 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPT++: Efficient Training on Mixture of Long-tailed Experts
Paper and Code
Sep 17, 2024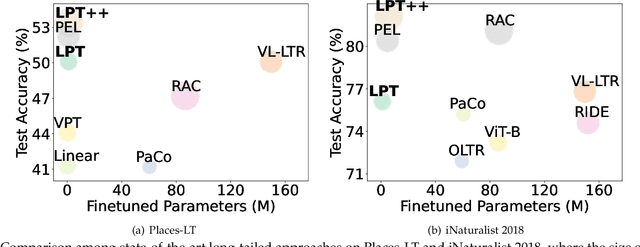
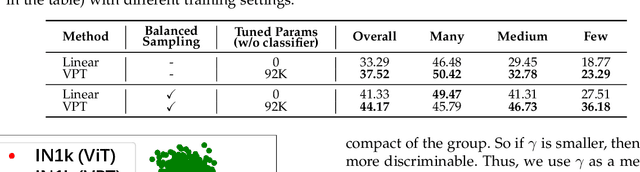
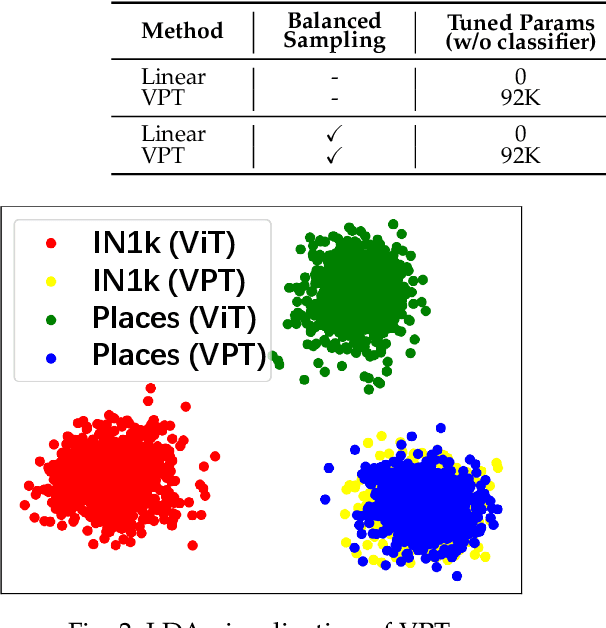
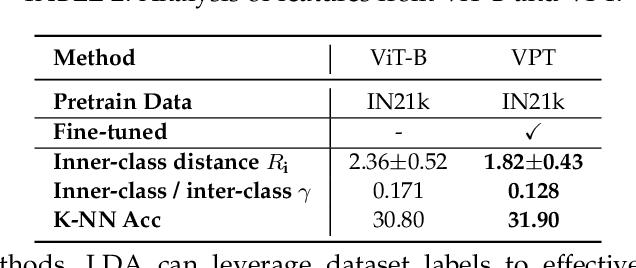
We introduce LPT++, a comprehensive framework for long-tailed classification that combines parameter-efficient fine-tuning (PEFT) with a learnable model ensemble. LPT++ enhances frozen Vision Transformers (ViTs) through the integration of three core components. The first is a universal long-tailed adaptation module, which aggregates long-tailed prompts and visual adapters to adapt the pretrained model to the target domain, meanwhile improving its discriminative ability. The second is the mixture of long-tailed experts framework with a mixture-of-experts (MoE) scorer, which adaptively calculates reweighting coefficients for confidence scores from both visual-only and visual-language (VL) model experts to generate more accurate predictions. Finally, LPT++ employs a three-phase training framework, wherein each critical module is learned separately, resulting in a stable and effective long-tailed classification training paradigm. Besides, we also propose the simple version of LPT++ namely LPT, which only integrates visual-only pretrained ViT and long-tailed prompts to formulate a single model method. LPT can clearly illustrate how long-tailed prompts works meanwhile achieving comparable performance without VL pretrained models. Experiments show that, with only ~1% extra trainable parameters, LPT++ achieves comparable accuracy against all the counterparts.