 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Arena: Crowdsourcing Data Generation through Interactive Competition
Apr 20, 2026Post-training Large Language Models requires diverse, high-quality data which is rare and costly to obtain, especially in low resource domains and for multi-turn conversations. Common solutions are crowdsourcing or synthetic generation, but both often yield low-quality or low-diversity data. We introduce Adversarial Arena for building high quality conversational datasets by framing data generation as an adversarial task: attackers create prompts, and defenders generate responses. This interactive competition between multiple teams naturally produces diverse and complex data. We validated this approach by conducting a competition with 10 academic teams from top US and European universities, each building attacker or defender bots. The competition, focused on safety alignment of LLMs in cybersecurity, generated 19,683 multi-turn conversations. Fine-tuning an open-source model on this dataset produced an 18.47% improvement in secure code generation on CyberSecEval-Instruct and 29.42% improvement on CyberSecEval-MITRE.
Addressing LLM Diversity by Infusing Random Concepts
Jan 26, 2026Large language models (LLMs) are known to produce outputs with limited diversity. In this work, we study whether infusing random concepts in the prompts can improve the diversity of the generated outputs. To benchmark the approach, we design a systematic evaluation protocol which involves prompting an LLM with questions of the form "Name 10 Hollywood actors", and analyzing diversity measures of the resulting LLM outputs. Our experiments on multiple LLMs show that prepending random words/sentences unrelated to the prompt result in greater diversity in the outputs of LLMs. We believe that this promising result and the evaluation protocol opens up interesting avenues for future work, such as how infusing randomness into LLMs could be applied to other domains. Further, the evaluation protocol could also inspire research into benchmarking LLM diversity more systematically.
From Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025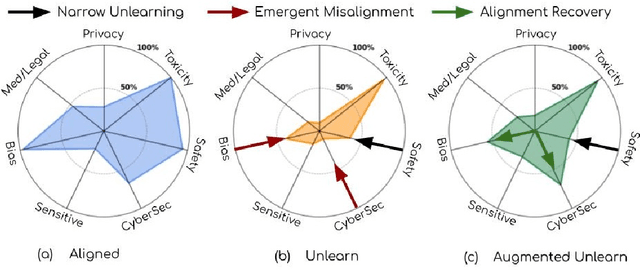
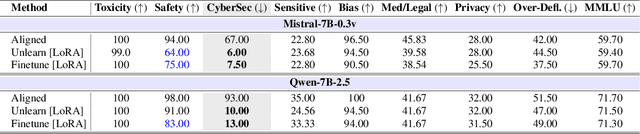
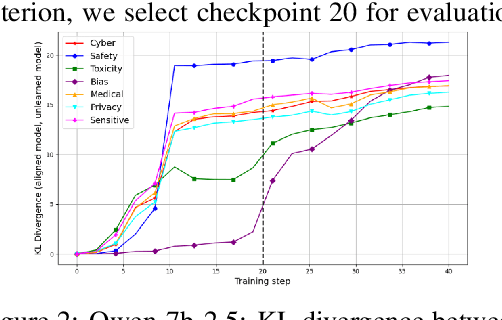
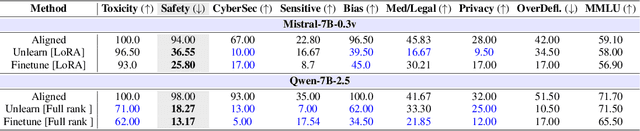
Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
Amazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
S-EQA: Tackling Situational Queries in Embodied Question Answering
May 08, 2024We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and quantifiable properties pertaining them, EQA with situational queries (such as "Is the bathroom clean and dry?") is more challenging, as the agent needs to figure out not just what the target objects pertaining to the query are, but also requires a consensus on their states to be answerable. Towards this objective, we first introduce a novel Prompt-Generate-Evaluate (PGE) scheme that wraps around an LLM's output to create a dataset of unique situational queries, corresponding consensus object information, and predicted answers. PGE maintains uniqueness among the generated queries, using multiple forms of semantic similarity. We validate the generated dataset via a large scale user-study conducted on M-Turk, and introduce it as S-EQA, the first dataset tackling EQA with situational queries. Our user study establishes the authenticity of S-EQA with a high 97.26% of the generated queries being deemed answerable, given the consensus object data. Conversely, we observe a low correlation of 46.2% on the LLM-predicted answers to human-evaluated ones; indicating the LLM's poor capability in directly answering situational queries, while establishing S-EQA's usability in providing a human-validated consensus for an indirect solution. We evaluate S-EQA via Visual Question Answering (VQA) on VirtualHome, which unlike other simulators, contains several objects with modifiable states that also visually appear different upon modification -- enabling us to set a quantitative benchmark for S-EQA. To the best of our knowledge, this is the first work to introduce EQA with situational queries, and also the first to use a generative approach for query creation.
"Don't forget to put the milk back!" Dataset for Enabling Embodied Agents to Detect Anomalous Situations
Apr 12, 2024Home robots intend to make their users lives easier. Our work assists in this goal by enabling robots to inform their users of dangerous or unsanitary anomalies in their home. Some examples of these anomalies include the user leaving their milk out, forgetting to turn off the stove, or leaving poison accessible to children. To move towards enabling home robots with these abilities, we have created a new dataset, which we call SafetyDetect. The SafetyDetect dataset consists of 1000 anomalous home scenes, each of which contains unsafe or unsanitary situations for an agent to detect. Our approach utilizes large language models (LLMs) alongside both a graph representation of the scene and the relationships between the objects in the scene. Our key insight is that this connected scene graph and the object relationships it encodes enables the LLM to better reason about the scene -- especially as it relates to detecting dangerous or unsanitary situations. Our most promising approach utilizes GPT-4 and pursues a categorization technique where object relations from the scene graph are classified as normal, dangerous, unsanitary, or dangerous for children. This method is able to correctly identify over 90% of anomalous scenarios in the SafetyDetect Dataset. Additionally, we conduct real world experiments on a ClearPath TurtleBot where we generate a scene graph from visuals of the real world scene, and run our approach with no modification. This setup resulted in little performance loss. The SafetyDetect Dataset and code will be released to the public upon this papers publication.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Language-guided Task Adaptation for Imitation Learning
Jan 24, 2023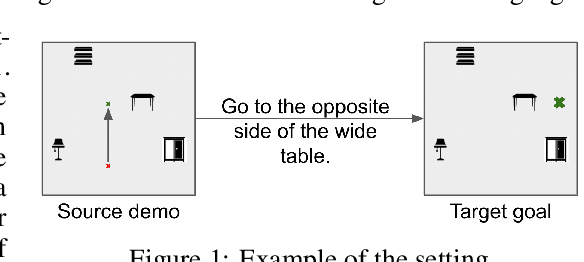



We introduce a novel setting, wherein an agent needs to learn a task from a demonstration of a related task with the difference between the tasks communicated in natural language. The proposed setting allows reusing demonstrations from other tasks, by providing low effort language descriptions, and can also be used to provide feedback to correct agent errors, which are both important desiderata for building intelligent agents that assist humans in daily tasks. To enable progress in this proposed setting, we create two benchmarks -- Room Rearrangement and Room Navigation -- that cover a diverse set of task adaptations. Further, we propose a framework that uses a transformer-based model to reason about the entities in the tasks and their relationships, to learn a policy for the target task
CH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Aug 26, 2022
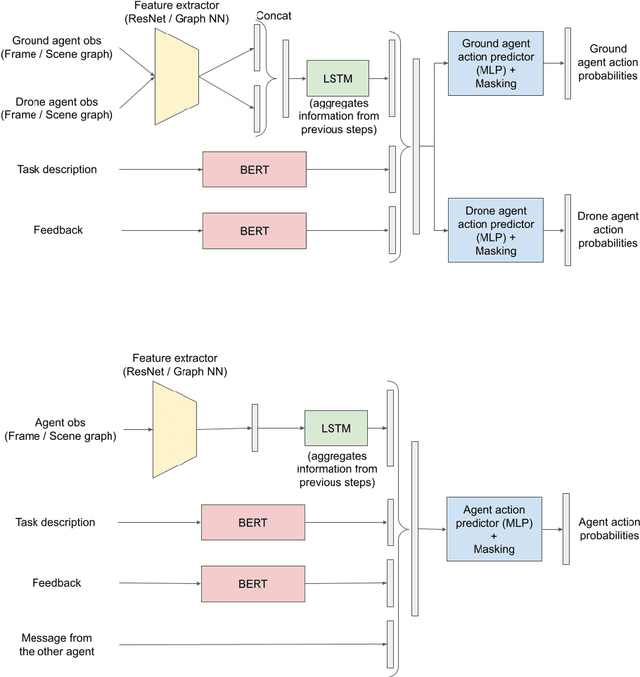


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.
Zero-shot Task Adaptation using Natural Language
Jun 05, 2021
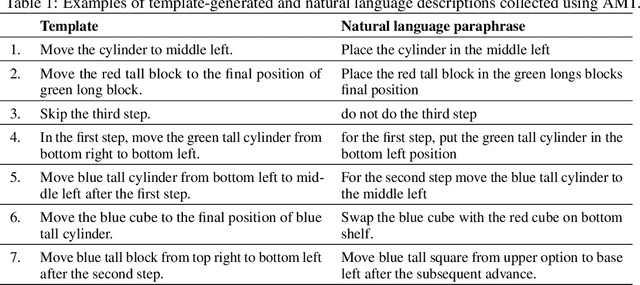
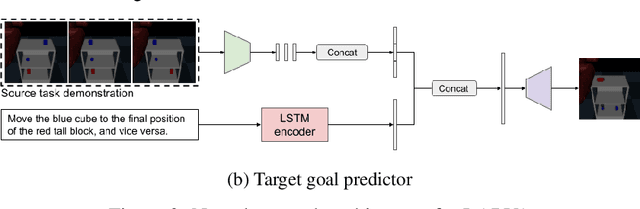
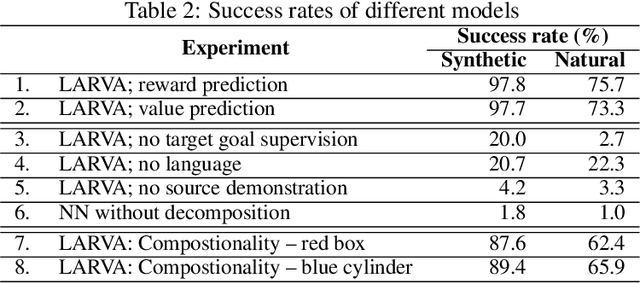
Imitation learning and instruction-following are two common approaches to communicate a user's intent to a learning agent. However, as the complexity of tasks grows, it could be beneficial to use both demonstrations and language to communicate with an agent. In this work, we propose a novel setting where an agent is given both a demonstration and a description, and must combine information from both the modalities. Specifically, given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task), our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language.