 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDeID-Toolbox: Face De-Identification Toolbox
Mar 13, 2026Face de-identification (FDeID) aims to remove personally identifiable information from facial images while preserving task-relevant utility attributes such as age, gender, and expression. It is critical for privacy-preserving computer vision, yet the field suffers from fragmented implementations, inconsistent evaluation protocols, and incomparable results across studies. These challenges stem from the inherent complexity of the task: FDeID spans multiple downstream applications (e.g., age estimation, gender recognition, expression analysis) and requires evaluation across three dimensions (e.g., privacy protection, utility preservation, and visual quality), making existing codebases difficult to use and extend. To address these issues, we present FDeID-Toolbox, a comprehensive toolbox designed for reproducible FDeID research. Our toolbox features a modular architecture comprising four core components: (1) standardized data loaders for mainstream benchmark datasets, (2) unified method implementations spanning classical approaches to SOTA generative models, (3) flexible inference pipelines, and (4) systematic evaluation protocols covering privacy, utility, and quality metrics. Through experiments, we demonstrate that FDeID-Toolbox enables fair and reproducible comparison of diverse FDeID methods under consistent conditions.
Home Health System Deployment Experience for Geriatric Care Remote Monitoring
Jan 24, 2026To support aging-in-place, adult children often provide care to their aging parents from a distance. These informal caregivers desire plug-and-play remote care solutions for privacy-preserving continuous monitoring that enabling real-time activity monitoring and intuitive, actionable information. This short paper presents insights from three iterations of deployment experience for remote monitoring system and the iterative improvement in hardware, modeling, and user interface guided by the Geriatric 4Ms framework (matters most, mentation, mobility, and medication). An LLM-assisted solution is developed to balance user experience (privacy-preserving, plug-and-play) and system performance.
RARR : Robust Real-World Activity Recognition with Vibration by Scavenging Near-Surface Audio Online
Aug 28, 2025



One in four people dementia live alone, leading family members to take on caregiving roles from a distance. Many researchers have developed remote monitoring solutions to lessen caregiving needs; however, limitations remain including privacy preserving solutions, activity recognition, and model generalizability to new users and environments. Structural vibration sensor systems are unobtrusive solutions that have been proven to accurately monitor human information, such as identification and activity recognition, in controlled settings by sensing surface vibrations generated by activities. However, when deploying in an end user's home, current solutions require a substantial amount of labeled data for accurate activity recognition. Our scalable solution adapts synthesized data from near-surface acoustic audio to pretrain a model and allows fine tuning with very limited data in order to create a robust framework for daily routine tracking.
A Survey of Foundation Models for IoT: Taxonomy and Criteria-Based Analysis
Jun 13, 2025

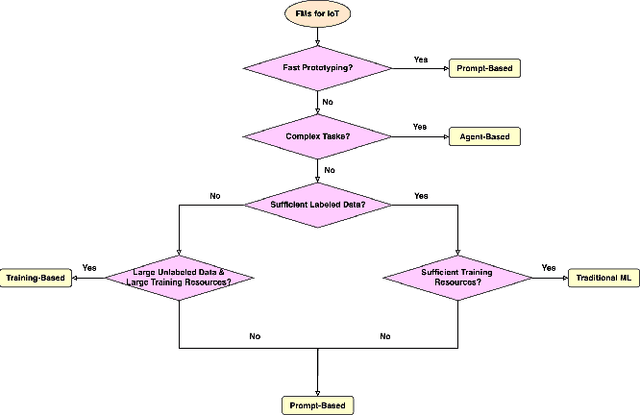
Foundation models have gained growing interest in the IoT domain due to their reduced reliance on labeled data and strong generalizability across tasks, which address key limitations of traditional machine learning approaches. However, most existing foundation model based methods are developed for specific IoT tasks, making it difficult to compare approaches across IoT domains and limiting guidance for applying them to new tasks. This survey aims to bridge this gap by providing a comprehensive overview of current methodologies and organizing them around four shared performance objectives by different domains: efficiency, context-awareness, safety, and security & privacy. For each objective, we review representative works, summarize commonly-used techniques and evaluation metrics. This objective-centric organization enables meaningful cross-domain comparisons and offers practical insights for selecting and designing foundation model based solutions for new IoT tasks. We conclude with key directions for future research to guide both practitioners and researchers in advancing the use of foundation models in IoT applications.
Graph-Based Physics-Guided Urban PM2.5 Air Quality Imputation with Constrained Monitoring Data
Jun 07, 2025This work introduces GraPhy, a graph-based, physics-guided learning framework for high-resolution and accurate air quality modeling in urban areas with limited monitoring data. Fine-grained air quality monitoring information is essential for reducing public exposure to pollutants. However, monitoring networks are often sparse in socioeconomically disadvantaged regions, limiting the accuracy and resolution of air quality modeling. To address this, we propose a physics-guided graph neural network architecture called GraPhy with layers and edge features designed specifically for low-resolution monitoring data. Experiments using data from California's socioeconomically disadvantaged San Joaquin Valley show that GraPhy achieves the overall best performance evaluated by mean squared error (MSE), mean absolute error (MAE), and R-square value (R2), improving the performance by 9%-56% compared to various baseline models. Moreover, GraPhy consistently outperforms baselines across different spatial heterogeneity levels, demonstrating the effectiveness of our model design.
* Accepted by ACM Transactions on Sensor Networks (TOSN) 2025
Facilitating Long Context Understanding via Supervised Chain-of-Thought Reasoning
Feb 18, 2025



Recent advances in Large Language Models (LLMs) have enabled them to process increasingly longer sequences, ranging from 2K to 2M tokens and even beyond. However, simply extending the input sequence length does not necessarily lead to effective long-context understanding. In this study, we integrate Chain-of-Thought (CoT) reasoning into LLMs in a supervised manner to facilitate effective long-context understanding. To achieve this, we introduce LongFinanceQA, a synthetic dataset in the financial domain designed to improve long-context reasoning. Unlike existing long-context synthetic data, LongFinanceQA includes intermediate CoT reasoning before the final conclusion, which encourages LLMs to perform explicit reasoning, improving accuracy and interpretability in long-context understanding. To generate synthetic CoT reasoning, we propose Property-driven Agentic Inference (PAI), an agentic framework that simulates human-like reasoning steps, including property extraction, retrieval, and summarization. We evaluate PAI's reasoning capabilities by assessing GPT-4o-mini w/ PAI on the Loong benchmark, outperforming standard GPT-4o-mini by 20.0%. Furthermore, we fine-tune LLaMA-3.1-8B-Instruct on LongFinanceQA, achieving a 24.6% gain on Loong's financial subset.
Local Features Meet Stochastic Anonymization: Revolutionizing Privacy-Preserving Face Recognition for Black-Box Models
Dec 11, 2024



The task of privacy-preserving face recognition (PPFR) currently faces two major unsolved challenges: (1) existing methods are typically effective only on specific face recognition models and struggle to generalize to black-box face recognition models; (2) current methods employ data-driven reversible representation encoding for privacy protection, making them susceptible to adversarial learning and reconstruction of the original image. We observe that face recognition models primarily rely on local features ({e.g., face contour, skin texture, and so on) for identification. Thus, by disrupting global features while enhancing local features, we achieve effective recognition even in black-box environments. Additionally, to prevent adversarial models from learning and reversing the anonymization process, we adopt an adversarial learning-based approach with irreversible stochastic injection to ensure the stochastic nature of the anonymization. Experimental results demonstrate that our method achieves an average recognition accuracy of 94.21\% on black-box models, outperforming existing methods in both privacy protection and anti-reconstruction capabilities.
Systematic Evaluation of LLM-as-a-Judge in LLM Alignment Tasks: Explainable Metrics and Diverse Prompt Templates
Aug 23, 2024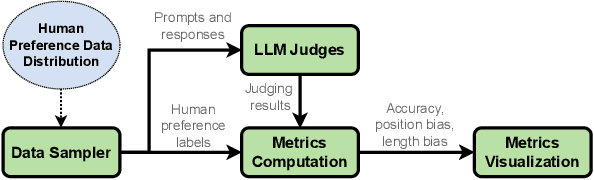

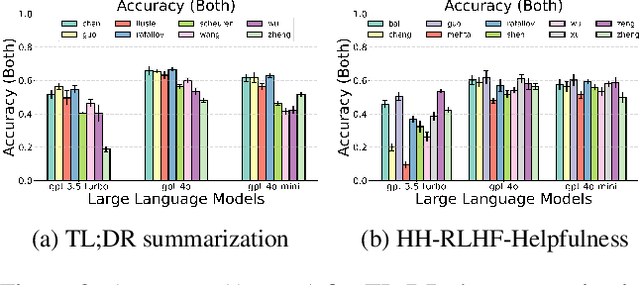
Alignment approaches such as RLHF and DPO are actively investigated to align large language models (LLMs) with human preferences. Commercial large language models (LLMs) like GPT-4 have been recently employed to evaluate and compare different LLM alignment approaches. These models act as surrogates for human evaluators due to their promising abilities to approximate human preferences with remarkably faster feedback and lower costs. This methodology is referred to as LLM-as-a-judge. However, concerns regarding its reliability have emerged, attributed to LLM judges' biases and inconsistent decision-making. Previous research has sought to develop robust evaluation frameworks for assessing the reliability of LLM judges and their alignment with human preferences. However, the employed evaluation metrics often lack adequate explainability and fail to address the internal inconsistency of LLMs. Additionally, existing studies inadequately explore the impact of various prompt templates when applying LLM-as-a-judge methods, which leads to potentially inconsistent comparisons between different alignment algorithms. In this work, we systematically evaluate LLM judges on alignment tasks (e.g. summarization) by defining evaluation metrics with improved theoretical interpretability and disentangling reliability metrics with LLM internal inconsistency. We develop a framework to evaluate, compare, and visualize the reliability and alignment of LLM judges to provide informative observations that help choose LLM judges for alignment tasks. Our results indicate a significant impact of prompt templates on LLM judge performance, as well as a mediocre alignment level between the tested LLM judges and human evaluators.
Temporally Multi-Scale Sparse Self-Attention for Physical Activity Data Imputation
Jun 27, 2024Wearable sensors enable health researchers to continuously collect data pertaining to the physiological state of individuals in real-world settings. However, such data can be subject to extensive missingness due to a complex combination of factors. In this work, we study the problem of imputation of missing step count data, one of the most ubiquitous forms of wearable sensor data. We construct a novel and large scale data set consisting of a training set with over 3 million hourly step count observations and a test set with over 2.5 million hourly step count observations. We propose a domain knowledge-informed sparse self-attention model for this task that captures the temporal multi-scale nature of step-count data. We assess the performance of the model relative to baselines and conduct ablation studies to verify our specific model designs.
On Support Relations Inference and Scene Hierarchy Graph Construction from Point Cloud in Clustered Environments
Apr 22, 2024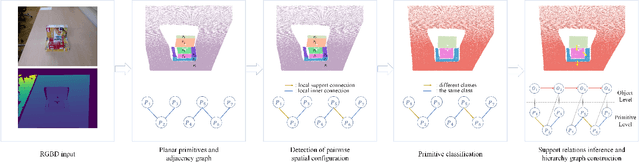

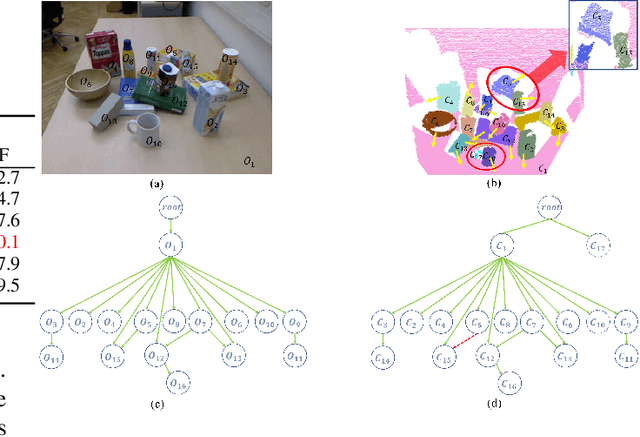

Over the years, scene understanding has attracted a growing interest in computer vision, providing the semantic and physical scene information necessary for robots to complete some particular tasks autonomously. In 3D scenes, rich spatial geometric and topological information are often ignored by RGB-based approaches for scene understanding. In this study, we develop a bottom-up approach for scene understanding that infers support relations between objects from a point cloud. Our approach utilizes the spatial topology information of the plane pairs in the scene, consisting of three major steps. 1) Detection of pairwise spatial configuration: dividing primitive pairs into local support connection and local inner connection; 2) primitive classification: a combinatorial optimization method applied to classify primitives; and 3) support relations inference and hierarchy graph construction: bottom-up support relations inference and scene hierarchy graph construction containing primitive level and object level. Through experiments, we demonstrate that the algorithm achieves excellent performance in primitive classification and support relations inference. Additionally, we show that the scene hierarchy graph contains rich geometric and topological information of objects, and it possesses great scalability for scene understanding.