 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Paper and Code
Aug 26, 2022
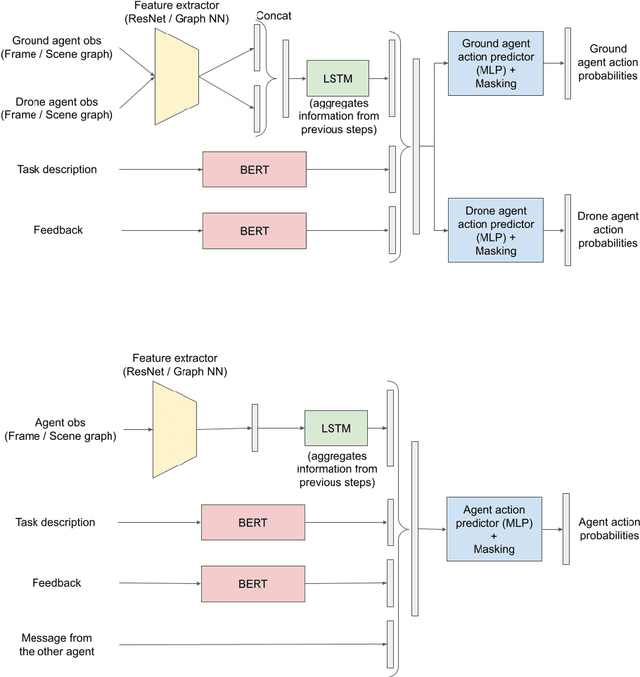


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.