 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-VMP: Global Optimization for View Motion Planning in Fruit Mapping
Mar 05, 2025Automating labor-intensive tasks such as crop monitoring with robots is essential for enhancing production and conserving resources. However, autonomously monitoring horticulture crops remains challenging due to their complex structures, which often result in fruit occlusions. Existing view planning methods attempt to reduce occlusions but either struggle to achieve adequate coverage or incur high robot motion costs. We introduce a global optimization approach for view motion planning that aims to minimize robot motion costs while maximizing fruit coverage. To this end, we leverage coverage constraints derived from the set covering problem (SCP) within a shortest Hamiltonian path problem (SHPP) formulation. While both SCP and SHPP are well-established, their tailored integration enables a unified framework that computes a global view path with minimized motion while ensuring full coverage of selected targets. Given the NP-hard nature of the problem, we employ a region-prior-based selection of coverage targets and a sparse graph structure to achieve effective optimization outcomes within a limited time. Experiments in simulation demonstrate that our method detects more fruits, enhances surface coverage, and achieves higher volume accuracy than the motion-efficient baseline with a moderate increase in motion cost, while significantly reducing motion costs compared to the coverage-focused baseline. Real-world experiments further confirm the practical applicability of our approach.
Map Space Belief Prediction for Manipulation-Enhanced Mapping
Feb 28, 2025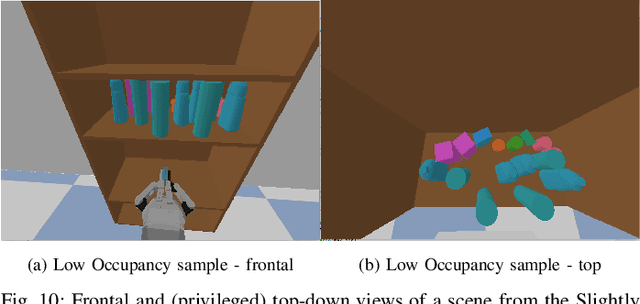
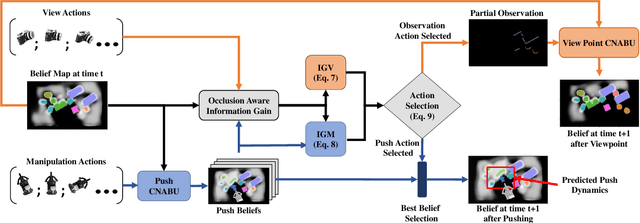
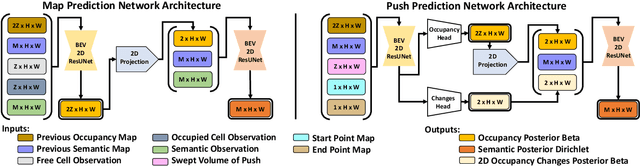

Searching for objects in cluttered environments requires selecting efficient viewpoints and manipulation actions to remove occlusions and reduce uncertainty in object locations, shapes, and categories. In this work, we address the problem of manipulation-enhanced semantic mapping, where a robot has to efficiently identify all objects in a cluttered shelf. Although Partially Observable Markov Decision Processes~(POMDPs) are standard for decision-making under uncertainty, representing unstructured interactive worlds remains challenging in this formalism. To tackle this, we define a POMDP whose belief is summarized by a metric-semantic grid map and propose a novel framework that uses neural networks to perform map-space belief updates to reason efficiently and simultaneously about object geometries, locations, categories, occlusions, and manipulation physics. Further, to enable accurate information gain analysis, the learned belief updates should maintain calibrated estimates of uncertainty. Therefore, we propose Calibrated Neural-Accelerated Belief Updates (CNABUs) to learn a belief propagation model that generalizes to novel scenarios and provides confidence-calibrated predictions for unknown areas. Our experiments show that our novel POMDP planner improves map completeness and accuracy over existing methods in challenging simulations and successfully transfers to real-world cluttered shelves in zero-shot fashion.
Context-Based Meta Reinforcement Learning for Robust and Adaptable Peg-in-Hole Assembly Tasks
Sep 24, 2024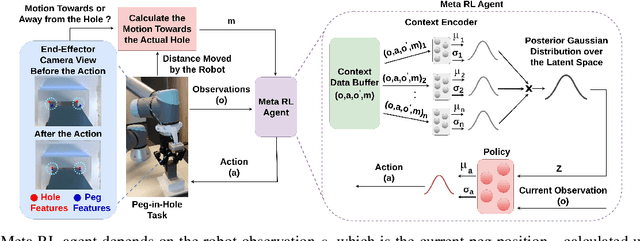
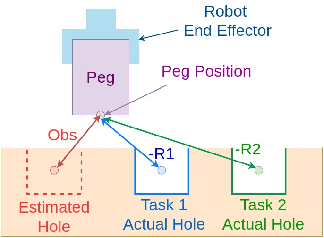
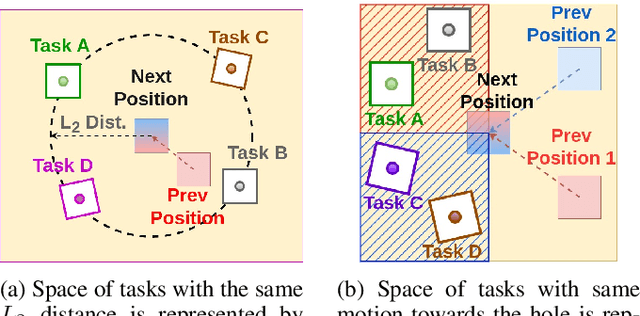
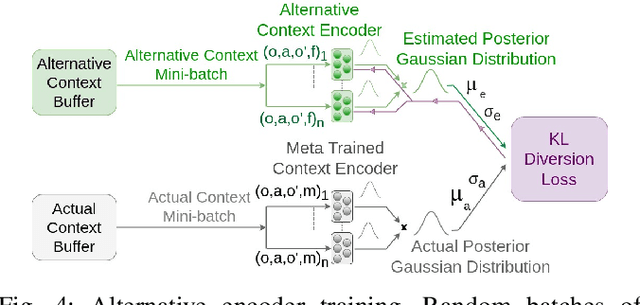
Peg-in-hole assembly in unknown environments is a challenging task due to onboard sensor errors, which result in uncertainty and variations in task parameters such as the hole position and orientation. Meta Reinforcement Learning (Meta RL) has been proposed to mitigate this problem as it learns how to quickly adapt to new tasks with different parameters. However, previous approaches either depend on a sample-inefficient procedure or human demonstrations to perform the task in the real world. Our work modifies the data used by the Meta RL agent and uses simple features that can be easily measured in the real world even with an uncalibrated camera. We further adapt the Meta RL agent to use data from a force/torque sensor, instead of the camera, to perform the assembly, using a small amount of training data. Finally, we propose a fine-tuning method that consistently and safely adapts to out-of-distribution tasks with parameters that differ by a factor of 10 from the training tasks. Our results demonstrate that the proposed data modification significantly enhances the training and adaptation efficiency and enables the agent to achieve 100% success in tasks with different hole positions and orientations. Experiments on a real robot confirm that both camera- and force/torque sensor-equipped agents achieve 100% success in tasks with unknown hole positions, matching their simulation performance and validating the approach's robustness and applicability. Compared to the previous work with sample-inefficient adaptation, our proposed methods are 10 times more sample-efficient in the real-world tasks.
One-Shot View Planning for Fast and Complete Unknown Object Reconstruction
Apr 03, 2023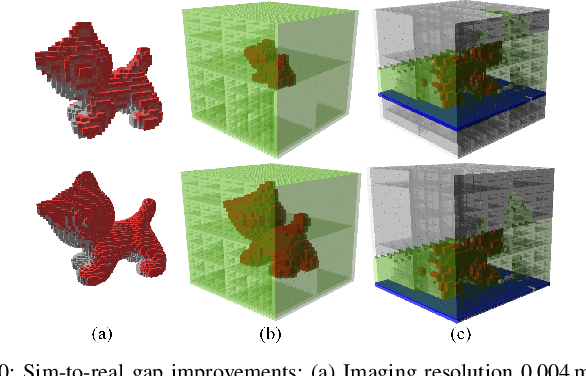
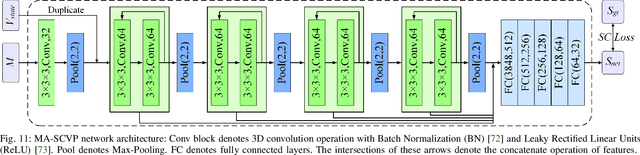


Current view planning (VP) systems usually adopt an iterative pipeline with next-best-view (NBV) methods that can autonomously perform 3D reconstruction of unknown objects. However, they are slowed down by local path planning, which is improved by our previously proposed set-covering-based network SCVP using one-shot view planning and global path planning. In this work, we propose a combined pipeline that selects a few NBVs before activating the network to improve model completeness. However, this pipeline will result in more views than expected because the SCVP has not been trained from multiview scenarios. To reduce the overall number of views and paths required, we propose a multiview-activated architecture MA-SCVP and an efficient dataset sampling method for view planning based on a long-tail distribution. Ablation studies confirm the optimal network architecture, the sampling method and the number of samples, the NBV method and the number of NBVs in our combined pipeline. Comparative experiments support the claim that our system achieves faster and more complete reconstruction than state-of-the-art systems. For the reference of the community, we make the source codes public.
Graph-based View Motion Planning for Fruit Detection
Mar 06, 2023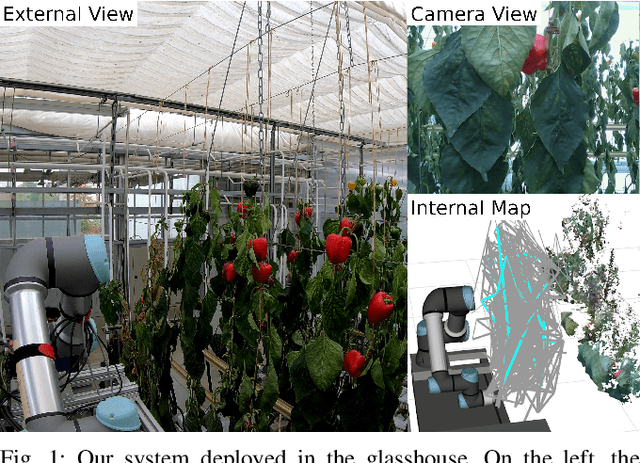
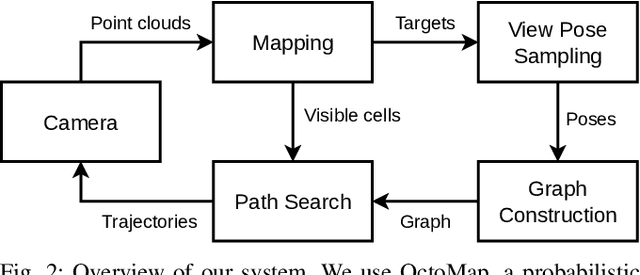
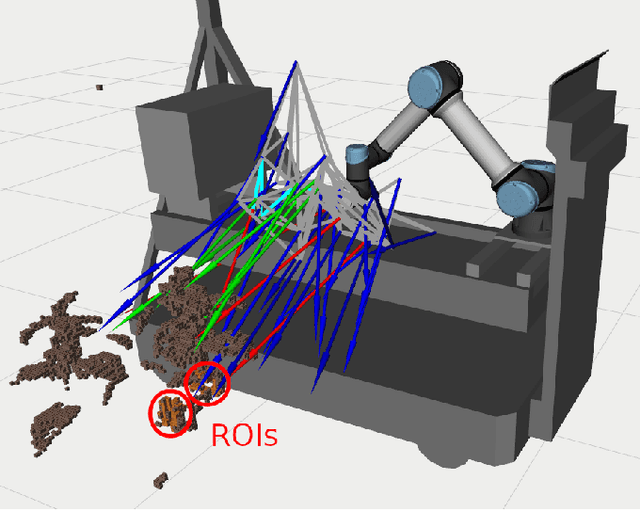
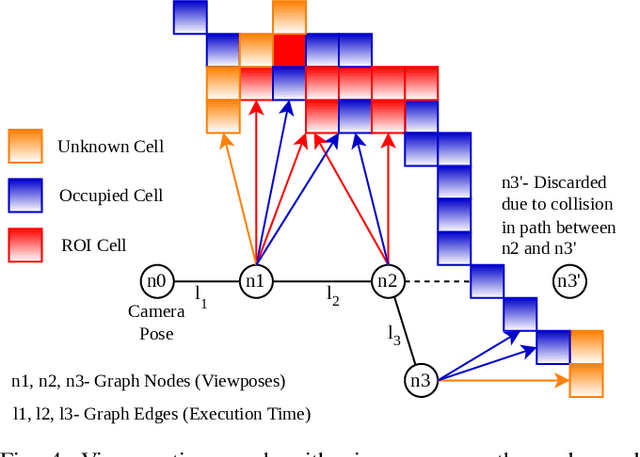
Crop monitoring is crucial for maximizing agricultural productivity and efficiency. However, monitoring large and complex structures such as sweet pepper plants presents significant challenges, especially due to frequent occlusions of the fruits. Traditional next-best view planning can lead to unstructured and inefficient coverage of the crops. To address this, we propose a novel view motion planner that builds a graph network of viable view poses and trajectories between nearby poses, thereby considering robot motion constraints. The planner searches the graphs for view sequences with the highest accumulated information gain, allowing for efficient pepper plant monitoring while minimizing occlusions. The generated view poses aim at both sufficiently covering already detected and discovering new fruits. The graph and the corresponding best view pose sequence are computed with a limited horizon and are adaptively updated in fixed time intervals as the system gathers new information. We demonstrate the effectiveness of our approach through simulated and real-world experiments using a robotic arm equipped with an RGB-D camera and mounted on a trolley. As the experimental results show, our planner produces view pose sequences to systematically cover the crops and leads to increased fruit coverage when given a limited time in comparison to a state-of-the-art single next-best view planner.
Viewpoint Planning based on Shape Completion for Fruit Mapping and Reconstruction
Sep 30, 2022
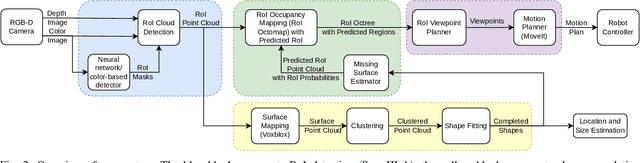
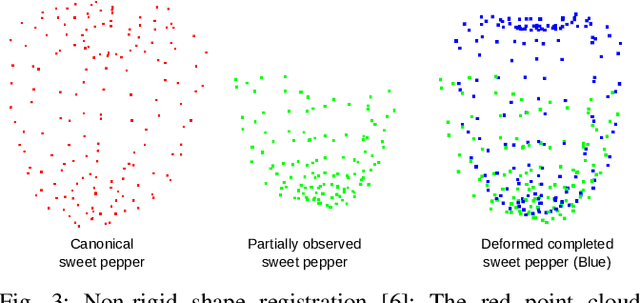
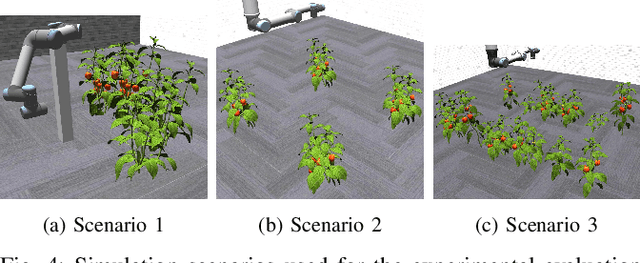
Robotic systems in agriculture do not only enable increasing automation of farming activities but also represent new challenges for robotics due to the unstructured environment and the non-rigid structures of crops. Especially, active perception for fruit mapping and harvesting is a difficult task since occlusions frequently occur and image segmentation provides only limited accuracy on the actual shape of the fruits. In this paper, we present a viewpoint planning approach that explictly uses the shape prediction from collected data to guide the sensor to view as yet unobserved parts of the fruits. We developed a novel pipeline for continuous interaction between prediction and observation to maximize the information gain about sweet pepper fruits. We adapted two different shape prediction approaches, namely parametric superellipsoid fitting and model based non-rigid latent space registration, and integrated them into our Region of Interest (RoI) viewpoint planner. Additionally, we used a new concept of viewpoint dissimilarity to aid the planner to select good viewpoints and for shortening the planning times. Our simulation experiments with a UR5e arm equipped with a Realsense L515 sensor provide a quantitative demonstration of the efficacy of our iterative shape completion based viewpoint planning. In comparative experiments with a state-of-the-art viewpoint planner, we demonstrate improvement not only in the estimation of the fruit sizes, but also in their reconstruction. Finally, we show the viability of our approach for mapping sweet peppers with a real robotic system in a commercial glasshouse.
Fruit Mapping with Shape Completion for Autonomous Crop Monitoring
Mar 29, 2022
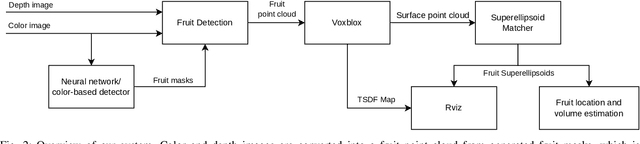
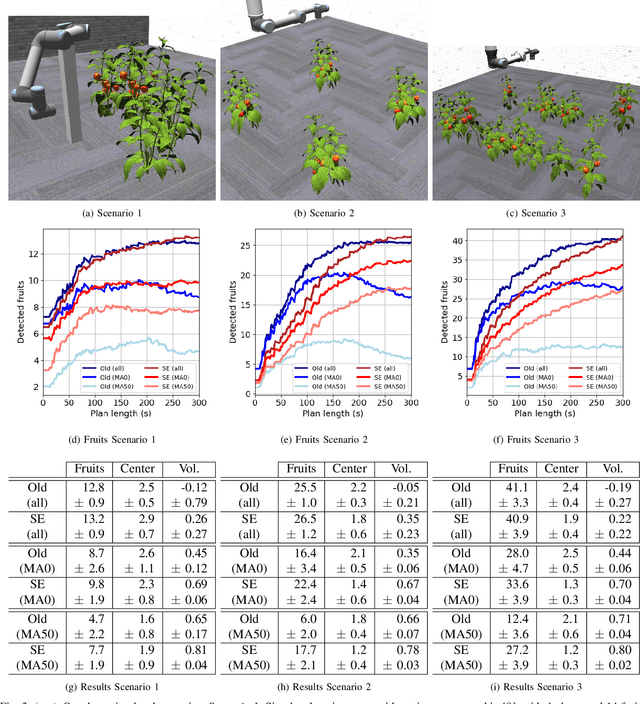
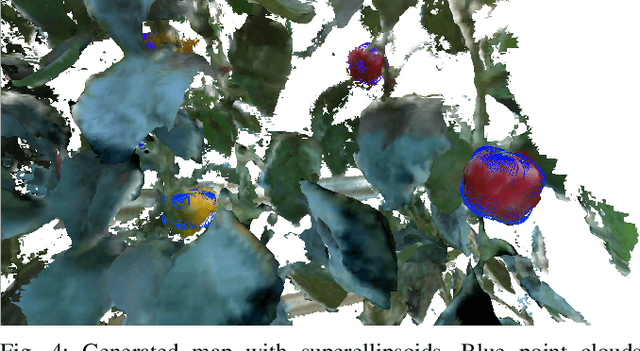
Autonomous crop monitoring is a difficult task due to the complex structure of plants. Occlusions from leaves can make it impossible to obtain complete views about all fruits of, e.g., pepper plants. Therefore, accurately estimating the shape and volume of fruits from partial information is crucial to enable further advanced automation tasks such as yield estimation and automated fruit picking. In this paper, we present an approach for mapping fruits on plants and estimating their shape by matching superellipsoids. Our system segments fruits in images and uses their masks to generate point clouds of the fruits. To combine sequences of acquired point clouds, we utilize a real-time 3D mapping framework and build up a fruit map based on truncated signed distance fields. We cluster fruits from this map and use optimized superellipsoids for matching to obtain accurate shape estimates. In our experiments, we show in various simulated scenarios with a robotic arm equipped with an RGB-D camera that our approach can accurately estimate fruit volumes. Additionally, we provide qualitative results of estimated fruit shapes from data recorded in a commercial glasshouse environment.
Combining Local and Global Viewpoint Planning for Fruit Coverage
Aug 18, 2021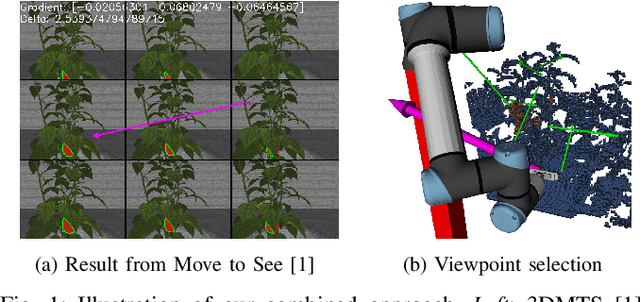
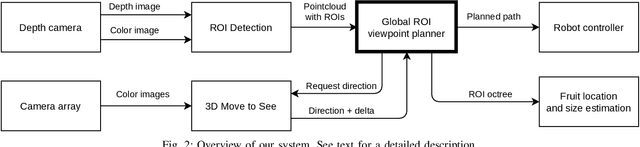
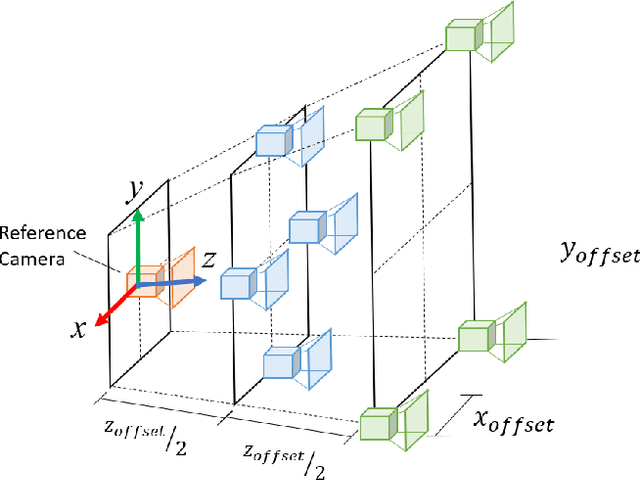

Obtaining 3D sensor data of complete plants or plant parts (e.g., the crop or fruit) is difficult due to their complex structure and a high degree of occlusion. However, especially for the estimation of the position and size of fruits, it is necessary to avoid occlusions as much as possible and acquire sensor information of the relevant parts. Global viewpoint planners exist that suggest a series of viewpoints to cover the regions of interest up to a certain degree, but they usually prioritize global coverage and do not emphasize the avoidance of local occlusions. On the other hand, there are approaches that aim at avoiding local occlusions, but they cannot be used in larger environments since they only reach a local maximum of coverage. In this paper, we therefore propose to combine a local, gradient-based method with global viewpoint planning to enable local occlusion avoidance while still being able to cover large areas. Our simulated experiments with a robotic arm equipped with a camera array as well as an RGB-D camera show that this combination leads to a significantly increased coverage of the regions of interest compared to just applying global coverage planning.
Online Object-Oriented Semantic Mapping and Map Updating with Modular Representations
Nov 13, 2020
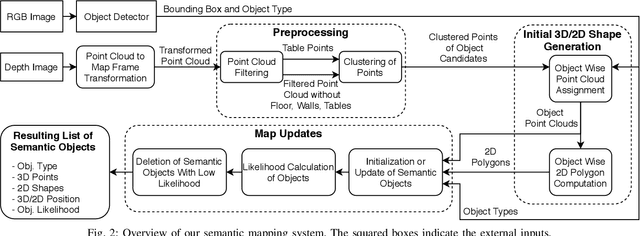

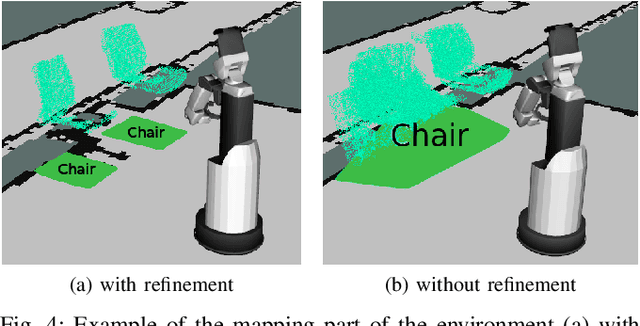
Creating and maintaining an accurate representation of the environment is an essential capability for every service robot. Especially semantic information is important for household robots acting in indoor environments. In this paper, we present a semantic mapping framework with modular map representations. Our system is capable of online mapping and object updating given object detections from RGB-D~data and provides various 2D and 3D~representations of the mapped objects. To undo wrong data association, we perform a refinement step when updating object shapes. Furthermore, we maintain a likelihood for each object to deal with false positive and false negative detections and keep the map updated. Our mapping system is highly efficient and achieves a run time of more than 10 Hz. We evaluated our approach in various environments using two different robots, i.e., a HSR by Toyota and a \mbox{Care-O-Bot-4} by Fraunhofer. As the experimental results demonstrate, our system is able to generate maps that are close to the ground truth and outperforms an existing approach in terms of intersection over union, different distance metrics, and the number of correct object mappings. We plan to publish the code of our system for the final submission.
Viewpoint Planning for Fruit Size and Position Estimation
Oct 31, 2020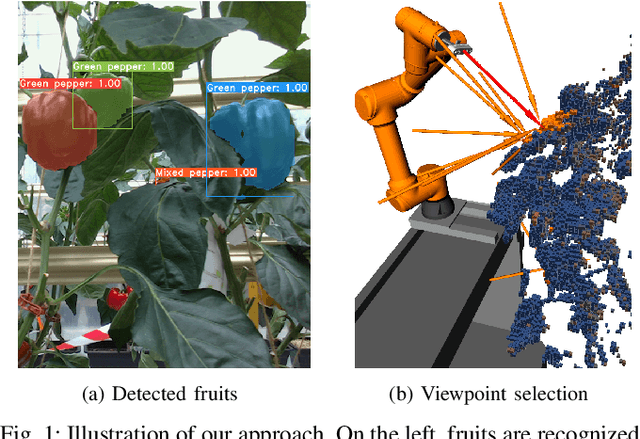
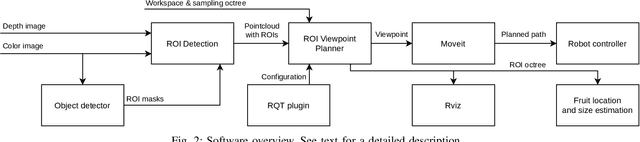


Modern agricultural applications require knowledge about position and size of fruits on plants. However, occlusions from leaves typically make obtaining this information difficult. We present a novel viewpoint planning approach that generates an octree of plants which marks the regions of interests, i.e., fruits. Our method uses this octree to sample viewpoints that increase the information around the fruit regions and estimates their position and size. Our planner is modular and provides different ways of obtaining the regions of interest and sampling candidate viewpoints. We evaluated our approach in simulated scenarios, where we compared the resulting fruit estimations with a known ground truth. The results demonstrate that our approach outperforms two different sampling methods that do not explicitly consider the regions of interest. Furthermore, we showed the real-world applicability by testing the framework on a robotic arm equipped with an RGB-D camera installed on an automated pipe-rail trolley in a capsicum glasshouse.