 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Task Adaptation using Natural Language
Paper and Code
Jun 05, 2021
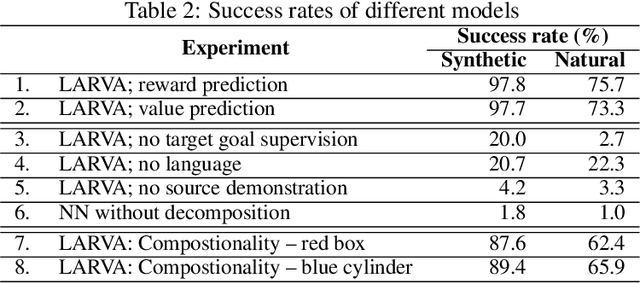
Imitation learning and instruction-following are two common approaches to communicate a user's intent to a learning agent. However, as the complexity of tasks grows, it could be beneficial to use both demonstrations and language to communicate with an agent. In this work, we propose a novel setting where an agent is given both a demonstration and a description, and must combine information from both the modalities. Specifically, given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task), our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language.