse Jacobian computations nor do we require arms with redundant degrees of freedom. Instead, we formulate different constraints as weighted cost functions to be optimized by a non-linear optimization solver. Our approach is superior to the state-of-the-art CollisionIK in terms of collision avoidance in the presence of multiple arms in confined spaces with no detected collisions at all in all the experimental scenarios. When the probability of collision is low, our approach shows better performance at trajectory tracking as well. Additionally, our approach is capable of simultaneous yet decentralized control of multiple arms for trajectory tracking in intersecting workspace without any collisions.
One-Shot View Planning for Fast and Complete Unknown Object Reconstruction
Apr 03, 2023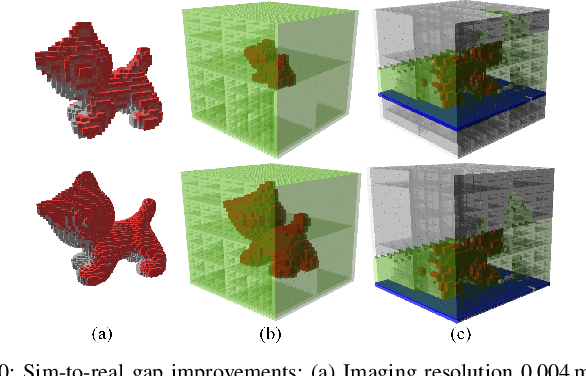
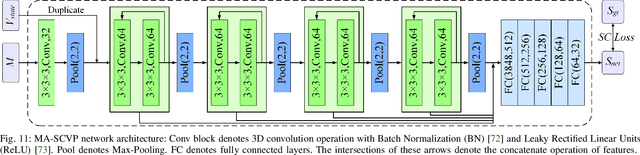


Current view planning (VP) systems usually adopt an iterative pipeline with next-best-view (NBV) methods that can autonomously perform 3D reconstruction of unknown objects. However, they are slowed down by local path planning, which is improved by our previously proposed set-covering-based network SCVP using one-shot view planning and global path planning. In this work, we propose a combined pipeline that selects a few NBVs before activating the network to improve model completeness. However, this pipeline will result in more views than expected because the SCVP has not been trained from multiview scenarios. To reduce the overall number of views and paths required, we propose a multiview-activated architecture MA-SCVP and an efficient dataset sampling method for view planning based on a long-tail distribution. Ablation studies confirm the optimal network architecture, the sampling method and the number of samples, the NBV method and the number of NBVs in our combined pipeline. Comparative experiments support the claim that our system achieves faster and more complete reconstruction than state-of-the-art systems. For the reference of the community, we make the source codes public.