 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVPO: From Anchored Cues to Self-Reasoning for Long-Form Video Preference Optimization
Feb 02, 2026We present LongVPO, a novel two-stage Direct Preference Optimization framework that enables short-context vision-language models to robustly understand ultra-long videos without any long-video annotations. In Stage 1, we synthesize preference triples by anchoring questions to individual short clips, interleaving them with distractors, and applying visual-similarity and question-specificity filtering to mitigate positional bias and ensure unambiguous supervision. We also approximate the reference model's scoring over long contexts by evaluating only the anchor clip, reducing computational overhead. In Stage 2, we employ a recursive captioning pipeline on long videos to generate scene-level metadata, then use a large language model to craft multi-segment reasoning queries and dispreferred responses, aligning the model's preferences through multi-segment reasoning tasks. With only 16K synthetic examples and no costly human labels, LongVPO outperforms the state-of-the-art open-source models on multiple long-video benchmarks, while maintaining strong short-video performance (e.g., on MVBench), offering a scalable paradigm for efficient long-form video understanding.
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Apr 10, 2025Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay
Dec 05, 2024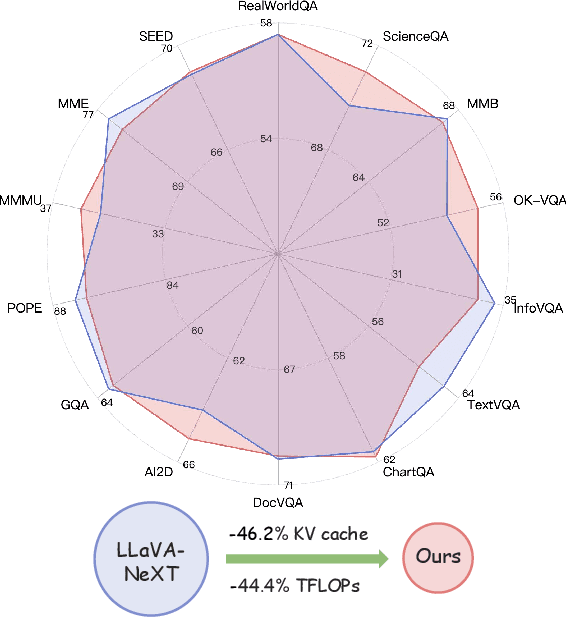



Despite the remarkable performance of multimodal large language models (MLLMs) across diverse tasks, the substantial training and inference costs impede their advancement. The majority of computation stems from the overwhelming volume of vision tokens processed by the transformer decoder. In this paper, we propose to build efficient MLLMs by leveraging the Mixture-of-Depths (MoD) mechanism, where each transformer decoder layer selects essential vision tokens to process while skipping redundant ones. However, integrating MoD into MLLMs is non-trivial. To address the challenges of training and inference stability as well as limited training data, we adapt the MoD module with two novel designs: tanh-gated weight normalization (TanhNorm) and symmetric token reweighting (STRing). Moreover, we observe that vision tokens exhibit higher redundancy in deeper layer and thus design a progressive ratio decay (PRD) strategy, which gradually reduces the token retention ratio layer by layer, employing a shifted cosine schedule. This crucial design fully unleashes the potential of MoD, significantly boosting the efficiency and performance of our models. To validate the effectiveness of our approach, we conduct extensive experiments with two baseline models across 14 benchmarks. Our model, p-MoD, matches or even surpasses the performance of the baseline models, with only 55.6% TFLOPs and 53.8% KV cache storage during inference, and 77.7% GPU hours during training.
Synthetic Aperture Radar Image Change Detection via Layer Attention-Based Noise-Tolerant Network
Aug 09, 2022



Recently, change detection methods for synthetic aperture radar (SAR) images based on convolutional neural networks (CNN) have gained increasing research attention. However, existing CNN-based methods neglect the interactions among multilayer convolutions, and errors involved in the preclassification restrict the network optimization. To this end, we proposed a layer attention-based noise-tolerant network, termed LANTNet. In particular, we design a layer attention module that adaptively weights the feature of different convolution layers. In addition, we design a noise-tolerant loss function that effectively suppresses the impact of noisy labels. Therefore, the model is insensitive to noisy labels in the preclassification results. The experimental results on three SAR datasets show that the proposed LANTNet performs better compared to several state-of-the-art methods. The source codes are available at https://github.com/summitgao/LANTNet