 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomeEmergency -- Using Audio to Find and Respond to Emergencies in the Home
Apr 01, 2025



In the United States alone accidental home deaths exceed 128,000 per year. Our work aims to enable home robots who respond to emergency scenarios in the home, preventing injuries and deaths. We introduce a new dataset of household emergencies based in the ThreeDWorld simulator. Each scenario in our dataset begins with an instantaneous or periodic sound which may or may not be an emergency. The agent must navigate the multi-room home scene using prior observations, alongside audio signals and images from the simulator, to determine if there is an emergency or not. In addition to our new dataset, we present a modular approach for localizing and identifying potential home emergencies. Underpinning our approach is a novel probabilistic dynamic scene graph (P-DSG), where our key insight is that graph nodes corresponding to agents can be represented with a probabilistic edge. This edge, when refined using Bayesian inference, enables efficient and effective localization of agents in the scene. We also utilize multi-modal vision-language models (VLMs) as a component in our approach, determining object traits (e.g. flammability) and identifying emergencies. We present a demonstration of our method completing a real-world version of our task on a consumer robot, showing the transferability of both our task and our method. Our dataset will be released to the public upon this papers publication.
"Don't forget to put the milk back!" Dataset for Enabling Embodied Agents to Detect Anomalous Situations
Apr 12, 2024Home robots intend to make their users lives easier. Our work assists in this goal by enabling robots to inform their users of dangerous or unsanitary anomalies in their home. Some examples of these anomalies include the user leaving their milk out, forgetting to turn off the stove, or leaving poison accessible to children. To move towards enabling home robots with these abilities, we have created a new dataset, which we call SafetyDetect. The SafetyDetect dataset consists of 1000 anomalous home scenes, each of which contains unsafe or unsanitary situations for an agent to detect. Our approach utilizes large language models (LLMs) alongside both a graph representation of the scene and the relationships between the objects in the scene. Our key insight is that this connected scene graph and the object relationships it encodes enables the LLM to better reason about the scene -- especially as it relates to detecting dangerous or unsanitary situations. Our most promising approach utilizes GPT-4 and pursues a categorization technique where object relations from the scene graph are classified as normal, dangerous, unsanitary, or dangerous for children. This method is able to correctly identify over 90% of anomalous scenarios in the SafetyDetect Dataset. Additionally, we conduct real world experiments on a ClearPath TurtleBot where we generate a scene graph from visuals of the real world scene, and run our approach with no modification. This setup resulted in little performance loss. The SafetyDetect Dataset and code will be released to the public upon this papers publication.
Placing Human Animations into 3D Scenes by Learning Interaction- and Geometry-Driven Keyframes
Sep 13, 2022
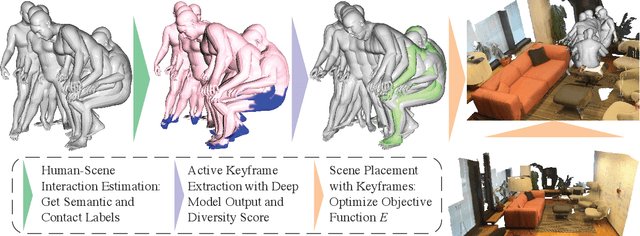
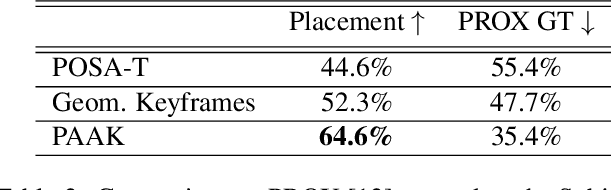
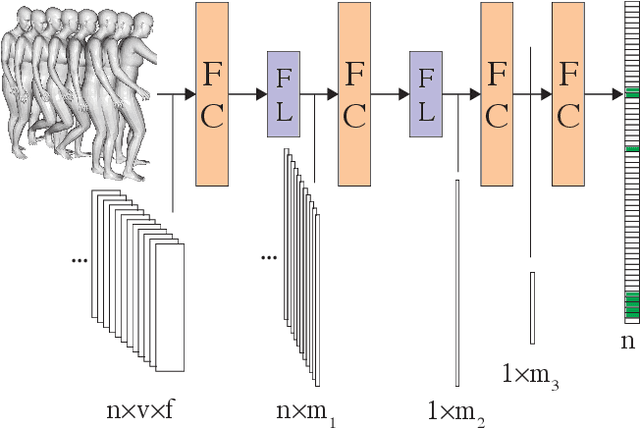
We present a novel method for placing a 3D human animation into a 3D scene while maintaining any human-scene interactions in the animation. We use the notion of computing the most important meshes in the animation for the interaction with the scene, which we call "keyframes." These keyframes allow us to better optimize the placement of the animation into the scene such that interactions in the animations (standing, laying, sitting, etc.) match the affordances of the scene (e.g., standing on the floor or laying in a bed). We compare our method, which we call PAAK, with prior approaches, including POSA, PROX ground truth, and a motion synthesis method, and highlight the benefits of our method with a perceptual study. Human raters preferred our PAAK method over the PROX ground truth data 64.6\% of the time. Additionally, in direct comparisons, the raters preferred PAAK over competing methods including 61.5\% compared to POSA.
Communicating Inferred Goals with Passive Augmented Reality and Active Haptic Feedback
Sep 03, 2021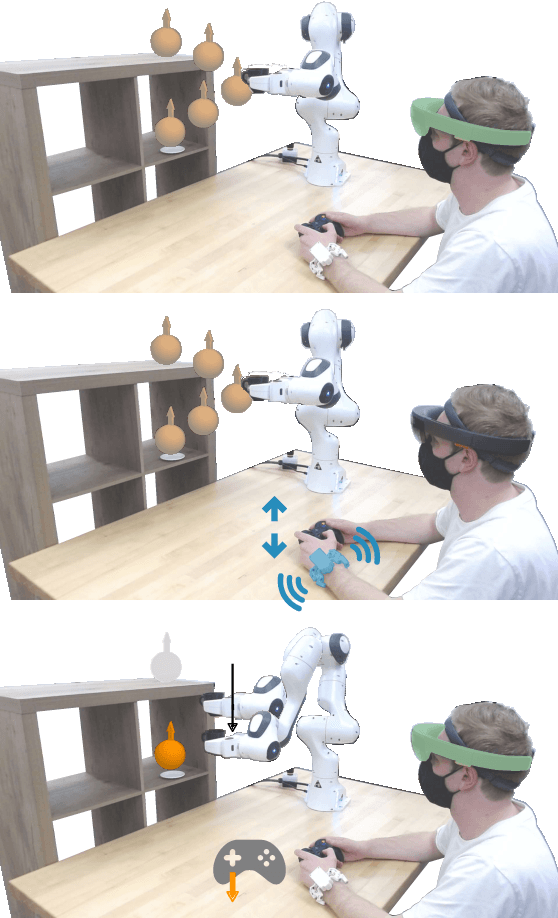
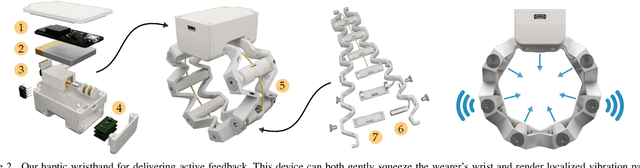

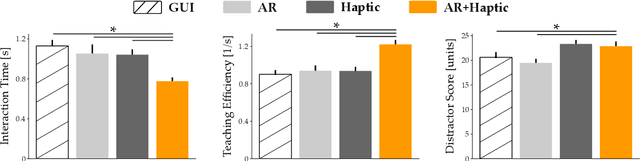
Robots learn as they interact with humans. Consider a human teleoperating an assistive robot arm: as the human guides and corrects the arm's motion, the robot gathers information about the human's desired task. But how does the human know what their robot has inferred? Today's approaches often focus on conveying intent: for instance, upon legible motions or gestures to indicate what the robot is planning. However, closing the loop on robot inference requires more than just revealing the robot's current policy: the robot should also display the alternatives it thinks are likely, and prompt the human teacher when additional guidance is necessary. In this paper we propose a multimodal approach for communicating robot inference that combines both passive and active feedback. Specifically, we leverage information-rich augmented reality to passively visualize what the robot has inferred, and attention-grabbing haptic wristbands to actively prompt and direct the human's teaching. We apply our system to shared autonomy tasks where the robot must infer the human's goal in real-time. Within this context, we integrate passive and active modalities into a single algorithmic framework that determines when and which type of feedback to provide. Combining both passive and active feedback experimentally outperforms single modality baselines; during an in-person user study, we demonstrate that our integrated approach increases how efficiently humans teach the robot while simultaneously decreasing the amount of time humans spend interacting with the robot. Videos here: https://youtu.be/swq_u4iIP-g