 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models
Jan 02, 2026The capability of Unified Multimodal Models (UMMs) to apply world knowledge across diverse tasks remains a critical, unresolved challenge. Existing benchmarks fall short, offering only siloed, single-task evaluations with limited diagnostic power. To bridge this gap, we propose AEGIS (\emph{i.e.}, \textbf{A}ssessing \textbf{E}diting, \textbf{G}eneration, \textbf{I}nterpretation-Understanding for \textbf{S}uper-intelligence), a comprehensive multi-task benchmark covering visual understanding, generation, editing, and interleaved generation. AEGIS comprises 1,050 challenging, manually-annotated questions spanning 21 topics (including STEM, humanities, daily life, etc.) and 6 reasoning types. To concretely evaluate the performance of UMMs in world knowledge scope without ambiguous metrics, we further propose Deterministic Checklist-based Evaluation (DCE), a protocol that replaces ambiguous prompt-based scoring with atomic ``Y/N'' judgments, to enhance evaluation reliability. Our extensive experiments reveal that most UMMs exhibit severe world knowledge deficits and that performance degrades significantly with complex reasoning. Additionally, simple plug-in reasoning modules can partially mitigate these vulnerabilities, highlighting a promising direction for future research. These results highlight the importance of world-knowledge-based reasoning as a critical frontier for UMMs.
An improved educational competition optimizer with multi-covariance learning operators for global optimization problems
Sep 11, 2025The educational competition optimizer is a recently introduced metaheuristic algorithm inspired by human behavior, originating from the dynamics of educational competition within society. Nonetheless, ECO faces constraints due to an imbalance between exploitation and exploration, rendering it susceptible to local optima and demonstrating restricted effectiveness in addressing complex optimization problems. To address these limitations, this study presents an enhanced educational competition optimizer (IECO-MCO) utilizing multi-covariance learning operators. In IECO, three distinct covariance learning operators are introduced to improve the performance of ECO. Each operator effectively balances exploitation and exploration while preventing premature convergence of the population. The effectiveness of IECO is assessed through benchmark functions derived from the CEC 2017 and CEC 2022 test suites, and its performance is compared with various basic and improved algorithms across different categories. The results demonstrate that IECO-MCO surpasses the basic ECO and other competing algorithms in convergence speed, stability, and the capability to avoid local optima. Furthermore, statistical analyses, including the Friedman test, Kruskal-Wallis test, and Wilcoxon rank-sum test, are conducted to validate the superiority of IECO-MCO over the compared algorithms. Compared with the basic algorithm (improved algorithm), IECO-MCO achieved an average ranking of 2.213 (2.488) on the CE2017 and CEC2022 test suites. Additionally, the practical applicability of the proposed IECO-MCO algorithm is verified by solving constrained optimization problems. The experimental outcomes demonstrate the superior performance of IECO-MCO in tackling intricate optimization problems, underscoring its robustness and practical effectiveness in real-world scenarios.
MIRAGE: Assessing Hallucination in Multimodal Reasoning Chains of MLLM
May 30, 2025Multimodal hallucination in multimodal large language models (MLLMs) restricts the correctness of MLLMs. However, multimodal hallucinations are multi-sourced and arise from diverse causes. Existing benchmarks fail to adequately distinguish between perception-induced hallucinations and reasoning-induced hallucinations. This failure constitutes a significant issue and hinders the diagnosis of multimodal reasoning failures within MLLMs. To address this, we propose the {\dataset} benchmark, which isolates reasoning hallucinations by constructing questions where input images are correctly perceived by MLLMs yet reasoning errors persist. {\dataset} introduces multi-granular evaluation metrics: accuracy, factuality, and LLMs hallucination score for hallucination quantification. Our analysis reveals that (1) the model scale, data scale, and training stages significantly affect the degree of logical, fabrication, and factual hallucinations; (2) current MLLMs show no effective improvement on spatial hallucinations caused by misinterpreted spatial relationships, indicating their limited visual reasoning capabilities; and (3) question types correlate with distinct hallucination patterns, highlighting targeted challenges and potential mitigation strategies. To address these challenges, we propose {\method}, a method that combines curriculum reinforcement fine-tuning to encourage models to generate logic-consistent reasoning chains by stepwise reducing learning difficulty, and collaborative hint inference to reduce reasoning complexity. {\method} establishes a baseline on {\dataset}, and reduces the logical hallucinations in original base models.
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
MR-GDINO: Efficient Open-World Continual Object Detection
Dec 23, 2024



Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024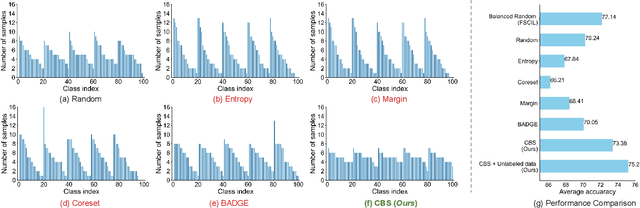
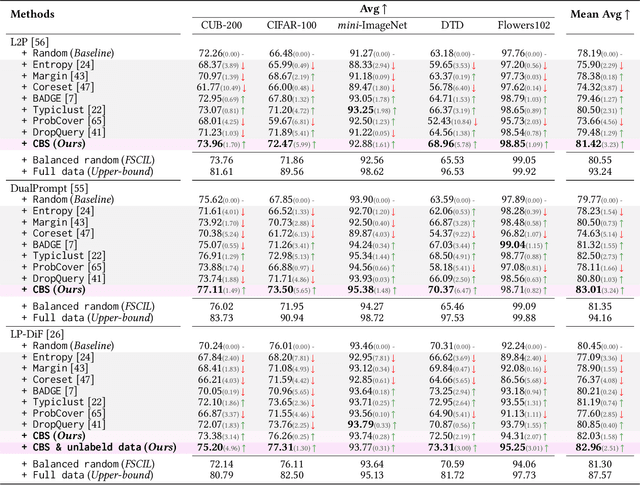

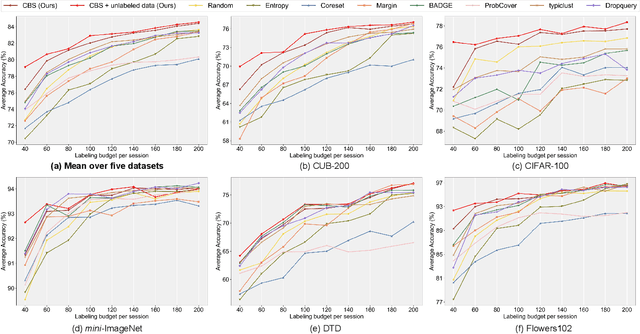
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024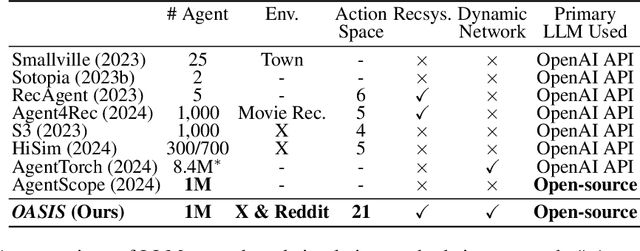
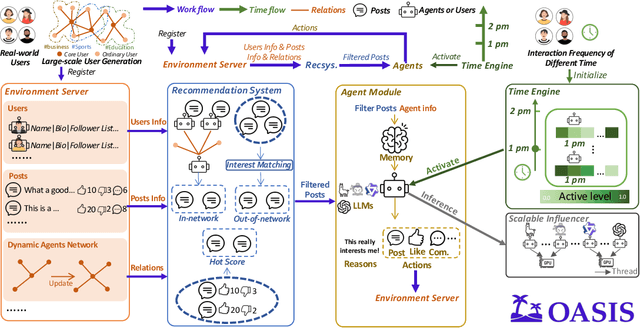

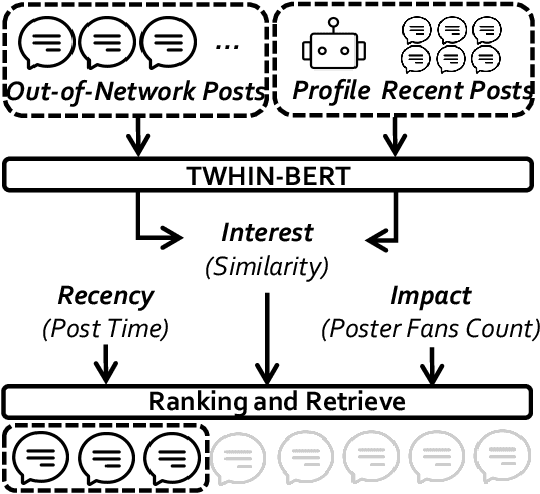
There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
LPT++: Efficient Training on Mixture of Long-tailed Experts
Sep 17, 2024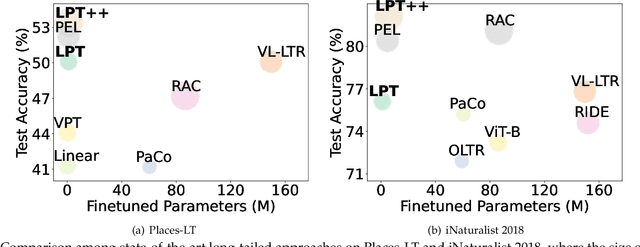
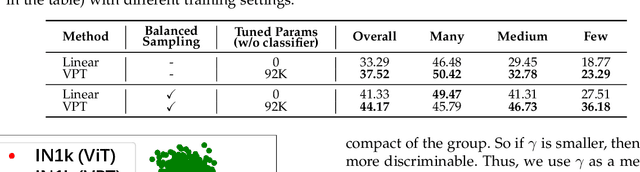
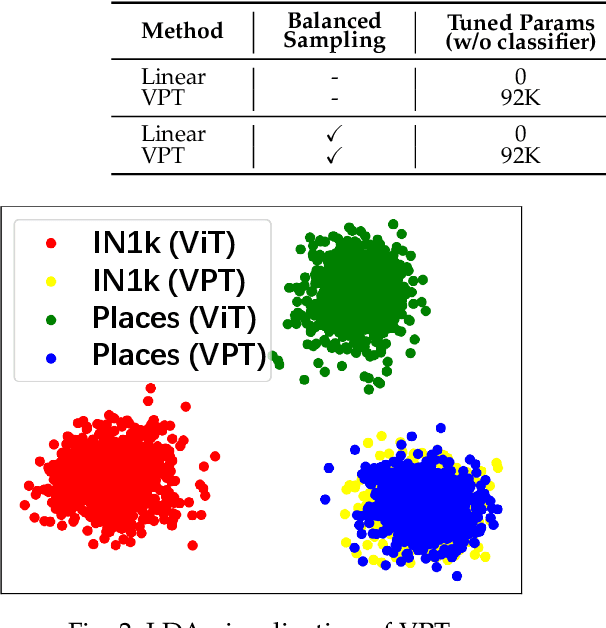
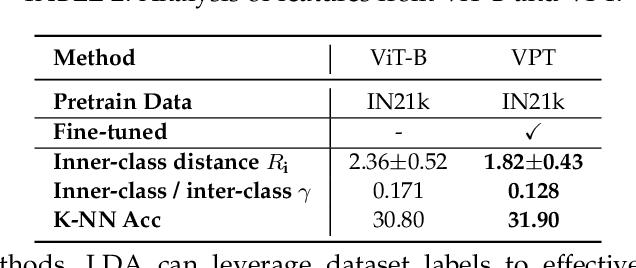
We introduce LPT++, a comprehensive framework for long-tailed classification that combines parameter-efficient fine-tuning (PEFT) with a learnable model ensemble. LPT++ enhances frozen Vision Transformers (ViTs) through the integration of three core components. The first is a universal long-tailed adaptation module, which aggregates long-tailed prompts and visual adapters to adapt the pretrained model to the target domain, meanwhile improving its discriminative ability. The second is the mixture of long-tailed experts framework with a mixture-of-experts (MoE) scorer, which adaptively calculates reweighting coefficients for confidence scores from both visual-only and visual-language (VL) model experts to generate more accurate predictions. Finally, LPT++ employs a three-phase training framework, wherein each critical module is learned separately, resulting in a stable and effective long-tailed classification training paradigm. Besides, we also propose the simple version of LPT++ namely LPT, which only integrates visual-only pretrained ViT and long-tailed prompts to formulate a single model method. LPT can clearly illustrate how long-tailed prompts works meanwhile achieving comparable performance without VL pretrained models. Experiments show that, with only ~1% extra trainable parameters, LPT++ achieves comparable accuracy against all the counterparts.
IMWA: Iterative Model Weight Averaging Benefits Class-Imbalanced Learning Tasks
Apr 25, 2024



Model Weight Averaging (MWA) is a technique that seeks to enhance model's performance by averaging the weights of multiple trained models. This paper first empirically finds that 1) the vanilla MWA can benefit the class-imbalanced learning, and 2) performing model averaging in the early epochs of training yields a greater performance improvement than doing that in later epochs. Inspired by these two observations, in this paper we propose a novel MWA technique for class-imbalanced learning tasks named Iterative Model Weight Averaging (IMWA). Specifically, IMWA divides the entire training stage into multiple episodes. Within each episode, multiple models are concurrently trained from the same initialized model weight, and subsequently averaged into a singular model. Then, the weight of this average model serves as a fresh initialization for the ensuing episode, thus establishing an iterative learning paradigm. Compared to vanilla MWA, IMWA achieves higher performance improvements with the same computational cost. Moreover, IMWA can further enhance the performance of those methods employing EMA strategy, demonstrating that IMWA and EMA can complement each other. Extensive experiments on various class-imbalanced learning tasks, i.e., class-imbalanced image classification, semi-supervised class-imbalanced image classification and semi-supervised object detection tasks showcase the effectiveness of our IMWA.