 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024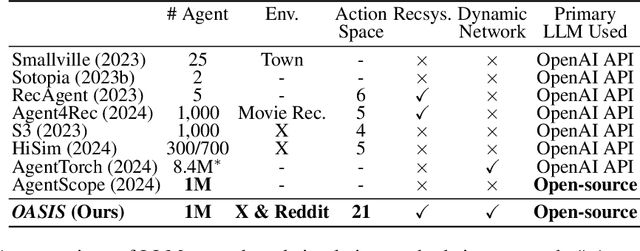
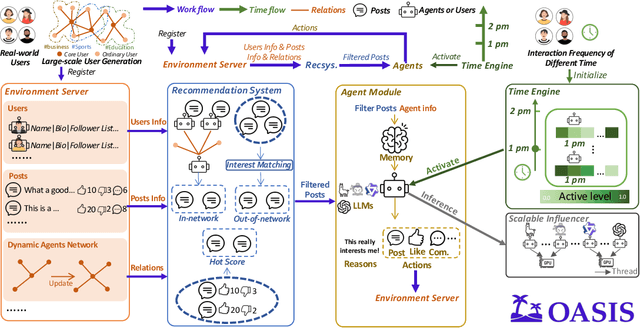

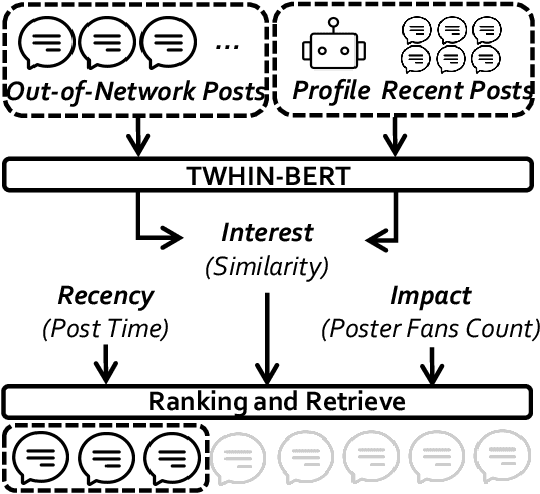
There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Generation
May 26, 2023Recently, multi-instrument music generation has become a hot topic. Different from single-instrument generation, multi-instrument generation needs to consider inter-track harmony besides intra-track coherence. This is usually achieved by composing note segments from different instruments into a signal sequence. This composition could be on different scales, such as note, bar, or track. Most existing work focuses on a particular scale, leading to a shortage in modeling music with diverse temporal and track dependencies. This paper proposes a multi-scale attentive Transformer model to improve the quality of multi-instrument generation. We first employ multiple Transformer decoders to learn multi-instrument representations of different scales and then design an attentive mechanism to fuse the multi-scale information. Experiments conducted on SOD and LMD datasets show that our model improves both quantitative and qualitative performance compared to models based on single-scale information. The source code and some generated samples can be found at https://github.com/HaRry-qaq/MSAT.