 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs
Feb 13, 2025



Large Language Models (LLMs) are increasingly used as chatbots, yet their ability to personalize responses to user preferences remains limited. We introduce PrefEval, a benchmark for evaluating LLMs' ability to infer, memorize and adhere to user preferences in a long-context conversational setting. PrefEval comprises 3,000 manually curated user preference and query pairs spanning 20 topics. PrefEval contains user personalization or preference information in both explicit and implicit forms, and evaluates LLM performance using a generation and a classification task. With PrefEval, we evaluated the aforementioned preference following capabilities of 10 open-source and proprietary LLMs in multi-session conversations with varying context lengths up to 100k tokens. We benchmark with various prompting, iterative feedback, and retrieval-augmented generation methods. Our benchmarking effort reveals that state-of-the-art LLMs face significant challenges in proactively following users' preferences during conversations. In particular, in zero-shot settings, preference following accuracy falls below 10% at merely 10 turns (~3k tokens) across most evaluated models. Even with advanced prompting and retrieval methods, preference following still deteriorates in long-context conversations. Furthermore, we show that fine-tuning on PrefEval significantly improves performance. We believe PrefEval serves as a valuable resource for measuring, understanding, and enhancing LLMs' preference following abilities, paving the way for personalized conversational agents. Our code and dataset are available at https://prefeval.github.io/.
Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
Dec 17, 2024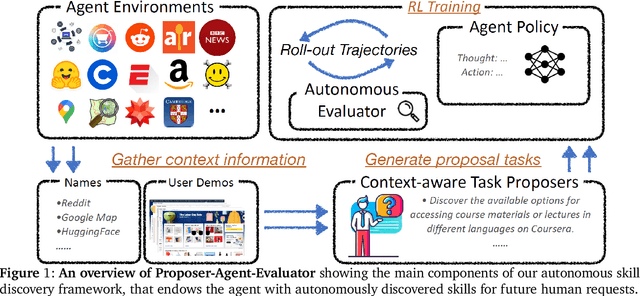
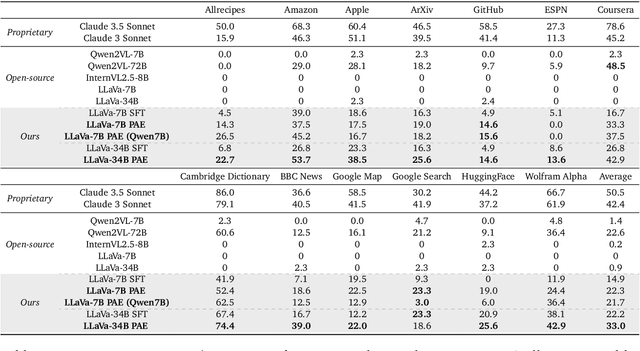
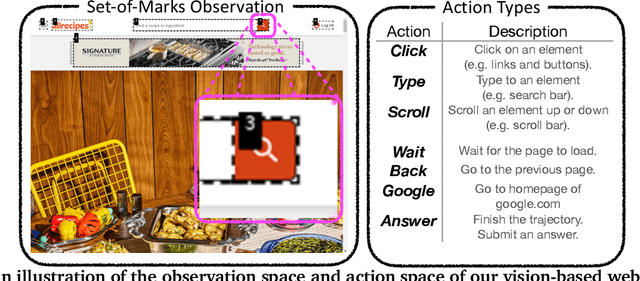
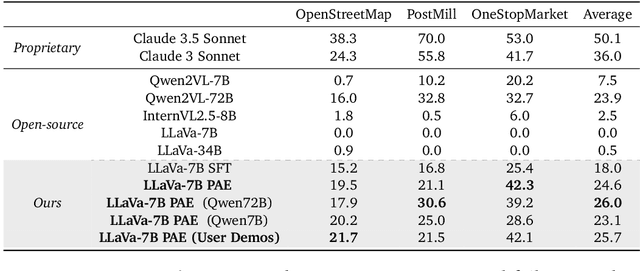
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/
Bootstrapping LLM-based Task-Oriented Dialogue Agents via Self-Talk
Jan 10, 2024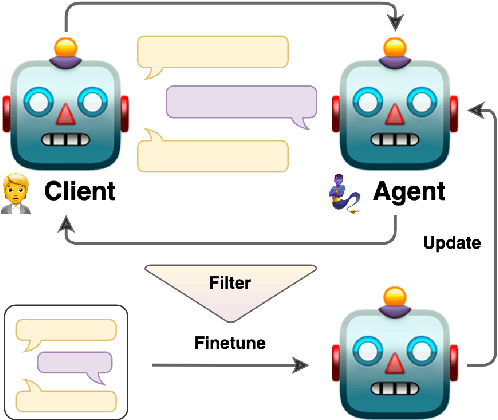

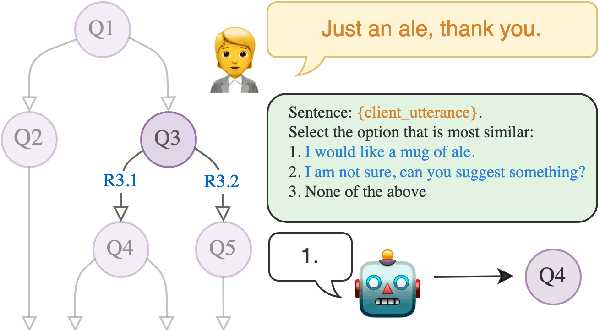

Large language models (LLMs) are powerful dialogue agents, but specializing them towards fulfilling a specific function can be challenging. Instructing tuning, i.e. tuning models on instruction and sample responses generated by humans (Ouyang et al., 2022), has proven as an effective method to do so, yet requires a number of data samples that a) might not be available or b) costly to generate. Furthermore, this cost increases when the goal is to make the LLM follow a specific workflow within a dialogue instead of single instructions. Inspired by the self-play technique in reinforcement learning and the use of LLMs to simulate human agents, we propose a more effective method for data collection through LLMs engaging in a conversation in various roles. This approach generates a training data via "self-talk" of LLMs that can be refined and utilized for supervised fine-tuning. We introduce an automated way to measure the (partial) success of a dialogue. This metric is used to filter the generated conversational data that is fed back in LLM for training. Based on our automated and human evaluations of conversation quality, we demonstrate that such self-talk data improves results. In addition, we examine the various characteristics that showcase the quality of generated dialogues and how they can be connected to their potential utility as training data.
Automated Few-shot Classification with Instruction-Finetuned Language Models
May 21, 2023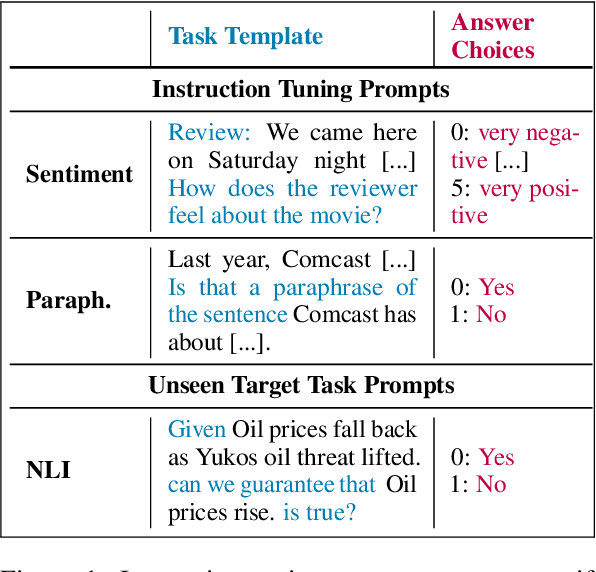

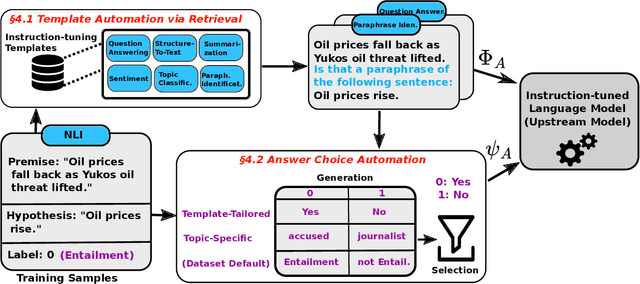
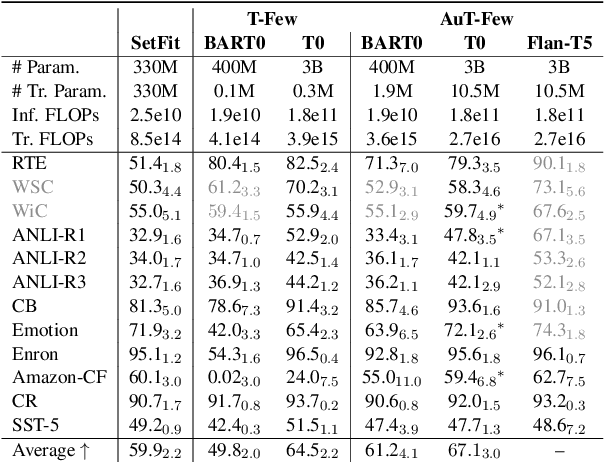
A particularly successful class of approaches for few-shot learning combines language models with prompts -- hand-crafted task descriptions that complement data samples. However, designing prompts by hand for each task commonly requires domain knowledge and substantial guesswork. We observe, in the context of classification tasks, that instruction finetuned language models exhibit remarkable prompt robustness, and we subsequently propose a simple method to eliminate the need for handcrafted prompts, named AuT-Few. This approach consists of (i) a prompt retrieval module that selects suitable task instructions from the instruction-tuning knowledge base, and (ii) the generation of two distinct, semantically meaningful, class descriptions and a selection mechanism via cross-validation. Over $12$ datasets, spanning $8$ classification tasks, we show that AuT-Few outperforms current state-of-the-art few-shot learning methods. Moreover, AuT-Few is the best ranking method across datasets on the RAFT few-shot benchmark. Notably, these results are achieved without task-specific handcrafted prompts on unseen tasks.
Parameter and Data Efficient Continual Pre-training for Robustness to Dialectal Variance in Arabic
Nov 08, 2022The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing models (by an avg metric of +$6.41$). We then explore two continual pre-training methods -- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks ($+4.64$ avg. gain) when used on monolingual models.
CH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Aug 26, 2022
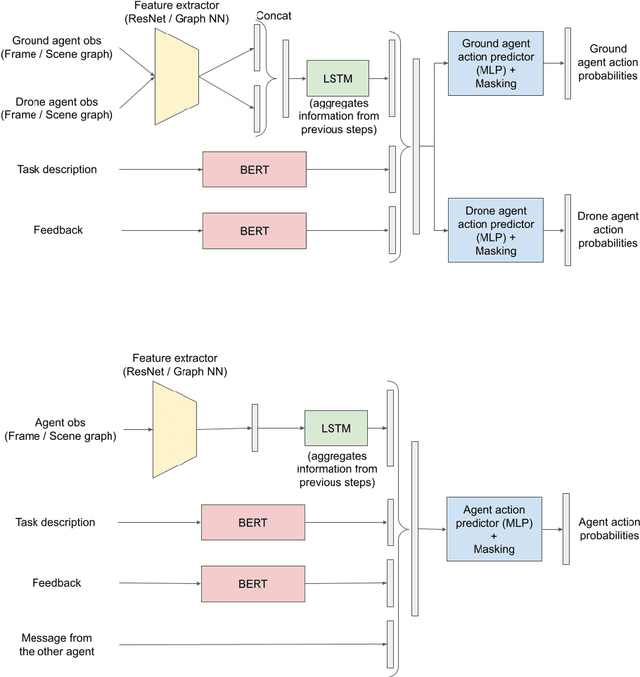


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.
DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following
Feb 27, 2022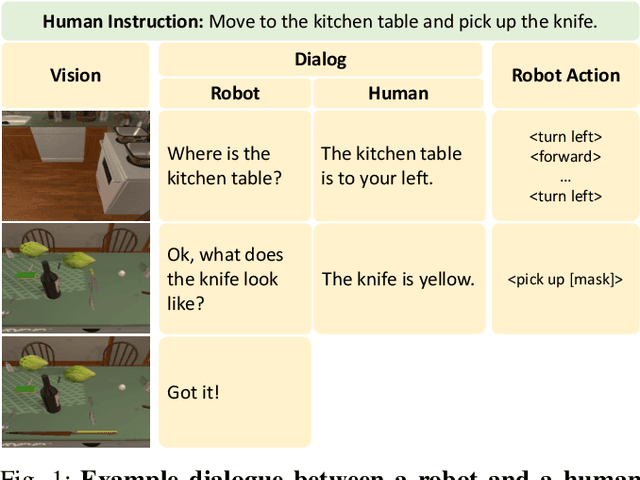

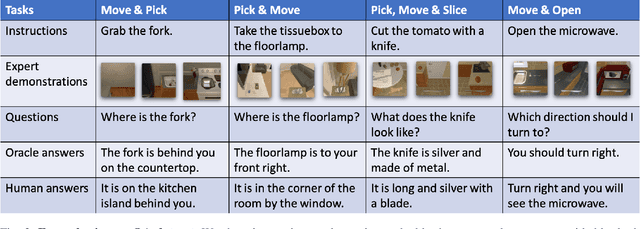
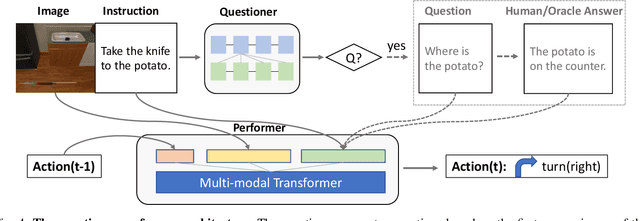
Language-guided Embodied AI benchmarks requiring an agent to navigate an environment and manipulate objects typically allow one-way communication: the human user gives a natural language command to the agent, and the agent can only follow the command passively. We present DialFRED, a dialogue-enabled embodied instruction following benchmark based on the ALFRED benchmark. DialFRED allows an agent to actively ask questions to the human user; the additional information in the user's response is used by the agent to better complete its task. We release a human-annotated dataset with 53K task-relevant questions and answers and an oracle to answer questions. To solve DialFRED, we propose a questioner-performer framework wherein the questioner is pre-trained with the human-annotated data and fine-tuned with reinforcement learning. We make DialFRED publicly available and encourage researchers to propose and evaluate their solutions to building dialog-enabled embodied agents.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022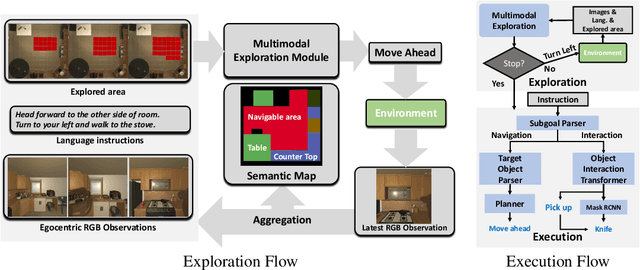

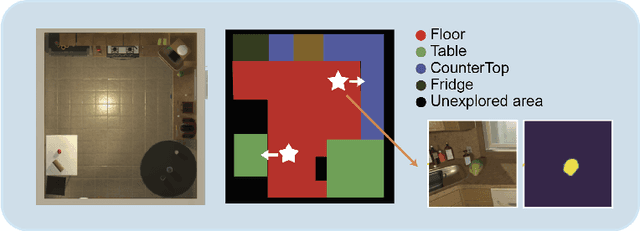
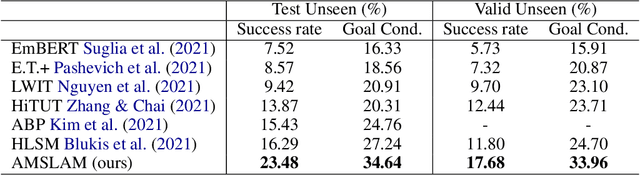
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
Learning Two-Step Hybrid Policy for Graph-Based Interpretable Reinforcement Learning
Jan 21, 2022
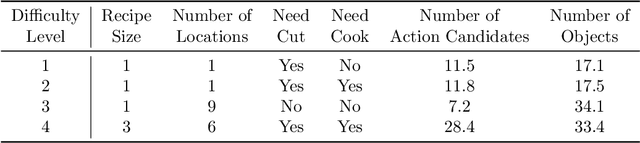
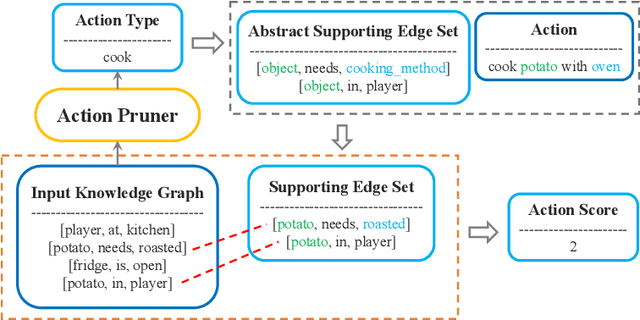
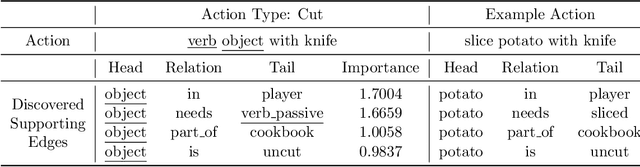
We present a two-step hybrid reinforcement learning (RL) policy that is designed to generate interpretable and robust hierarchical policies on the RL problem with graph-based input. Unlike prior deep reinforcement learning policies parameterized by an end-to-end black-box graph neural network, our approach disentangles the decision-making process into two steps. The first step is a simplified classification problem that maps the graph input to an action group where all actions share a similar semantic meaning. The second step implements a sophisticated rule-miner that conducts explicit one-hop reasoning over the graph and identifies decisive edges in the graph input without the necessity of heavy domain knowledge. This two-step hybrid policy presents human-friendly interpretations and achieves better performance in terms of generalization and robustness. Extensive experimental studies on four levels of complex text-based games have demonstrated the superiority of the proposed method compared to the state-of-the-art.
LUMINOUS: Indoor Scene Generation for Embodied AI Challenges
Nov 10, 2021

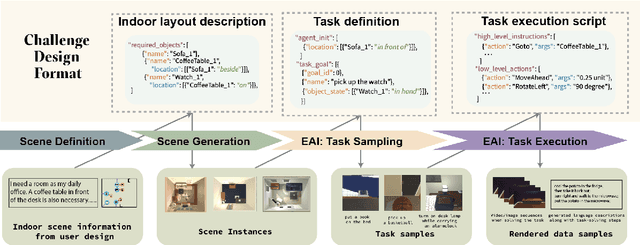
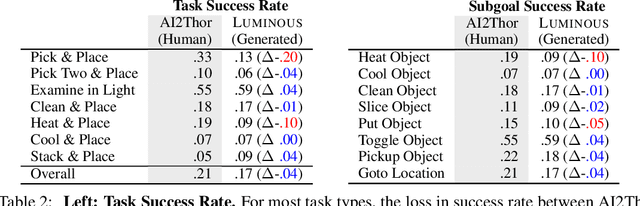
Learning-based methods for training embodied agents typically require a large number of high-quality scenes that contain realistic layouts and support meaningful interactions. However, current simulators for Embodied AI (EAI) challenges only provide simulated indoor scenes with a limited number of layouts. This paper presents Luminous, the first research framework that employs state-of-the-art indoor scene synthesis algorithms to generate large-scale simulated scenes for Embodied AI challenges. Further, we automatically and quantitatively evaluate the quality of generated indoor scenes via their ability to support complex household tasks. Luminous incorporates a novel scene generation algorithm (Constrained Stochastic Scene Generation (CSSG)), which achieves competitive performance with human-designed scenes. Within Luminous, the EAI task executor, task instruction generation module, and video rendering toolkit can collectively generate a massive multimodal dataset of new scenes for the training and evaluation of Embodied AI agents. Extensive experimental results demonstrate the effectiveness of the data generated by Luminous, enabling the comprehensive assessment of embodied agents on generalization and robustness.