 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Potential Pruning for Enhancing Safety Prompts Against VLM Jailbreaking Without Retraining
Mar 15, 2026Safety prompts constitute an interpretable layer of defense against jailbreak attacks in vision-language models (VLMs); however, their efficacy is constrained by the models' latent structural responsiveness. We observe that such prompts consistently engage a sparse set of parameters that remain largely quiescent during benign use. This finding motivates the Safety Subnetwork Hypothesis: VLMs embed structurally distinct pathways capable of enforcing safety, but these pathways remain dormant without explicit stimulation. To expose and amplify these pathways, we introduce Safety-Potential Pruning, a one-shot pruning framework that amplifies safety-relevant activations by removing weights that are less responsive to safety prompts without additional retraining. Across three representative VLM architectures and three jailbreak benchmarks, our method reduces attack success rates by up to 22% relative to prompting alone, all while maintaining strong benign performance. These findings frame pruning not only as a model compression technique, but as a structural intervention to emerge alignment-relevant subnets, offering a new path to robust jailbreak resistance.
Anomaly Detection for Incident Response at Scale
Apr 24, 2024
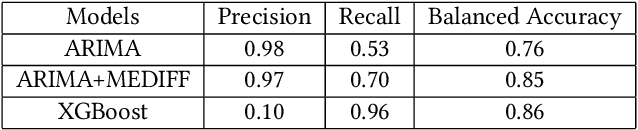
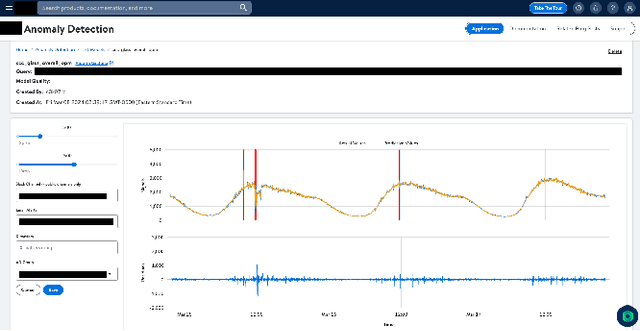
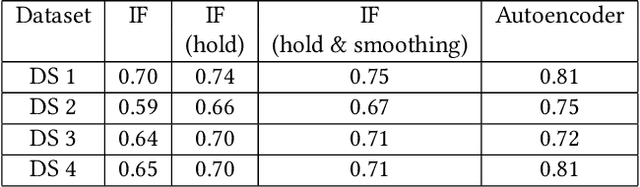
We present a machine learning-based anomaly detection product, AI Detect and Respond (AIDR), that monitors Walmart's business and system health in real-time. During the validation over 3 months, the product served predictions from over 3000 models to more than 25 application, platform, and operation teams, covering 63\% of major incidents and reducing the mean-time-to-detect (MTTD) by more than 7 minutes. Unlike previous anomaly detection methods, our solution leverages statistical, ML and deep learning models while continuing to incorporate rule-based static thresholds to incorporate domain-specific knowledge. Both univariate and multivariate ML models are deployed and maintained through distributed services for scalability and high availability. AIDR has a feedback loop that assesses model quality with a combination of drift detection algorithms and customer feedback. It also offers self-onboarding capabilities and customizability. AIDR has achieved success with various internal teams with lower time to detection and fewer false positives than previous methods. As we move forward, we aim to expand incident coverage and prevention, reduce noise, and integrate further with root cause recommendation (RCR) to enable an end-to-end AIDR experience.
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024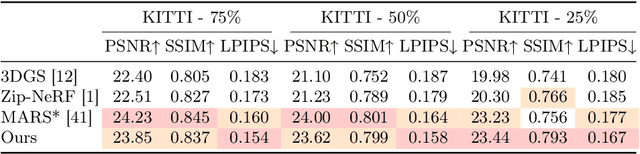
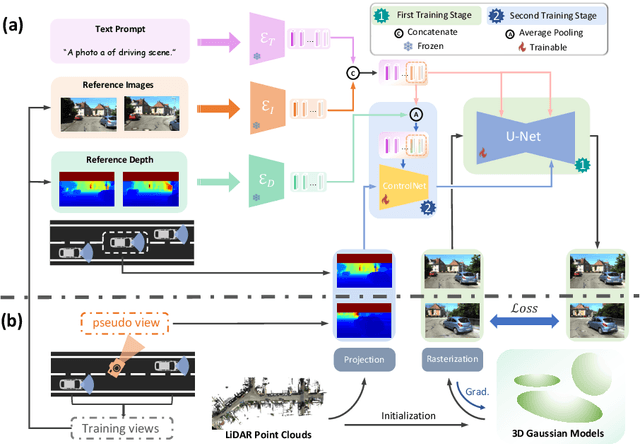
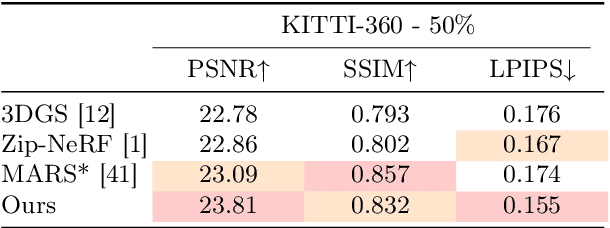
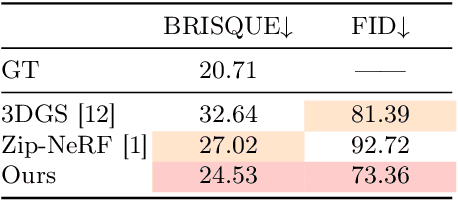
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
HiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Jan 11, 2024
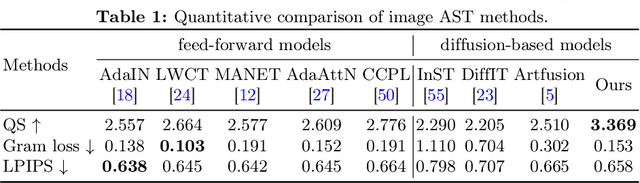
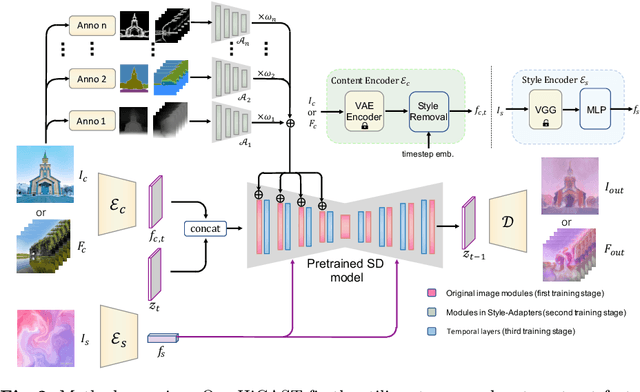
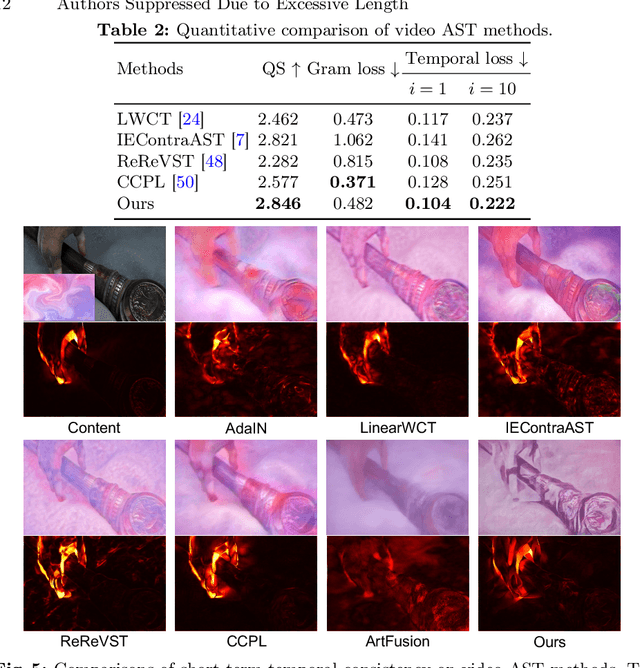
The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.
On the Dynamics Under the Unhinged Loss and Beyond
Dec 13, 2023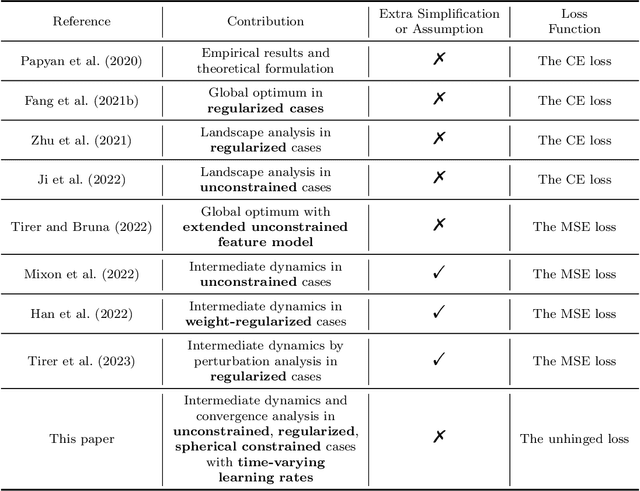


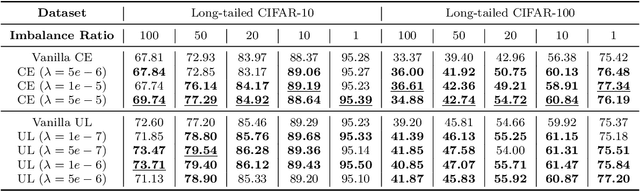
Recent works have studied implicit biases in deep learning, especially the behavior of last-layer features and classifier weights. However, they usually need to simplify the intermediate dynamics under gradient flow or gradient descent due to the intractability of loss functions and model architectures. In this paper, we introduce the unhinged loss, a concise loss function, that offers more mathematical opportunities to analyze the closed-form dynamics while requiring as few simplifications or assumptions as possible. The unhinged loss allows for considering more practical techniques, such as time-vary learning rates and feature normalization. Based on the layer-peeled model that views last-layer features as free optimization variables, we conduct a thorough analysis in the unconstrained, regularized, and spherical constrained cases, as well as the case where the neural tangent kernel remains invariant. To bridge the performance of the unhinged loss to that of Cross-Entropy (CE), we investigate the scenario of fixing classifier weights with a specific structure, (e.g., a simplex equiangular tight frame). Our analysis shows that these dynamics converge exponentially fast to a solution depending on the initialization of features and classifier weights. These theoretical results not only offer valuable insights, including explicit feature regularization and rescaled learning rates for enhancing practical training with the unhinged loss, but also extend their applicability to other loss functions. Finally, we empirically demonstrate these theoretical results and insights through extensive experiments.
EDoG: Adversarial Edge Detection For Graph Neural Networks
Dec 27, 2022Graph Neural Networks (GNNs) have been widely applied to different tasks such as bioinformatics, drug design, and social networks. However, recent studies have shown that GNNs are vulnerable to adversarial attacks which aim to mislead the node or subgraph classification prediction by adding subtle perturbations. Detecting these attacks is challenging due to the small magnitude of perturbation and the discrete nature of graph data. In this paper, we propose a general adversarial edge detection pipeline EDoG without requiring knowledge of the attack strategies based on graph generation. Specifically, we propose a novel graph generation approach combined with link prediction to detect suspicious adversarial edges. To effectively train the graph generative model, we sample several sub-graphs from the given graph data. We show that since the number of adversarial edges is usually low in practice, with low probability the sampled sub-graphs will contain adversarial edges based on the union bound. In addition, considering the strong attacks which perturb a large number of edges, we propose a set of novel features to perform outlier detection as the preprocessing for our detection. Extensive experimental results on three real-world graph datasets including a private transaction rule dataset from a major company and two types of synthetic graphs with controlled properties show that EDoG can achieve above 0.8 AUC against four state-of-the-art unseen attack strategies without requiring any knowledge about the attack type; and around 0.85 with knowledge of the attack type. EDoG significantly outperforms traditional malicious edge detection baselines. We also show that an adaptive attack with full knowledge of our detection pipeline is difficult to bypass it.
Weakly-Supervised Deep Learning Model for Prostate Cancer Diagnosis and Gleason Grading of Histopathology Images
Dec 25, 2022Prostate cancer is the most common cancer in men worldwide and the second leading cause of cancer death in the United States. One of the prognostic features in prostate cancer is the Gleason grading of histopathology images. The Gleason grade is assigned based on tumor architecture on Hematoxylin and Eosin (H&E) stained whole slide images (WSI) by the pathologists. This process is time-consuming and has known interobserver variability. In the past few years, deep learning algorithms have been used to analyze histopathology images, delivering promising results for grading prostate cancer. However, most of the algorithms rely on the fully annotated datasets which are expensive to generate. In this work, we proposed a novel weakly-supervised algorithm to classify prostate cancer grades. The proposed algorithm consists of three steps: (1) extracting discriminative areas in a histopathology image by employing the Multiple Instance Learning (MIL) algorithm based on Transformers, (2) representing the image by constructing a graph using the discriminative patches, and (3) classifying the image into its Gleason grades by developing a Graph Convolutional Neural Network (GCN) based on the gated attention mechanism. We evaluated our algorithm using publicly available datasets, including TCGAPRAD, PANDA, and Gleason 2019 challenge datasets. We also cross validated the algorithm on an independent dataset. Results show that the proposed model achieved state-of-the-art performance in the Gleason grading task in terms of accuracy, F1 score, and cohen-kappa. The code is available at https://github.com/NabaviLab/Prostate-Cancer.
Learning with linear mixed model for group recommendation systems
Dec 17, 2022

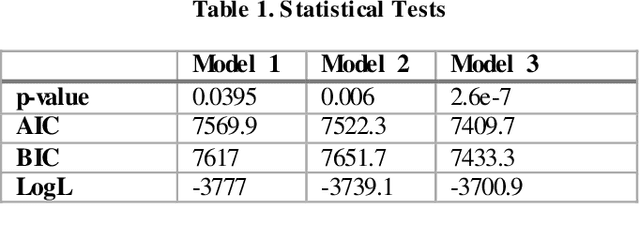

Accurate prediction of users' responses to items is one of the main aims of many computational advising applications. Examples include recommending movies, news articles, songs, jobs, clothes, books and so forth. Accurate prediction of inactive users' responses still remains a challenging problem for many applications. In this paper, we explore the linear mixed model in recommendation system. The recommendation process is naturally modelled as the mixed process between objective effects (fixed effects) and subjective effects (random effects). The latent association between the subjective effects and the users' responses can be mined through the restricted maximum likelihood method. It turns out the linear mixed models can collaborate items' attributes and users' characteristics naturally and effectively. While this model cannot produce the most precisely individual level personalized recommendation, it is relative fast and accurate for group (users)/class (items) recommendation. Numerical examples on GroupLens benchmark problems are presented to show the effectiveness of this method.
* 5 pages, 9 figures, published