 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture-Aware Reinforcement Learning Makes Sliding-Window Attention Competitive in Math Reasoning
Jun 10, 2026The rapid progress of reasoning and agentic large language models (LLMs) has increased the demand for long-context inference, but self-attention (SA) scales quadratically with context length. To address this, we study SWARR (Sliding-Window Attention with Reinforced Adaptation for Math Reasoning), a practical recipe for adapting SWA models to mathematical reasoning. SWARR has two stages: (1) efficient conversion from a pretrained SA model to SWA with supervised fine-tuning (SFT), which avoids pretraining a new base model, and (2) policy adaptation with reinforcement learning (RL). We find that SWA still underperforms SA after SFT, and we hypothesize that this gap is caused in part by a data-architecture mismatch: most SFT data are prepared for SA models and may contain long-range dependencies that are difficult for SWA to model. Because on-policy RL optimizes self-generated trajectories under the SWA constraint, it can adapt trajectories to better match SWA. Experiments on mathematical reasoning benchmarks show that this recipe substantially narrows the gap between SWA and SA, recovering much of the accuracy lost during SWA conversion while preserving the efficiency benefits of linear-complexity attention. Our central contribution is the empirical finding that RL changes the conclusion one would draw from conversion and SFT alone about SWA's viability for math reasoning.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
Jul 22, 2025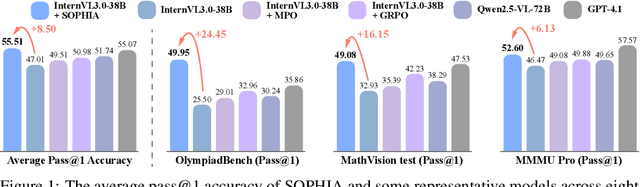
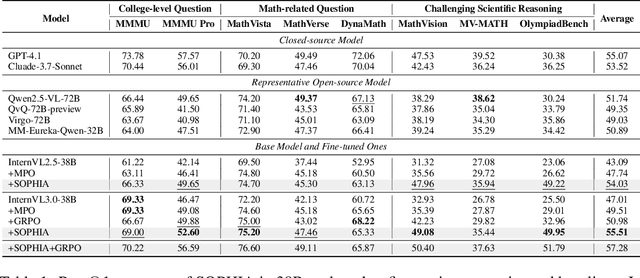
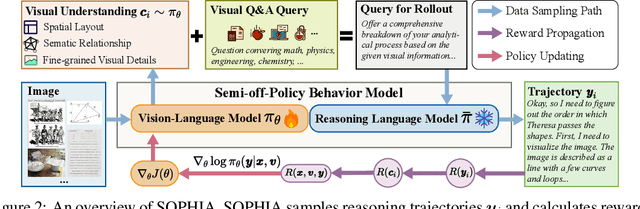
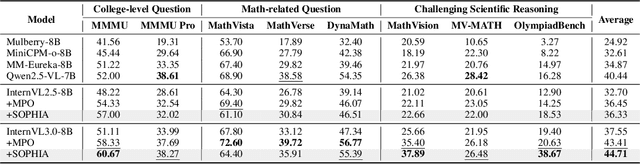
Enhancing large vision-language models (LVLMs) with visual slow-thinking reasoning is crucial for solving complex multimodal tasks. However, since LVLMs are mainly trained with vision-language alignment, it is difficult to adopt on-policy reinforcement learning (RL) to develop the slow thinking ability because the rollout space is restricted by its initial abilities. Off-policy RL offers a way to go beyond the current policy, but directly distilling trajectories from external models may cause visual hallucinations due to mismatched visual perception abilities across models. To address these issues, this paper proposes SOPHIA, a simple and scalable Semi-Off-Policy RL for vision-language slow-tHInking reAsoning. SOPHIA builds a semi-off-policy behavior model by combining on-policy visual understanding from a trainable LVLM with off-policy slow-thinking reasoning from a language model, assigns outcome-based rewards to reasoning, and propagates visual rewards backward. Then LVLM learns slow-thinking reasoning ability from the obtained reasoning trajectories using propagated rewards via off-policy RL algorithms. Extensive experiments with InternVL2.5 and InternVL3.0 with 8B and 38B sizes show the effectiveness of SOPHIA. Notably, SOPHIA improves InternVL3.0-38B by 8.50% in average, reaching state-of-the-art performance among open-source LVLMs on multiple multimodal reasoning benchmarks, and even outperforms some closed-source models (e.g., GPT-4.1) on the challenging MathVision and OlympiadBench, achieving 49.08% and 49.95% pass@1 accuracy, respectively. Analysis shows SOPHIA outperforms supervised fine-tuning and direct on-policy RL methods, offering a better policy initialization for further on-policy training.
RIG: Synergizing Reasoning and Imagination in End-to-End Generalist Policy
Mar 31, 2025Reasoning before action and imagining potential outcomes (i.e., world models) are essential for embodied agents operating in complex open-world environments. Yet, prior work either incorporates only one of these abilities in an end-to-end agent or integrates multiple specialized models into an agent system, limiting the learning efficiency and generalization of the policy. Thus, this paper makes the first attempt to synergize Reasoning and Imagination in an end-to-end Generalist policy, termed RIG. To train RIG in an end-to-end manner, we construct a data pipeline that progressively integrates and enriches the content of imagination and reasoning in the trajectories collected from existing agents. The joint learning of reasoning and next image generation explicitly models the inherent correlation between reasoning, action, and dynamics of environments, and thus exhibits more than $17\times$ sample efficiency improvements and generalization in comparison with previous works. During inference, RIG first reasons about the next action, produces potential action, and then predicts the action outcomes, which offers the agent a chance to review and self-correct based on the imagination before taking real actions. Experimental results show that the synergy of reasoning and imagination not only improves the robustness, generalization, and interoperability of generalist policy but also enables test-time scaling to enhance overall performance.
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025
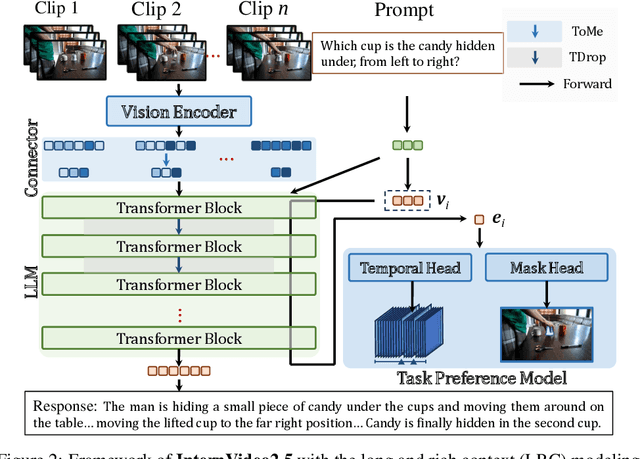
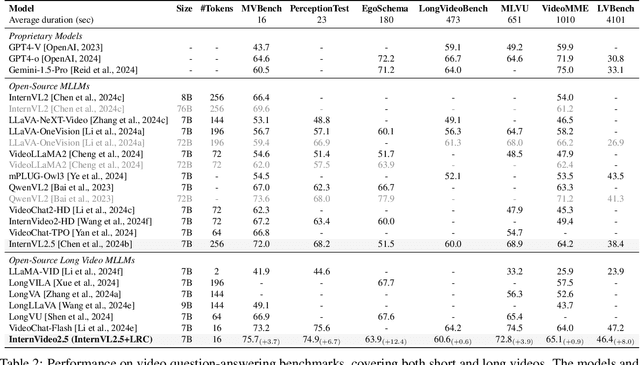
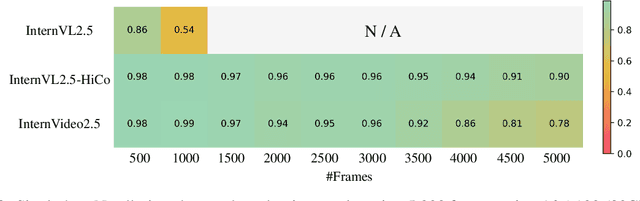
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024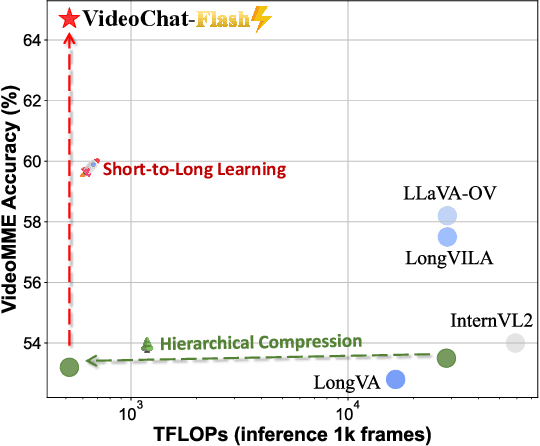
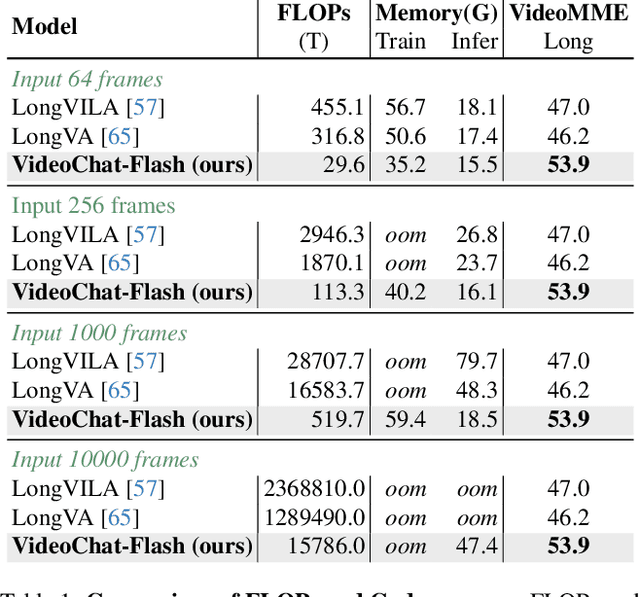

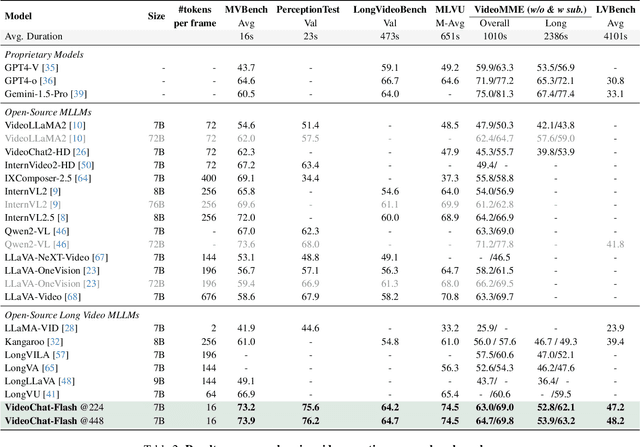
Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.
Differentiable Model Scaling using Differentiable Topk
May 12, 2024



Over the past few years, as large language models have ushered in an era of intelligence emergence, there has been an intensified focus on scaling networks. Currently, many network architectures are designed manually, often resulting in sub-optimal configurations. Although Neural Architecture Search (NAS) methods have been proposed to automate this process, they suffer from low search efficiency. This study introduces Differentiable Model Scaling (DMS), increasing the efficiency for searching optimal width and depth in networks. DMS can model both width and depth in a direct and fully differentiable way, making it easy to optimize. We have evaluated our DMS across diverse tasks, ranging from vision tasks to NLP tasks and various network architectures, including CNNs and Transformers. Results consistently indicate that our DMS can find improved structures and outperforms state-of-the-art NAS methods. Specifically, for image classification on ImageNet, our DMS improves the top-1 accuracy of EfficientNet-B0 and Deit-Tiny by 1.4% and 0.6%, respectively, and outperforms the state-of-the-art zero-shot NAS method, ZiCo, by 1.3% while requiring only 0.4 GPU days for searching. For object detection on COCO, DMS improves the mAP of Yolo-v8-n by 2.0%. For language modeling, our pruned Llama-7B outperforms the prior method with lower perplexity and higher zero-shot classification accuracy. We will release our code in the future.
Double Permutation Equivariance for Knowledge Graph Completion
Feb 02, 2023



This work provides a formalization of Knowledge Graphs (KGs) as a new class of graphs that we denote doubly exchangeable attributed graphs, where node and pairwise (joint 2-node) representations must be equivariant to permutations of both node ids and edge (& node) attributes (relations & node features). Double-permutation equivariant KG representations open a new research direction in KGs. We show that this equivariance imposes a structural representation of relations that allows neural networks to perform complex logical reasoning tasks in KGs. Finally, we introduce a general blueprint for such equivariant representations and test a simple GNN-based double-permutation equivariant neural architecture that achieve 100% Hits@10 test accuracy in both the WN18RRv1 and NELL995v1 inductive KG completion tasks, and can accurately perform logical reasoning tasks that no existing methods can perform, to the best of our knowledge.