 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Aug 29, 2025

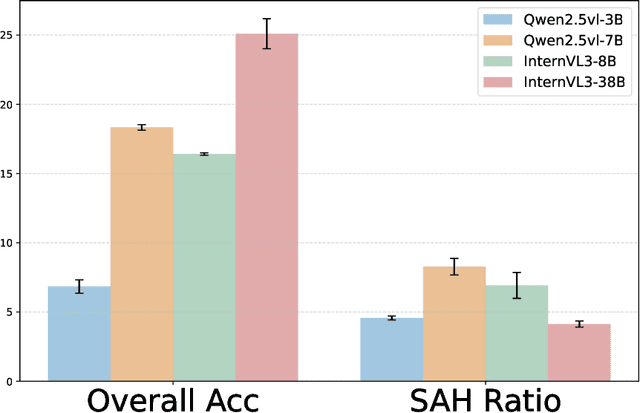
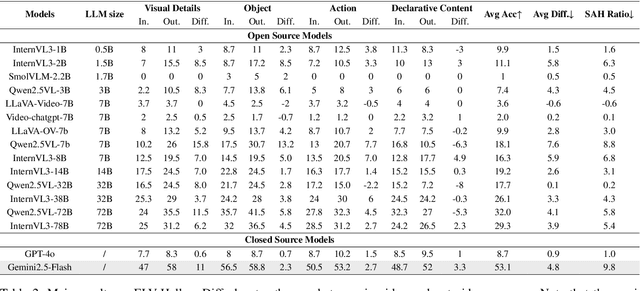
Video multimodal large language models (Video-MLLMs) have achieved remarkable progress in video understanding. However, they remain vulnerable to hallucination-producing content inconsistent with or unrelated to video inputs. Previous video hallucination benchmarks primarily focus on short-videos. They attribute hallucinations to factors such as strong language priors, missing frames, or vision-language biases introduced by the visual encoder. While these causes indeed account for most hallucinations in short videos, they still oversimplify the cause of hallucinations. Sometimes, models generate incorrect outputs but with correct frame-level semantics. We refer to this type of hallucination as Semantic Aggregation Hallucination (SAH), which arises during the process of aggregating frame-level semantics into event-level semantic groups. Given that SAH becomes particularly critical in long videos due to increased semantic complexity across multiple events, it is essential to separate and thoroughly investigate the causes of this type of hallucination. To address the above issues, we introduce ELV-Halluc, the first benchmark dedicated to long-video hallucination, enabling a systematic investigation of SAH. Our experiments confirm the existence of SAH and show that it increases with semantic complexity. Additionally, we find that models are more prone to SAH on rapidly changing semantics. Moreover, we discuss potential approaches to mitigate SAH. We demonstrate that positional encoding strategy contributes to alleviating SAH, and further adopt DPO strategy to enhance the model's ability to distinguish semantics within and across events. To support this, we curate a dataset of 8K adversarial data pairs and achieve improvements on both ELV-Halluc and Video-MME, including a substantial 27.7% reduction in SAH ratio.
Differentiable Model Scaling using Differentiable Topk
May 12, 2024



Over the past few years, as large language models have ushered in an era of intelligence emergence, there has been an intensified focus on scaling networks. Currently, many network architectures are designed manually, often resulting in sub-optimal configurations. Although Neural Architecture Search (NAS) methods have been proposed to automate this process, they suffer from low search efficiency. This study introduces Differentiable Model Scaling (DMS), increasing the efficiency for searching optimal width and depth in networks. DMS can model both width and depth in a direct and fully differentiable way, making it easy to optimize. We have evaluated our DMS across diverse tasks, ranging from vision tasks to NLP tasks and various network architectures, including CNNs and Transformers. Results consistently indicate that our DMS can find improved structures and outperforms state-of-the-art NAS methods. Specifically, for image classification on ImageNet, our DMS improves the top-1 accuracy of EfficientNet-B0 and Deit-Tiny by 1.4% and 0.6%, respectively, and outperforms the state-of-the-art zero-shot NAS method, ZiCo, by 1.3% while requiring only 0.4 GPU days for searching. For object detection on COCO, DMS improves the mAP of Yolo-v8-n by 2.0%. For language modeling, our pruned Llama-7B outperforms the prior method with lower perplexity and higher zero-shot classification accuracy. We will release our code in the future.
EasyJailbreak: A Unified Framework for Jailbreaking Large Language Models
Mar 18, 2024



Jailbreak attacks are crucial for identifying and mitigating the security vulnerabilities of Large Language Models (LLMs). They are designed to bypass safeguards and elicit prohibited outputs. However, due to significant differences among various jailbreak methods, there is no standard implementation framework available for the community, which limits comprehensive security evaluations. This paper introduces EasyJailbreak, a unified framework simplifying the construction and evaluation of jailbreak attacks against LLMs. It builds jailbreak attacks using four components: Selector, Mutator, Constraint, and Evaluator. This modular framework enables researchers to easily construct attacks from combinations of novel and existing components. So far, EasyJailbreak supports 11 distinct jailbreak methods and facilitates the security validation of a broad spectrum of LLMs. Our validation across 10 distinct LLMs reveals a significant vulnerability, with an average breach probability of 60% under various jailbreaking attacks. Notably, even advanced models like GPT-3.5-Turbo and GPT-4 exhibit average Attack Success Rates (ASR) of 57% and 33%, respectively. We have released a wealth of resources for researchers, including a web platform, PyPI published package, screencast video, and experimental outputs.
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models
Feb 08, 2024In the rapidly evolving landscape of Large Language Models (LLMs), ensuring robust safety measures is paramount. To meet this crucial need, we propose \emph{SALAD-Bench}, a safety benchmark specifically designed for evaluating LLMs, attack, and defense methods. Distinguished by its breadth, SALAD-Bench transcends conventional benchmarks through its large scale, rich diversity, intricate taxonomy spanning three levels, and versatile functionalities.SALAD-Bench is crafted with a meticulous array of questions, from standard queries to complex ones enriched with attack, defense modifications and multiple-choice. To effectively manage the inherent complexity, we introduce an innovative evaluators: the LLM-based MD-Judge for QA pairs with a particular focus on attack-enhanced queries, ensuring a seamless, and reliable evaluation. Above components extend SALAD-Bench from standard LLM safety evaluation to both LLM attack and defense methods evaluation, ensuring the joint-purpose utility. Our extensive experiments shed light on the resilience of LLMs against emerging threats and the efficacy of contemporary defense tactics. Data and evaluator are released under https://github.com/OpenSafetyLab/SALAD-BENCH.
Scalable Estimation of Dirichlet Process Mixture Models on Distributed Data
Sep 19, 2017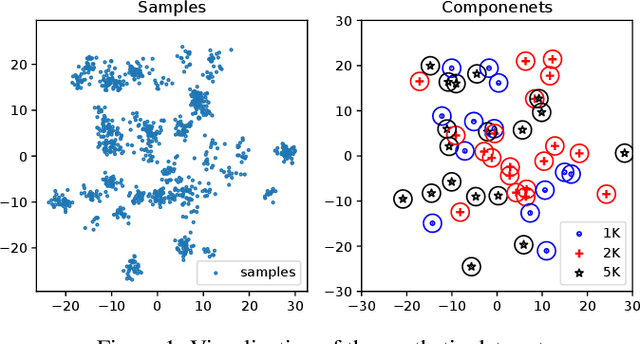

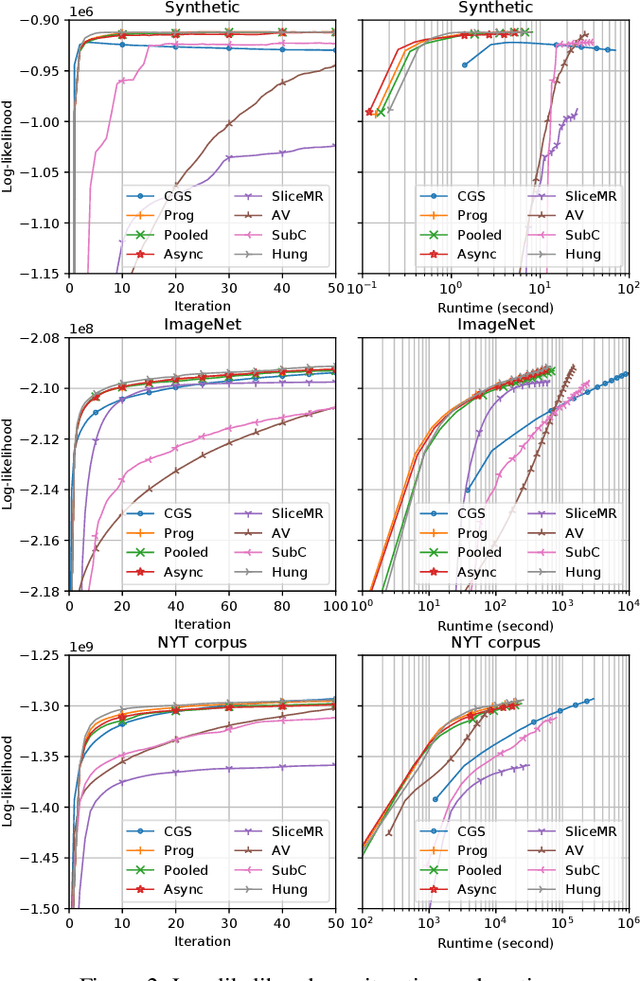

We consider the estimation of Dirichlet Process Mixture Models (DPMMs) in distributed environments, where data are distributed across multiple computing nodes. A key advantage of Bayesian nonparametric models such as DPMMs is that they allow new components to be introduced on the fly as needed. This, however, posts an important challenge to distributed estimation -- how to handle new components efficiently and consistently. To tackle this problem, we propose a new estimation method, which allows new components to be created locally in individual computing nodes. Components corresponding to the same cluster will be identified and merged via a probabilistic consolidation scheme. In this way, we can maintain the consistency of estimation with very low communication cost. Experiments on large real-world data sets show that the proposed method can achieve high scalability in distributed and asynchronous environments without compromising the mixing performance.
T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
Aug 03, 2017
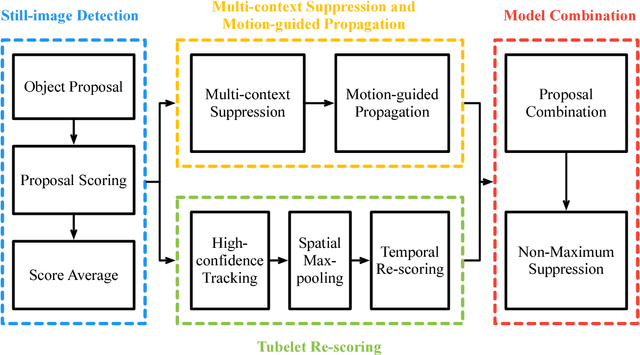


The state-of-the-art performance for object detection has been significantly improved over the past two years. Besides the introduction of powerful deep neural networks such as GoogleNet and VGG, novel object detection frameworks such as R-CNN and its successors, Fast R-CNN and Faster R-CNN, play an essential role in improving the state-of-the-art. Despite their effectiveness on still images, those frameworks are not specifically designed for object detection from videos. Temporal and contextual information of videos are not fully investigated and utilized. In this work, we propose a deep learning framework that incorporates temporal and contextual information from tubelets obtained in videos, which dramatically improves the baseline performance of existing still-image detection frameworks when they are applied to videos. It is called T-CNN, i.e. tubelets with convolutional neueral networks. The proposed framework won the recently introduced object-detection-from-video (VID) task with provided data in the ImageNet Large-Scale Visual Recognition Challenge 2015 (ILSVRC2015).
DeepID-Net: multi-stage and deformable deep convolutional neural networks for object detection
Sep 11, 2014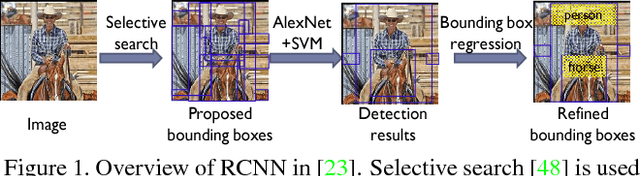
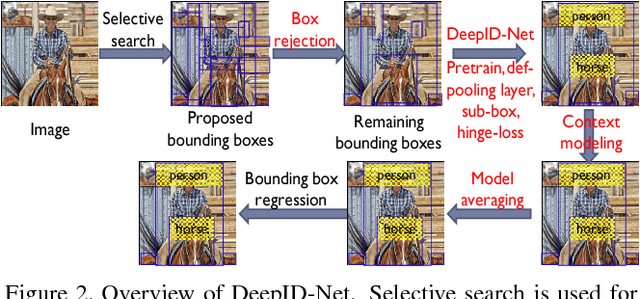

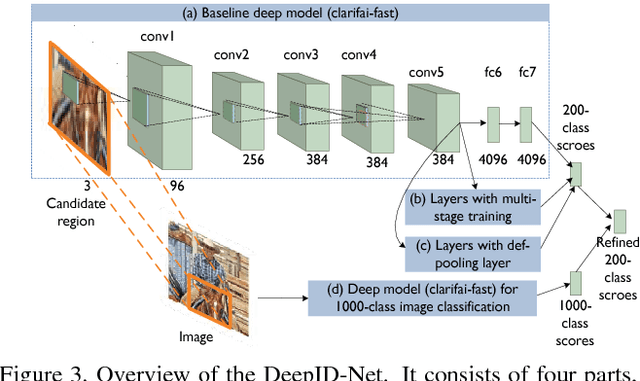
In this paper, we propose multi-stage and deformable deep convolutional neural networks for object detection. This new deep learning object detection diagram has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. With the proposed multi-stage training strategy, multiple classifiers are jointly optimized to process samples at different difficulty levels. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of modeling averaging. The proposed approach ranked \#2 in ILSVRC 2014. It improves the mean averaged precision obtained by RCNN, which is the state-of-the-art of object detection, from $31\%$ to $45\%$. Detailed component-wise analysis is also provided through extensive experimental evaluation.