 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate-conditioned Deconvolution for Scalable Spatially Varying High-Throughput Imaging
Feb 01, 2026Wide-field fluorescence microscopy with compact optics often suffers from spatially varying blur due to field-dependent aberrations, vignetting, and sensor truncation, while finite sensor sampling imposes an inherent trade-off between field of view (FOV) and resolution. Computational Miniaturized Mesoscope (CM2) alleviate the sampling limit by multiplexing multiple sub-views onto a single sensor, but introduce view crosstalk and a highly ill-conditioned inverse problem compounded by spatially variant point spread functions (PSFs). Prior learning-based spatially varying (SV) reconstruction methods typically rely on global SV operators with fixed input sizes, resulting in memory and training costs that scale poorly with image dimensions. We propose SV-CoDe (Spatially Varying Coordinate-conditioned Deconvolution), a scalable deep learning framework that achieves uniform, high-resolution reconstruction across a 6.5 mm FOV. Unlike conventional methods, SV-CoDe employs coordinate-conditioned convolutions to locally adapt reconstruction kernels; this enables patch-based training that decouples parameter count from FOV size. SV-CoDe achieves the best image quality in both simulated and experimental measurements while requiring 10x less model size and 10x less training data than prior baselines. Trained purely on physics-based simulations, the network robustly generalizes to bead phantoms, weakly scattering brain slices, and freely moving C. elegans. SV-CoDe offers a scalable, physics-aware solution for correcting SV blur in compact optical systems and is readily extendable to a broad range of biomedical imaging applications.
DCL-SE: Dynamic Curriculum Learning for Spatiotemporal Encoding of Brain Imaging
Nov 19, 2025



High-dimensional neuroimaging analyses for clinical diagnosis are often constrained by compromises in spatiotemporal fidelity and by the limited adaptability of large-scale, general-purpose models. To address these challenges, we introduce Dynamic Curriculum Learning for Spatiotemporal Encoding (DCL-SE), an end-to-end framework centered on data-driven spatiotemporal encoding (DaSE). We leverage Approximate Rank Pooling (ARP) to efficiently encode three-dimensional volumetric brain data into information-rich, two-dimensional dynamic representations, and then employ a dynamic curriculum learning strategy, guided by a Dynamic Group Mechanism (DGM), to progressively train the decoder, refining feature extraction from global anatomical structures to fine pathological details. Evaluated across six publicly available datasets, including Alzheimer's disease and brain tumor classification, cerebral artery segmentation, and brain age prediction, DCL-SE consistently outperforms existing methods in accuracy, robustness, and interpretability. These findings underscore the critical importance of compact, task-specific architectures in the era of large-scale pretrained networks.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
Whitened Score Diffusion: A Structured Prior for Imaging Inverse Problems
May 15, 2025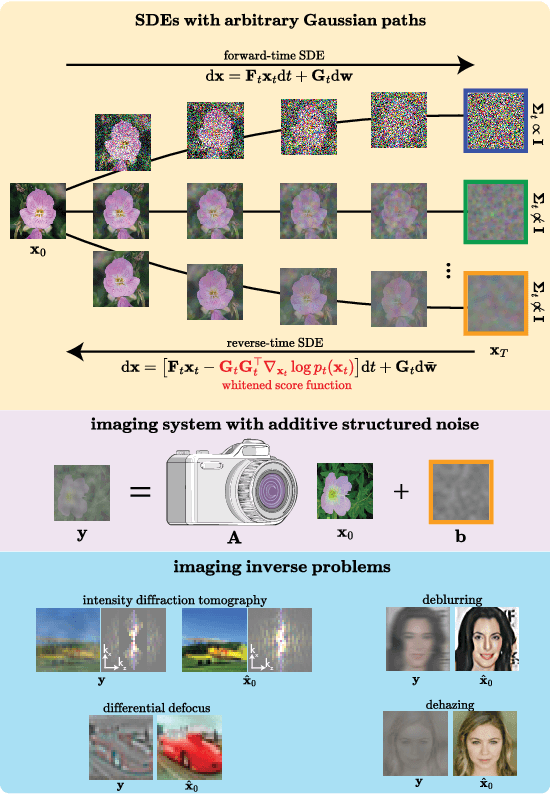

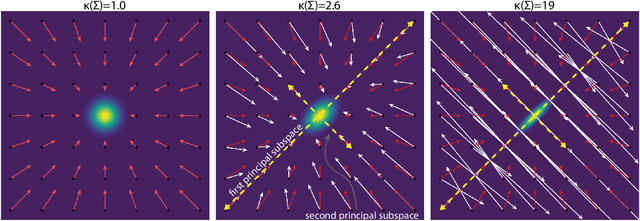

Conventional score-based diffusion models (DMs) may struggle with anisotropic Gaussian diffusion processes due to the required inversion of covariance matrices in the denoising score matching training objective \cite{vincent_connection_2011}. We propose Whitened Score (WS) diffusion models, a novel SDE-based framework that learns the Whitened Score function instead of the standard score. This approach circumvents covariance inversion, extending score-based DMs by enabling stable training of DMs on arbitrary Gaussian forward noising processes. WS DMs establish equivalence with FM for arbitrary Gaussian noise, allow for tailored spectral inductive biases, and provide strong Bayesian priors for imaging inverse problems with structured noise. We experiment with a variety of computational imaging tasks using the CIFAR and CelebA ($64\times64$) datasets and demonstrate that WS diffusion priors trained on anisotropic Gaussian noising processes consistently outperform conventional diffusion priors based on isotropic Gaussian noise.
Empirical Study on Near-Field and Spatial Non-Stationarity Modeling for THz XL-MIMO Channel in Indoor Scenario
May 14, 2025Terahertz (THz) extremely large-scale MIMO (XL-MIMO) is considered a key enabling technology for 6G and beyond due to its advantages such as wide bandwidth and high beam gain. As the frequency and array size increase, users are more likely to fall within the near-field (NF) region, where the far-field plane-wave assumption no longer holds. This also introduces spatial non-stationarity (SnS), as different antenna elements observe distinct multipath characteristics. Therefore, this paper proposes a THz XL-MIMO channel model that accounts for both NF propagation and SnS, validated using channel measurement data. In this work, we first conduct THz XL-MIMO channel measurements at 100 GHz and 132 GHz using 301- and 531-element ULAs in indoor environments, revealing pronounced NF effects characterized by nonlinear inter-element phase variations, as well as element-dependent delay and angle shifts. Moreover, the SnS phenomenon is observed, arising not only from blockage but also from inconsistent reflection or scattering. Based on these observations, a hybrid NF channel modeling approach combining the scatterer-excited point-source model and the specular reflection model is proposed to capture nonlinear phase variation. For SnS modeling, amplitude attenuation factors (AAFs) are introduced to characterize the continuous variation of path power across the array. By analyzing the statistical distribution and spatial autocorrelation properties of AAFs, a statistical rank-matching-based method is proposed for their generation. Finally, the model is validated using measured data. Evaluation across metrics such as entropy capacity, condition number, spatial correlation, channel gain, Rician K-factor, and RMS delay spread confirms that the proposed model closely aligns with measurements and effectively characterizes the essential features of THz XL-MIMO channels.
A Unified Deterministic Channel Model for Multi-Type RIS with Reflective, Transmissive, and Polarization Operations
May 12, 2025Reconfigurable Intelligent Surface (RIS) technologies have been considered as a promising enabler for 6G, enabling advantageous control of electromagnetic (EM) propagation. RIS can be categorized into multiple types based on their reflective/transmissive modes and polarization control capabilities, all of which are expected to be widely deployed in practical environments. A reliable RIS channel model is essential for the design and development of RIS communication systems. While deterministic modeling approaches such as ray-tracing (RT) offer significant benefits, a unified model that accommodates all RIS types is still lacking. This paper addresses this gap by developing a high-precision deterministic channel model based on RT, supporting multiple RIS types: reflective, transmissive, hybrid, and three polarization operation modes. To achieve this, a unified EM response model for the aforementioned RIS types is developed. The reflection and transmission coefficients of RIS elements are derived using a tensor-based equivalent impedance approach, followed by calculating the scattered fields of the RIS to establish an EM response model. The performance of different RIS types is compared through simulations in typical scenarios. During this process, passive and lossless constraints on the reflection and transmission coefficients are incorporated to ensure fairness in the performance evaluation. Simulation results validate the framework's accuracy in characterizing the RIS channel, and specific cases tailored for dual-polarization independent control and polarization rotating RISs are highlighted as insights for their future deployment. This work can be helpful for the evaluation and optimization of RIS-enabled wireless communication systems.
Uncertainty-Aware Large Language Models for Explainable Disease Diagnosis
May 06, 2025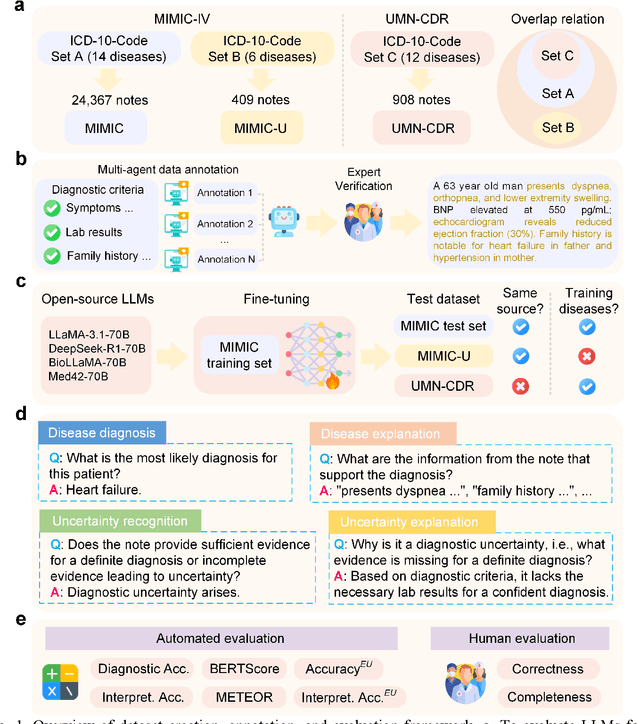
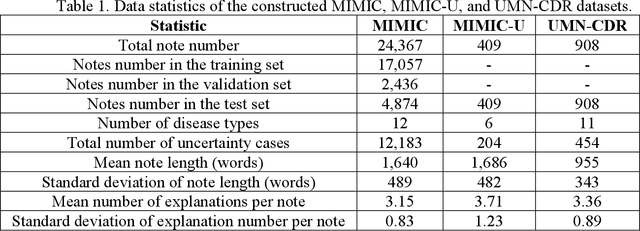

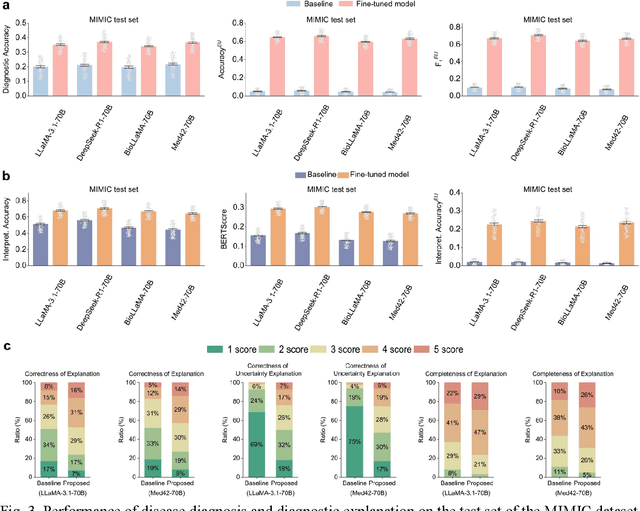
Explainable disease diagnosis, which leverages patient information (e.g., signs and symptoms) and computational models to generate probable diagnoses and reasonings, offers clear clinical values. However, when clinical notes encompass insufficient evidence for a definite diagnosis, such as the absence of definitive symptoms, diagnostic uncertainty usually arises, increasing the risk of misdiagnosis and adverse outcomes. Although explicitly identifying and explaining diagnostic uncertainties is essential for trustworthy diagnostic systems, it remains under-explored. To fill this gap, we introduce ConfiDx, an uncertainty-aware large language model (LLM) created by fine-tuning open-source LLMs with diagnostic criteria. We formalized the task and assembled richly annotated datasets that capture varying degrees of diagnostic ambiguity. Evaluating ConfiDx on real-world datasets demonstrated that it excelled in identifying diagnostic uncertainties, achieving superior diagnostic performance, and generating trustworthy explanations for diagnoses and uncertainties. To our knowledge, this is the first study to jointly address diagnostic uncertainty recognition and explanation, substantially enhancing the reliability of automatic diagnostic systems.
High-Resolution Multipath Angle Estimation Based on Power-Angle-Delay Profile for Directional Scanning Sounding
Apr 17, 2025Directional scanning sounding (DSS) has become widely adopted for high-frequency channel measurements because it effectively compensates for severe path loss. However, the resolution of existing multipath component (MPC) angle estimation methods is constrained by the DSS angle sampling interval. Therefore, this communication proposes a high-resolution MPC angle estimation method based on power-angle-delay profile (PADP) for DSS. By exploiting the mapping relationship between the power difference of adjacent angles in the PADP and MPC offset angle, the resolution of MPC angle estimation is refined, significantly enhancing the accuracy of MPC angle and amplitude estimation without increasing measurement complexity. Numerical simulation results demonstrate that the proposed method reduces the mean squared estimation errors of angle and amplitude by one order of magnitude compared to traditional omnidirectional synthesis methods. Furthermore, the estimation errors approach the Cram\'er-Rao Lower Bounds (CRLBs) derived for wideband DSS, thereby validating its superior performance in MPC angle and amplitude estimation. Finally, experiments conducted in an indoor scenario at 37.5 GHz validate the excellent performance of the proposed method in practical applications.
Research and Experimental Validation for 3GPP ISAC Channel Modeling Standardization
Apr 14, 2025Integrated Sensing and Communication (ISAC) is considered a key technology in 6G networks. An accurate sensing channel model is crucial for the design and sensing performance evaluation of ISAC systems. The widely used Geometry-Based Stochastic Model (GBSM), typically applied in standardized channel modeling, mainly focuses on the statistical fading characteristics of the channel. However, it fails to capture the characteristics of targets in ISAC systems, such as their positions and velocities, as well as the impact of the targets on the background. To address this issue, this paper proposes an extended GBSM (E-GBSM) sensing channel model that incorporates newly discovered channel characteristics into a unified modeling framework. In this framework, the sensing channel is divided into target and background channels. For the target channel, the model introduces a concatenated modeling approach, while for the background channel, a parameter called the power control factor is introduced to assess impact of the target on the background channel, making the modeling framework applicable to both mono-static and bi-static sensing modes. To validate the proposed model's effectiveness, measurements of target and background channels are conducted in both indoor and outdoor scenarios, covering various sensing targets such as metal plates, reconfigurable intelligent surfaces, human bodies, UAVs, and vehicles. The experimental results provide important theoretical support and empirical data for the standardization of ISAC channel modeling.