 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunicating Inferred Goals with Passive Augmented Reality and Active Haptic Feedback
Sep 03, 2021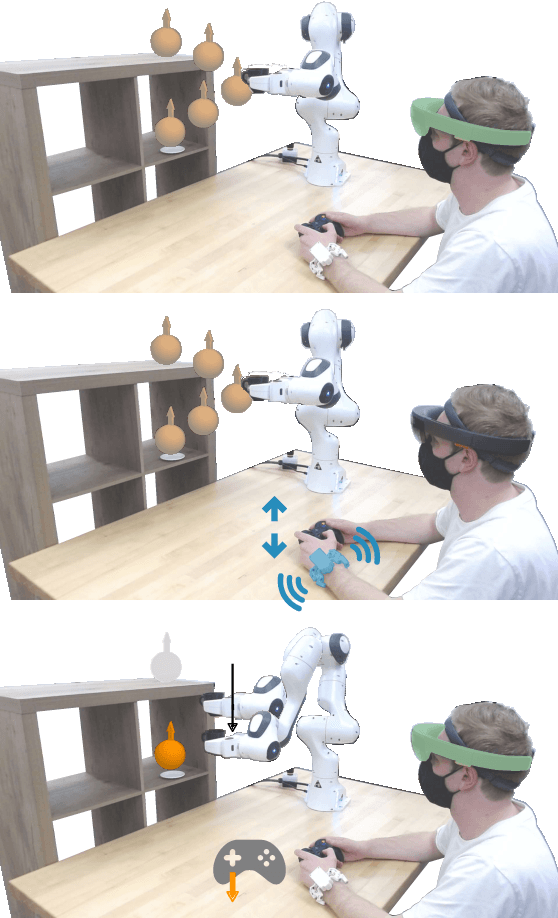
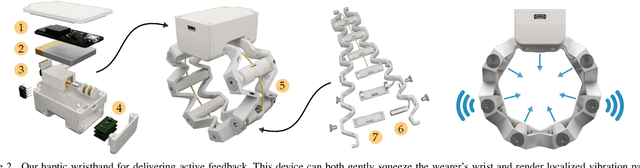

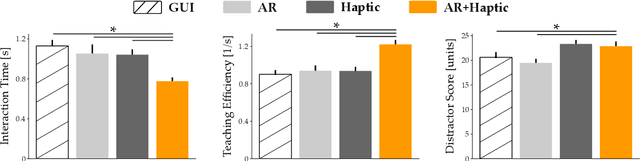
Robots learn as they interact with humans. Consider a human teleoperating an assistive robot arm: as the human guides and corrects the arm's motion, the robot gathers information about the human's desired task. But how does the human know what their robot has inferred? Today's approaches often focus on conveying intent: for instance, upon legible motions or gestures to indicate what the robot is planning. However, closing the loop on robot inference requires more than just revealing the robot's current policy: the robot should also display the alternatives it thinks are likely, and prompt the human teacher when additional guidance is necessary. In this paper we propose a multimodal approach for communicating robot inference that combines both passive and active feedback. Specifically, we leverage information-rich augmented reality to passively visualize what the robot has inferred, and attention-grabbing haptic wristbands to actively prompt and direct the human's teaching. We apply our system to shared autonomy tasks where the robot must infer the human's goal in real-time. Within this context, we integrate passive and active modalities into a single algorithmic framework that determines when and which type of feedback to provide. Combining both passive and active feedback experimentally outperforms single modality baselines; during an in-person user study, we demonstrate that our integrated approach increases how efficiently humans teach the robot while simultaneously decreasing the amount of time humans spend interacting with the robot. Videos here: https://youtu.be/swq_u4iIP-g