 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Privacy-Preserving Visual Perception for Robot Navigation Based on User Privacy Preferences
Apr 07, 2026Visual navigation is a fundamental capability of mobile service robots, yet the onboard cameras required for such navigation can capture privacy-sensitive information and raise user privacy concerns. Existing approaches to privacy-preserving navigation-oriented visual perception have largely been driven by technical considerations, with limited grounding in user privacy preferences. In this work, we propose a user-centered approach to designing privacy-preserving visual perception for robot navigation. To investigate how user privacy preferences can inform such design, we conducted two user studies. The results show that users prefer privacy-preserving visual abstractions and capture-time low-resolution preservation mechanisms: their preferred RGB resolution depends both on the desired privacy level and robot proximity during navigation. Based on these findings, we further derive a user-configurable distance-to-resolution privacy policy for privacy-preserving robot visual navigation.
Temporal-Prior-Guided View Planning for Periodic 3D Plant Reconstruction
Oct 08, 2025Periodic 3D reconstruction is essential for crop monitoring, but costly when each cycle restarts from scratch, wasting resources and ignoring information from previous captures. We propose temporal-prior-guided view planning for periodic plant reconstruction, in which a previously reconstructed model of the same plant is non-rigidly aligned to a new partial observation to form an approximation of the current geometry. To accommodate plant growth, we inflate this approximation and solve a set covering optimization problem to compute a minimal set of views. We integrated this method into a complete pipeline that acquires one additional next-best view before registration for robustness and then plans a globally shortest path to connect the planned set of views and outputs the best view sequence. Experiments on maize and tomato under hemisphere and sphere view spaces show that our system maintains or improves surface coverage while requiring fewer views and comparable movement cost compared to state-of-the-art baselines.
Privacy Risks of Robot Vision: A User Study on Image Modalities and Resolution
May 12, 2025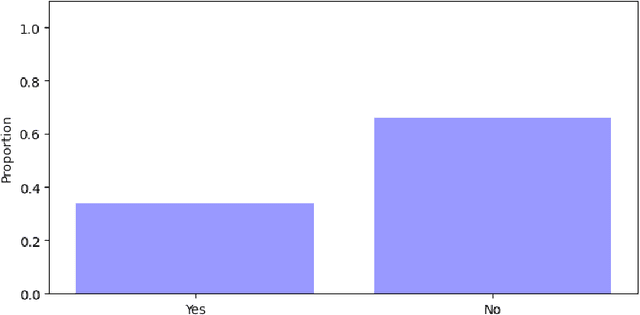

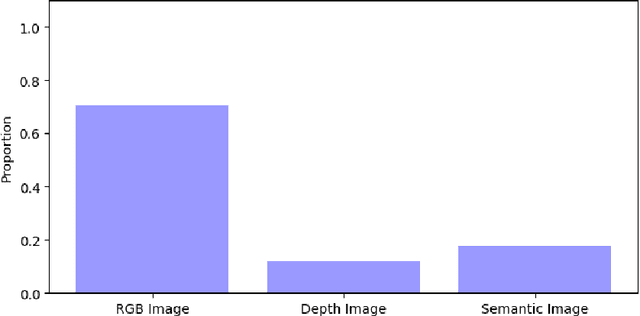
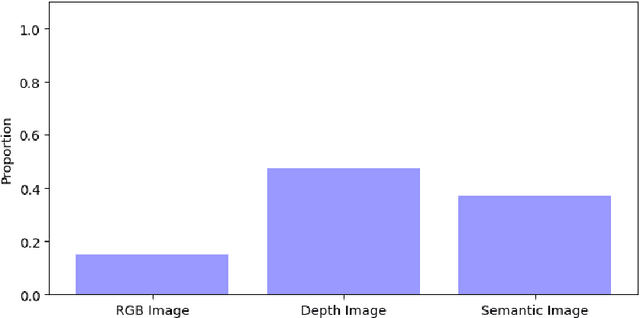
User privacy is a crucial concern in robotic applications, especially when mobile service robots are deployed in personal or sensitive environments. However, many robotic downstream tasks require the use of cameras, which may raise privacy risks. To better understand user perceptions of privacy in relation to visual data, we conducted a user study investigating how different image modalities and image resolutions affect users' privacy concerns. The results show that depth images are broadly viewed as privacy-safe, and a similarly high proportion of respondents feel the same about semantic segmentation images. Additionally, the majority of participants consider 32*32 resolution RGB images to be almost sufficiently privacy-preserving, while most believe that 16*16 resolution can fully guarantee privacy protection.
DM-OSVP++: One-Shot View Planning Using 3D Diffusion Models for Active RGB-Based Object Reconstruction
Apr 16, 2025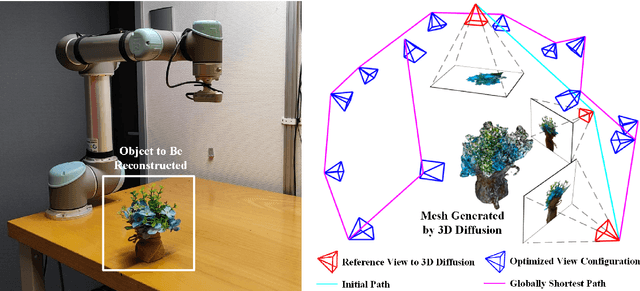


Active object reconstruction is crucial for many robotic applications. A key aspect in these scenarios is generating object-specific view configurations to obtain informative measurements for reconstruction. One-shot view planning enables efficient data collection by predicting all views at once, eliminating the need for time-consuming online replanning. Our primary insight is to leverage the generative power of 3D diffusion models as valuable prior information. By conditioning on initial multi-view images, we exploit the priors from the 3D diffusion model to generate an approximate object model, serving as the foundation for our view planning. Our novel approach integrates the geometric and textural distributions of the object model into the view planning process, generating views that focus on the complex parts of the object to be reconstructed. We validate the proposed active object reconstruction system through both simulation and real-world experiments, demonstrating the effectiveness of using 3D diffusion priors for one-shot view planning.
EvidMTL: Evidential Multi-Task Learning for Uncertainty-Aware Semantic Surface Mapping from Monocular RGB Images
Mar 06, 2025For scene understanding in unstructured environments, an accurate and uncertainty-aware metric-semantic mapping is required to enable informed action selection by autonomous systems.Existing mapping methods often suffer from overconfident semantic predictions, and sparse and noisy depth sensing, leading to inconsistent map representations. In this paper, we therefore introduce EvidMTL, a multi-task learning framework that uses evidential heads for depth estimation and semantic segmentation, enabling uncertainty-aware inference from monocular RGB images. To enable uncertainty-calibrated evidential multi-task learning, we propose a novel evidential depth loss function that jointly optimizes the belief strength of the depth prediction in conjunction with evidential segmentation loss. Building on this, we present EvidKimera, an uncertainty-aware semantic surface mapping framework, which uses evidential depth and semantics prediction for improved 3D metric-semantic consistency. We train and evaluate EvidMTL on the NYUDepthV2 and assess its zero-shot performance on ScanNetV2, demonstrating superior uncertainty estimation compared to conventional approaches while maintaining comparable depth estimation and semantic segmentation. In zero-shot mapping tests on ScanNetV2, EvidKimera outperforms Kimera in semantic surface mapping accuracy and consistency, highlighting the benefits of uncertainty-aware mapping and underscoring its potential for real-world robotic applications.
GO-VMP: Global Optimization for View Motion Planning in Fruit Mapping
Mar 05, 2025Automating labor-intensive tasks such as crop monitoring with robots is essential for enhancing production and conserving resources. However, autonomously monitoring horticulture crops remains challenging due to their complex structures, which often result in fruit occlusions. Existing view planning methods attempt to reduce occlusions but either struggle to achieve adequate coverage or incur high robot motion costs. We introduce a global optimization approach for view motion planning that aims to minimize robot motion costs while maximizing fruit coverage. To this end, we leverage coverage constraints derived from the set covering problem (SCP) within a shortest Hamiltonian path problem (SHPP) formulation. While both SCP and SHPP are well-established, their tailored integration enables a unified framework that computes a global view path with minimized motion while ensuring full coverage of selected targets. Given the NP-hard nature of the problem, we employ a region-prior-based selection of coverage targets and a sparse graph structure to achieve effective optimization outcomes within a limited time. Experiments in simulation demonstrate that our method detects more fruits, enhances surface coverage, and achieves higher volume accuracy than the motion-efficient baseline with a moderate increase in motion cost, while significantly reducing motion costs compared to the coverage-focused baseline. Real-world experiments further confirm the practical applicability of our approach.
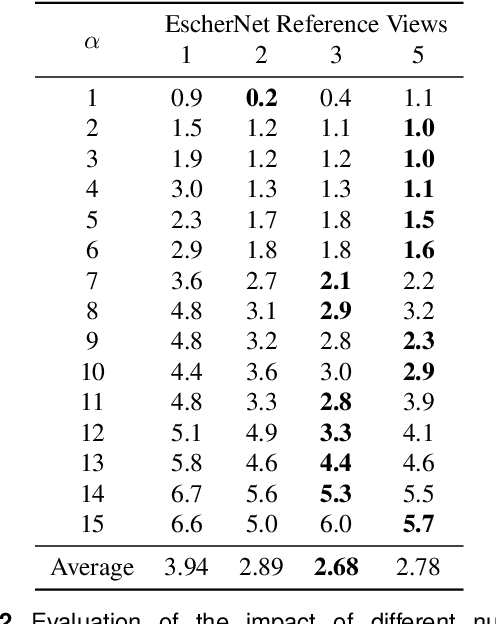
Safe Leaf Manipulation for Accurate Shape and Pose Estimation of Occluded Fruits
Sep 25, 2024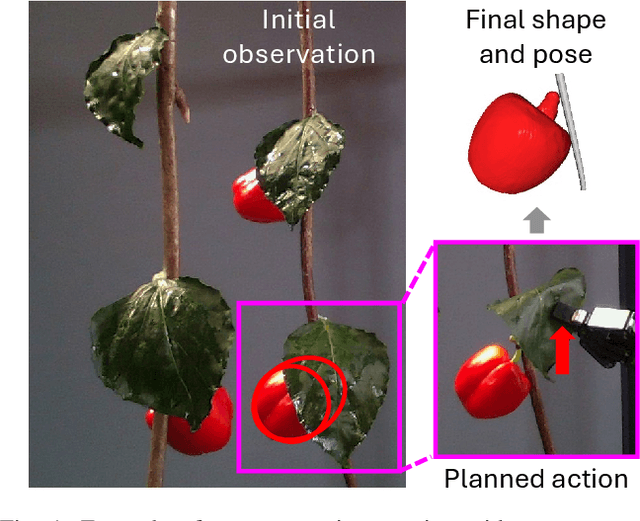
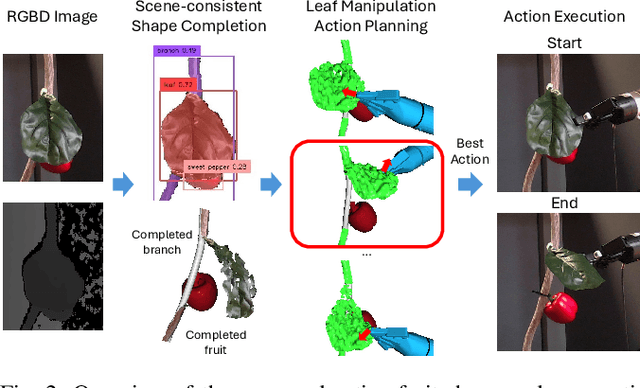

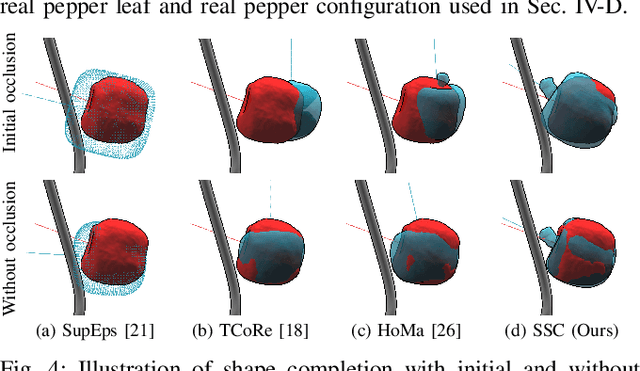
Fruit monitoring plays an important role in crop management, and rising global fruit consumption combined with labor shortages necessitates automated monitoring with robots. However, occlusions from plant foliage often hinder accurate shape and pose estimation. Therefore, we propose an active fruit shape and pose estimation method that physically manipulates occluding leaves to reveal hidden fruits. This paper introduces a framework that plans robot actions to maximize visibility and minimize leaf damage. We developed a novel scene-consistent shape completion technique to improve fruit estimation under heavy occlusion and utilize a perception-driven deformation graph model to predict leaf deformation during planning. Experiments on artificial and real sweet pepper plants demonstrate that our method enables robots to safely move leaves aside, exposing fruits for accurate shape and pose estimation, outperforming baseline methods. Project page: https://shaoxiongyao.github.io/lmap-ssc/.
Exploiting Priors from 3D Diffusion Models for RGB-Based One-Shot View Planning
Mar 25, 2024
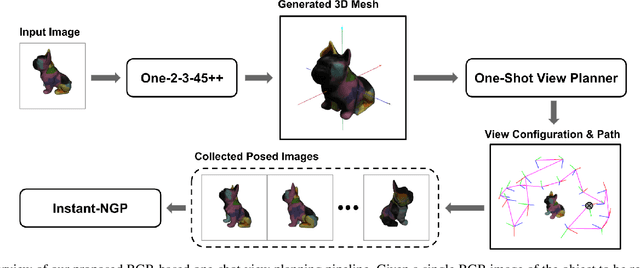

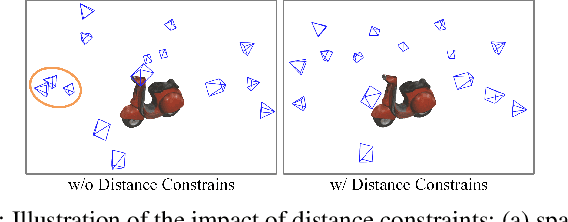
Object reconstruction is relevant for many autonomous robotic tasks that require interaction with the environment. A key challenge in such scenarios is planning view configurations to collect informative measurements for reconstructing an initially unknown object. One-shot view planning enables efficient data collection by predicting view configurations and planning the globally shortest path connecting all views at once. However, geometric priors about the object are required to conduct one-shot view planning. In this work, we propose a novel one-shot view planning approach that utilizes the powerful 3D generation capabilities of diffusion models as priors. By incorporating such geometric priors into our pipeline, we achieve effective one-shot view planning starting with only a single RGB image of the object to be reconstructed. Our planning experiments in simulation and real-world setups indicate that our approach balances well between object reconstruction quality and movement cost.
Safe Multi-Agent Reinforcement Learning for Formation Control without Individual Reference Targets
Dec 20, 2023



In recent years, formation control of unmanned vehicles has received considerable interest, driven by the progress in autonomous systems and the imperative for multiple vehicles to carry out diverse missions. In this paper, we address the problem of behavior-based formation control of mobile robots, where we use safe multi-agent reinforcement learning~(MARL) to ensure the safety of the robots by eliminating all collisions during training and execution. To ensure safety, we implemented distributed model predictive control safety filters to override unsafe actions. We focus on achieving behavior-based formation without having individual reference targets for the robots, and instead use targets for the centroid of the formation. This formulation facilitates the deployment of formation control on real robots and improves the scalability of our approach to more robots. The task cannot be addressed through optimization-based controllers without specific individual reference targets for the robots and information about the relative locations of each robot to the others. That is why, for our formulation we use MARL to train the robots. Moreover, in order to account for the interactions between the agents, we use attention-based critics to improve the training process. We train the agents in simulation and later on demonstrate the resulting behavior of our approach on real Turtlebot robots. We show that despite the agents having very limited information, we can still safely achieve the desired behavior.
How Many Views Are Needed to Reconstruct an Unknown Object Using NeRF?
Oct 01, 2023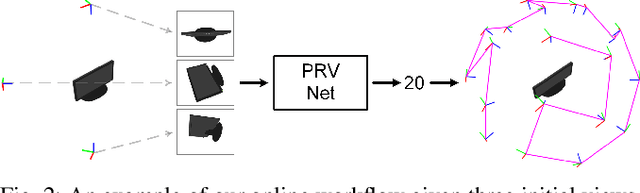
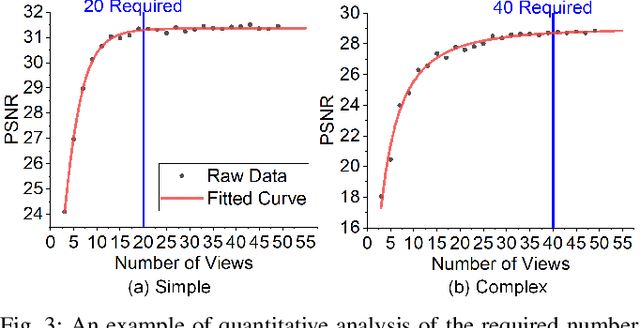
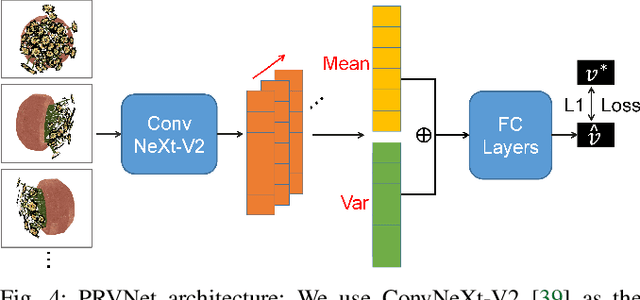

Neural Radiance Fields (NeRFs) are gaining significant interest for online active object reconstruction due to their exceptional memory efficiency and requirement for only posed RGB inputs. Previous NeRF-based view planning methods exhibit computational inefficiency since they rely on an iterative paradigm, consisting of (1) retraining the NeRF when new images arrive; and (2) planning a path to the next best view only. To address these limitations, we propose a non-iterative pipeline based on the Prediction of the Required number of Views (PRV). The key idea behind our approach is that the required number of views to reconstruct an object depends on its complexity. Therefore, we design a deep neural network, named PRVNet, to predict the required number of views, allowing us to tailor the data acquisition based on the object complexity and plan a globally shortest path. To train our PRVNet, we generate supervision labels using the ShapeNet dataset. Simulated experiments show that our PRV-based view planning method outperforms baselines, achieving good reconstruction quality while significantly reducing movement cost and planning time. We further justify the generalization ability of our approach in a real-world experiment.