 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
When LLMs get significantly worse: A statistical approach to detect model degradations
Feb 09, 2026Minimizing the inference cost and latency of foundation models has become a crucial area of research. Optimization approaches include theoretically lossless methods and others without accuracy guarantees like quantization. In all of these cases it is crucial to ensure that the model quality has not degraded. However, even at temperature zero, model generations are not necessarily robust even to theoretically lossless model optimizations due to numerical errors. We thus require statistical tools to decide whether a finite-sample accuracy deviation is an evidence of a model's degradation or whether it can be attributed to (harmless) noise in the evaluation. We propose a statistically sound hypothesis testing framework based on McNemar's test allowing to efficiently detect model degradations, while guaranteeing a controlled rate of false positives. The crucial insight is that we have to confront the model scores on each sample, rather than aggregated on the task level. Furthermore, we propose three approaches to aggregate accuracy estimates across multiple benchmarks into a single decision. We provide an implementation on top of the largely adopted open source LM Evaluation Harness and provide a case study illustrating that the method correctly flags degraded models, while not flagging model optimizations that are provably lossless. We find that with our tests even empirical accuracy degradations of 0.3% can be confidently attributed to actual degradations rather than noise.
* https://openreview.net/forum?id=cM3gsqEI4K
Variation-Bounded Loss for Noise-Tolerant Learning
Nov 15, 2025Mitigating the negative impact of noisy labels has been aperennial issue in supervised learning. Robust loss functions have emerged as a prevalent solution to this problem. In this work, we introduce the Variation Ratio as a novel property related to the robustness of loss functions, and propose a new family of robust loss functions, termed Variation-Bounded Loss (VBL), which is characterized by a bounded variation ratio. We provide theoretical analyses of the variation ratio, proving that a smaller variation ratio would lead to better robustness. Furthermore, we reveal that the variation ratio provides a feasible method to relax the symmetric condition and offers a more concise path to achieve the asymmetric condition. Based on the variation ratio, we reformulate several commonly used loss functions into a variation-bounded form for practical applications. Positive experiments on various datasets exhibit the effectiveness and flexibility of our approach.
Joint Asymmetric Loss for Learning with Noisy Labels
Jul 23, 2025Learning with noisy labels is a crucial task for training accurate deep neural networks. To mitigate label noise, prior studies have proposed various robust loss functions, particularly symmetric losses. Nevertheless, symmetric losses usually suffer from the underfitting issue due to the overly strict constraint. To address this problem, the Active Passive Loss (APL) jointly optimizes an active and a passive loss to mutually enhance the overall fitting ability. Within APL, symmetric losses have been successfully extended, yielding advanced robust loss functions. Despite these advancements, emerging theoretical analyses indicate that asymmetric losses, a new class of robust loss functions, possess superior properties compared to symmetric losses. However, existing asymmetric losses are not compatible with advanced optimization frameworks such as APL, limiting their potential and applicability. Motivated by this theoretical gap and the prospect of asymmetric losses, we extend the asymmetric loss to the more complex passive loss scenario and propose the Asymetric Mean Square Error (AMSE), a novel asymmetric loss. We rigorously establish the necessary and sufficient condition under which AMSE satisfies the asymmetric condition. By substituting the traditional symmetric passive loss in APL with our proposed AMSE, we introduce a novel robust loss framework termed Joint Asymmetric Loss (JAL). Extensive experiments demonstrate the effectiveness of our method in mitigating label noise. Code available at: https://github.com/cswjl/joint-asymmetric-loss
Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
Dec 17, 2024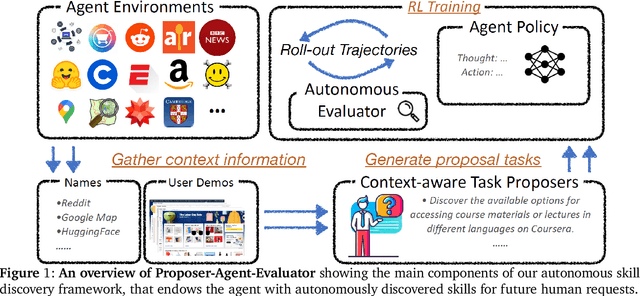
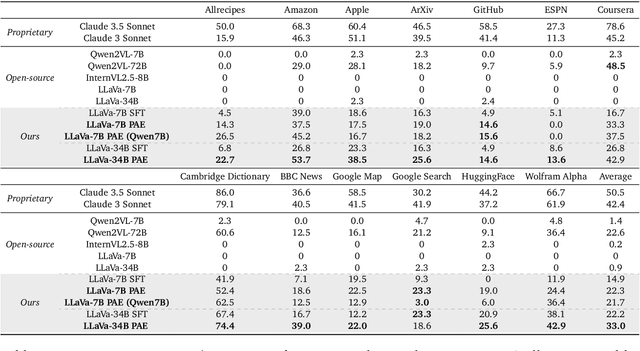
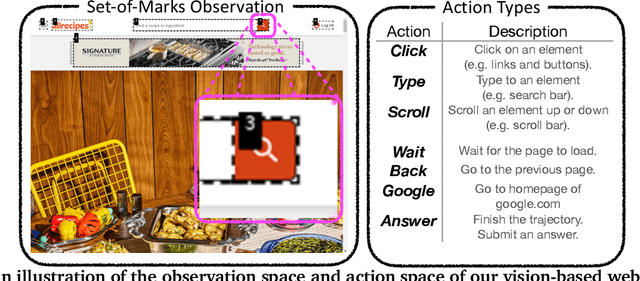
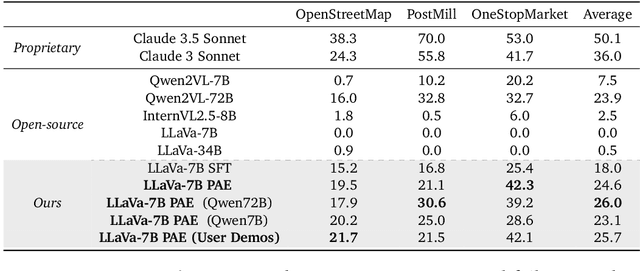
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/
Neural Field Classifiers via Target Encoding and Classification Loss
Mar 02, 2024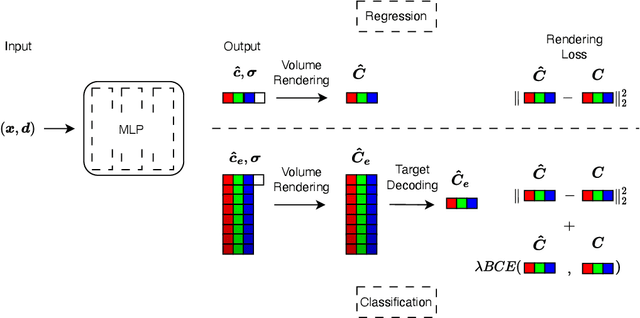
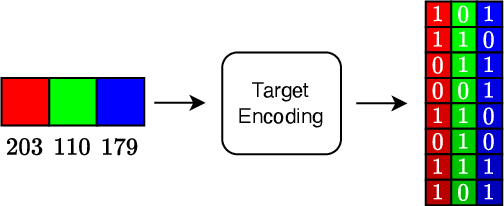

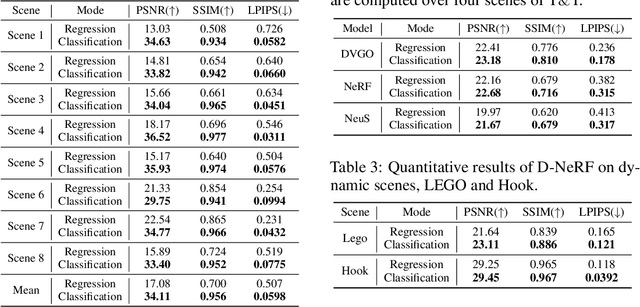
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
ViGoR: Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling
Feb 09, 2024



By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world. However, the generated text often suffers from inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects. To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervisions, as well as automated methods. We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.
AffordanceLLM: Grounding Affordance from Vision Language Models
Jan 12, 2024



Affordance grounding refers to the task of finding the area of an object with which one can interact. It is a fundamental but challenging task, as a successful solution requires the comprehensive understanding of a scene in multiple aspects including detection, localization, and recognition of objects with their parts, of geo-spatial configuration/layout of the scene, of 3D shapes and physics, as well as of the functionality and potential interaction of the objects and humans. Much of the knowledge is hidden and beyond the image content with the supervised labels from a limited training set. In this paper, we make an attempt to improve the generalization capability of the current affordance grounding by taking the advantage of the rich world, abstract, and human-object-interaction knowledge from pretrained large-scale vision language models. Under the AGD20K benchmark, our proposed model demonstrates a significant performance gain over the competing methods for in-the-wild object affordance grounding. We further demonstrate it can ground affordance for objects from random Internet images, even if both objects and actions are unseen during training. Project site: https://jasonqsy.github.io/AffordanceLLM/
On the Dynamics Under the Unhinged Loss and Beyond
Dec 13, 2023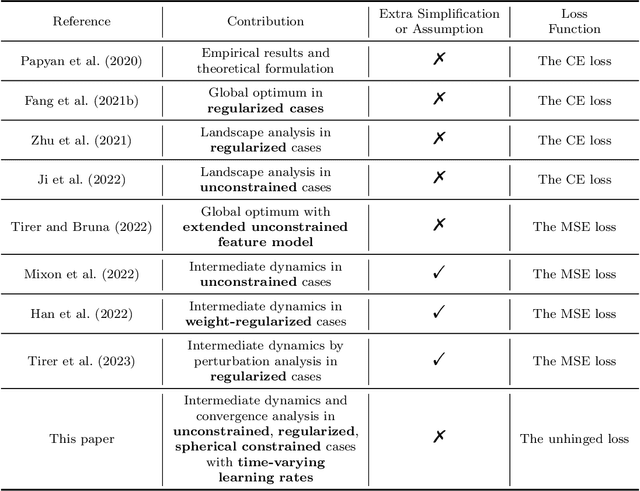


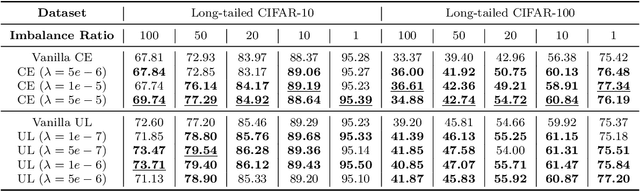
Recent works have studied implicit biases in deep learning, especially the behavior of last-layer features and classifier weights. However, they usually need to simplify the intermediate dynamics under gradient flow or gradient descent due to the intractability of loss functions and model architectures. In this paper, we introduce the unhinged loss, a concise loss function, that offers more mathematical opportunities to analyze the closed-form dynamics while requiring as few simplifications or assumptions as possible. The unhinged loss allows for considering more practical techniques, such as time-vary learning rates and feature normalization. Based on the layer-peeled model that views last-layer features as free optimization variables, we conduct a thorough analysis in the unconstrained, regularized, and spherical constrained cases, as well as the case where the neural tangent kernel remains invariant. To bridge the performance of the unhinged loss to that of Cross-Entropy (CE), we investigate the scenario of fixing classifier weights with a specific structure, (e.g., a simplex equiangular tight frame). Our analysis shows that these dynamics converge exponentially fast to a solution depending on the initialization of features and classifier weights. These theoretical results not only offer valuable insights, including explicit feature regularization and rescaled learning rates for enhancing practical training with the unhinged loss, but also extend their applicability to other loss functions. Finally, we empirically demonstrate these theoretical results and insights through extensive experiments.
Visual Prompt Tuning for Test-time Domain Adaptation
Oct 10, 2022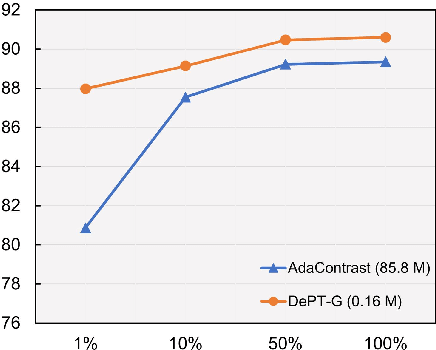
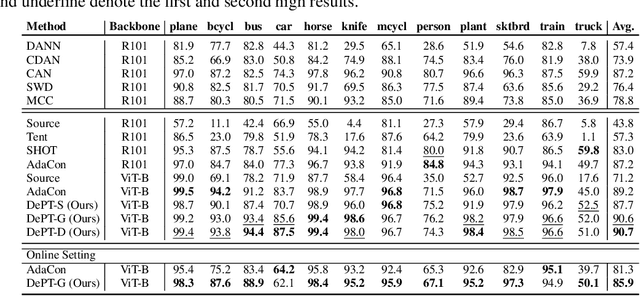
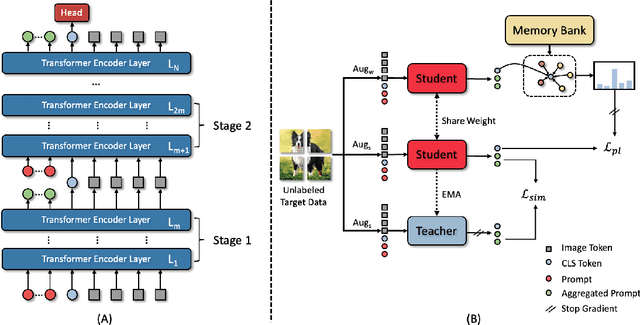
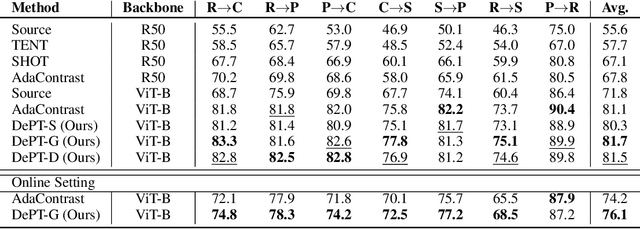
Models should have the ability to adapt to unseen data during test-time to avoid performance drop caused by inevitable distribution shifts in real-world deployment scenarios. In this work, we tackle the practical yet challenging test-time adaptation (TTA) problem, where a model adapts to the target domain without accessing the source data. We propose a simple recipe called data-efficient prompt tuning (DePT) with two key ingredients. First, DePT plugs visual prompts into the vision Transformer and only tunes these source-initialized prompts during adaptation. We find such parameter-efficient finetuning can efficiently adapt the model representation to the target domain without overfitting to the noise in the learning objective. Second, DePT bootstraps the source representation to the target domain by memory bank-based online pseudo labeling. A hierarchical self-supervised regularization specially designed for prompts is jointly optimized to alleviate error accumulation during self-training. With much fewer tunable parameters, DePT demonstrates not only state-of-the-art performance on major adaptation benchmarks, but also superior data efficiency, i.e., adaptation with only 1\% or 10\% data without much performance degradation compared to 100\% data. In addition, DePT is also versatile to be extended to online or multi-source TTA settings.