 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Noisy Labels via Sparse Regularization
Paper and Code


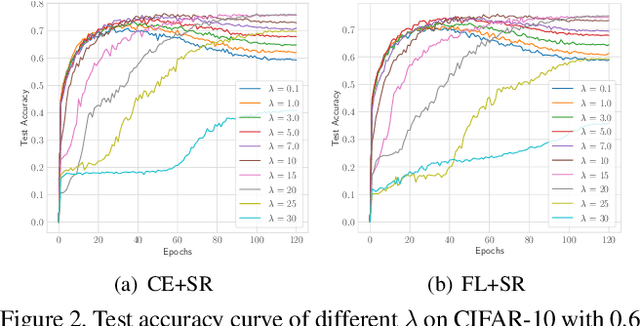

Learning with noisy labels is an important and challenging task for training accurate deep neural networks. Some commonly-used loss functions, such as Cross Entropy (CE), suffer from severe overfitting to noisy labels. Robust loss functions that satisfy the symmetric condition were tailored to remedy this problem, which however encounter the underfitting effect. In this paper, we theoretically prove that \textbf{any loss can be made robust to noisy labels} by restricting the network output to the set of permutations over a fixed vector. When the fixed vector is one-hot, we only need to constrain the output to be one-hot, which however produces zero gradients almost everywhere and thus makes gradient-based optimization difficult. In this work, we introduce the sparse regularization strategy to approximate the one-hot constraint, which is composed of network output sharpening operation that enforces the output distribution of a network to be sharp and the $\ell_p$-norm ($p\le 1$) regularization that promotes the network output to be sparse. This simple approach guarantees the robustness of arbitrary loss functions while not hindering the fitting ability. Experimental results demonstrate that our method can significantly improve the performance of commonly-used loss functions in the presence of noisy labels and class imbalance, and outperform the state-of-the-art methods. The code is available at https://github.com/hitcszx/lnl_sr.