 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDSEval: A Meta-Evaluation Benchmark for Multimodal Dialogue Summarization
Oct 02, 2025Multimodal Dialogue Summarization (MDS) is a critical task with wide-ranging applications. To support the development of effective MDS models, robust automatic evaluation methods are essential for reducing both cost and human effort. However, such methods require a strong meta-evaluation benchmark grounded in human annotations. In this work, we introduce MDSEval, the first meta-evaluation benchmark for MDS, consisting image-sharing dialogues, corresponding summaries, and human judgments across eight well-defined quality aspects. To ensure data quality and richfulness, we propose a novel filtering framework leveraging Mutually Exclusive Key Information (MEKI) across modalities. Our work is the first to identify and formalize key evaluation dimensions specific to MDS. We benchmark state-of-the-art modal evaluation methods, revealing their limitations in distinguishing summaries from advanced MLLMs and their susceptibility to various bias.
VaPR -- Vision-language Preference alignment for Reasoning
Oct 02, 2025Preference finetuning methods like Direct Preference Optimization (DPO) with AI-generated feedback have shown promise in aligning Large Vision-Language Models (LVLMs) with human preferences. However, existing techniques overlook the prevalence of noise in synthetic preference annotations in the form of stylistic and length biases. To this end, we introduce a hard-negative response generation framework based on LLM-guided response editing, that produces rejected responses with targeted errors, maintaining stylistic and length similarity to the accepted ones. Using this framework, we develop the VaPR dataset, comprising 30K high-quality samples, to finetune three LVLM families: LLaVA-V1.5, Qwen2VL & Qwen2.5VL (2B-13B sizes). Our VaPR models deliver significant performance improvements across ten benchmarks, achieving average gains of 6.5% (LLaVA), 4.0% (Qwen2VL), and 1.5% (Qwen2.5VL), with notable improvements on reasoning tasks. A scaling analysis shows that performance consistently improves with data size, with LLaVA models benefiting even at smaller scales. Moreover, VaPR reduces the tendency to answer "Yes" in binary questions - addressing a common failure mode in LVLMs like LLaVA. Lastly, we show that the framework generalizes to open-source LLMs as editors, with models trained on VaPR-OS achieving ~99% of the performance of models trained on \name, which is synthesized using GPT-4o. Our data, models, and code can be found on the project page https://vap-r.github.io
Towards Internet-Scale Training For Agents
Feb 10, 2025



The predominant approach for training web navigation agents gathers human demonstrations for a set of popular websites and hand-written tasks, but it is becoming clear that human data are an inefficient resource. We develop a pipeline to facilitate Internet-scale training for agents without laborious human annotations. In the first stage, an LLM generates tasks for 150k diverse websites. In the next stage, LLM agents complete tasks and produce trajectories. In the final stage, an LLM reviews the trajectories and judges their success. Language models are competitive with human annotators, detecting and filtering out harmful content with an accuracy of 97%, generating feasible tasks with an 89% rate, and judging successful trajectories with an 82.6% accuracy. Scaling the pipeline, agents based on Llama 3.1 70B solve 16.7% of tasks for 150k sites. Training on the data generated by our pipeline is competitive with training on human demonstrations. In data-limited settings derived from Mind2Web and WebLINX, we improve Step Accuracy by up to +89.5% and +122.1% respectively for agents trained on mixtures of data from our pipeline, and human data. When training agents with all available human data from these benchmarks, agents fail to generalize to diverse real sites, and adding our data improves their generalization by +149.0% for WebLINX and +156.3% for Mind2Web. Code will be available at: data-for-agents.github.io.
T2V-Turbo-v2: Enhancing Video Generation Model Post-Training through Data, Reward, and Conditional Guidance Design
Oct 08, 2024



In this paper, we focus on enhancing a diffusion-based text-to-video (T2V) model during the post-training phase by distilling a highly capable consistency model from a pretrained T2V model. Our proposed method, T2V-Turbo-v2, introduces a significant advancement by integrating various supervision signals, including high-quality training data, reward model feedback, and conditional guidance, into the consistency distillation process. Through comprehensive ablation studies, we highlight the crucial importance of tailoring datasets to specific learning objectives and the effectiveness of learning from diverse reward models for enhancing both the visual quality and text-video alignment. Additionally, we highlight the vast design space of conditional guidance strategies, which centers on designing an effective energy function to augment the teacher ODE solver. We demonstrate the potential of this approach by extracting motion guidance from the training datasets and incorporating it into the ODE solver, showcasing its effectiveness in improving the motion quality of the generated videos with the improved motion-related metrics from VBench and T2V-CompBench. Empirically, our T2V-Turbo-v2 establishes a new state-of-the-art result on VBench, with a Total score of 85.13, surpassing proprietary systems such as Gen-3 and Kling.
S-EQA: Tackling Situational Queries in Embodied Question Answering
May 08, 2024We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and quantifiable properties pertaining them, EQA with situational queries (such as "Is the bathroom clean and dry?") is more challenging, as the agent needs to figure out not just what the target objects pertaining to the query are, but also requires a consensus on their states to be answerable. Towards this objective, we first introduce a novel Prompt-Generate-Evaluate (PGE) scheme that wraps around an LLM's output to create a dataset of unique situational queries, corresponding consensus object information, and predicted answers. PGE maintains uniqueness among the generated queries, using multiple forms of semantic similarity. We validate the generated dataset via a large scale user-study conducted on M-Turk, and introduce it as S-EQA, the first dataset tackling EQA with situational queries. Our user study establishes the authenticity of S-EQA with a high 97.26% of the generated queries being deemed answerable, given the consensus object data. Conversely, we observe a low correlation of 46.2% on the LLM-predicted answers to human-evaluated ones; indicating the LLM's poor capability in directly answering situational queries, while establishing S-EQA's usability in providing a human-validated consensus for an indirect solution. We evaluate S-EQA via Visual Question Answering (VQA) on VirtualHome, which unlike other simulators, contains several objects with modifiable states that also visually appear different upon modification -- enabling us to set a quantitative benchmark for S-EQA. To the best of our knowledge, this is the first work to introduce EQA with situational queries, and also the first to use a generative approach for query creation.
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
May 08, 2024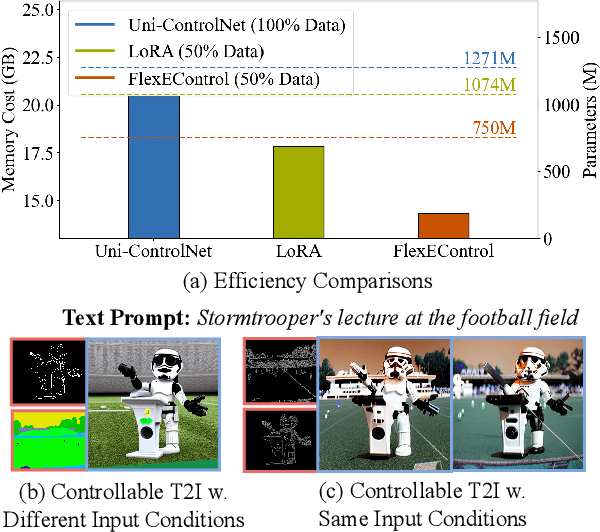

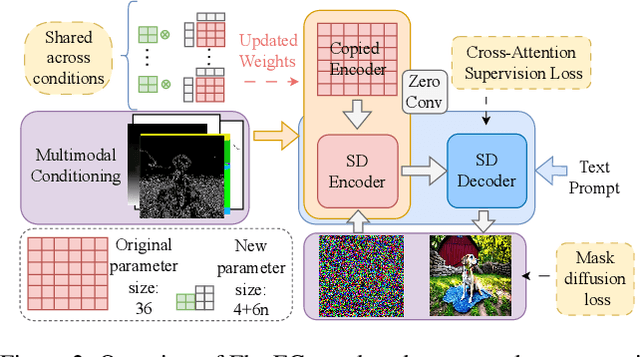
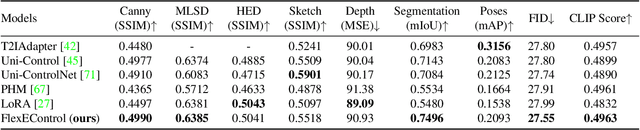
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
"Don't forget to put the milk back!" Dataset for Enabling Embodied Agents to Detect Anomalous Situations
Apr 12, 2024Home robots intend to make their users lives easier. Our work assists in this goal by enabling robots to inform their users of dangerous or unsanitary anomalies in their home. Some examples of these anomalies include the user leaving their milk out, forgetting to turn off the stove, or leaving poison accessible to children. To move towards enabling home robots with these abilities, we have created a new dataset, which we call SafetyDetect. The SafetyDetect dataset consists of 1000 anomalous home scenes, each of which contains unsafe or unsanitary situations for an agent to detect. Our approach utilizes large language models (LLMs) alongside both a graph representation of the scene and the relationships between the objects in the scene. Our key insight is that this connected scene graph and the object relationships it encodes enables the LLM to better reason about the scene -- especially as it relates to detecting dangerous or unsanitary situations. Our most promising approach utilizes GPT-4 and pursues a categorization technique where object relations from the scene graph are classified as normal, dangerous, unsanitary, or dangerous for children. This method is able to correctly identify over 90% of anomalous scenarios in the SafetyDetect Dataset. Additionally, we conduct real world experiments on a ClearPath TurtleBot where we generate a scene graph from visuals of the real world scene, and run our approach with no modification. This setup resulted in little performance loss. The SafetyDetect Dataset and code will be released to the public upon this papers publication.
E-ViLM: Efficient Video-Language Model via Masked Video Modeling with Semantic Vector-Quantized Tokenizer
Nov 28, 2023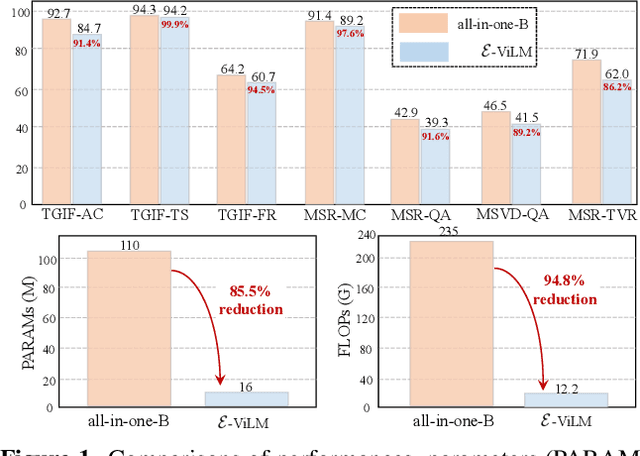
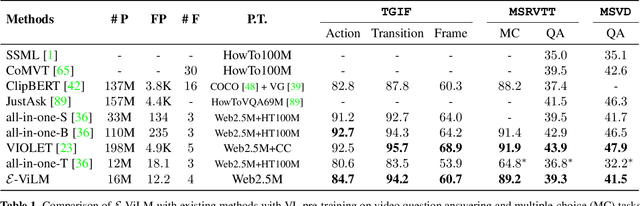
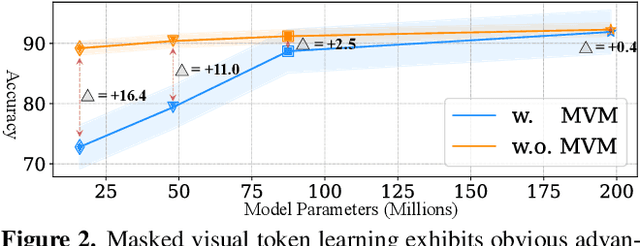
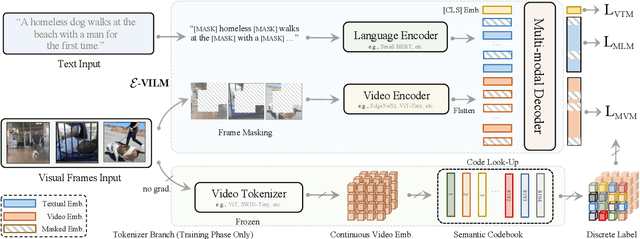
To build scalable models for challenging real-world tasks, it is important to learn from diverse, multi-modal data in various forms (e.g., videos, text, and images). Among the existing works, a plethora of them have focused on leveraging large but cumbersome cross-modal architectures. Regardless of their effectiveness, larger architectures unavoidably prevent the models from being extended to real-world applications, so building a lightweight VL architecture and an efficient learning schema is of great practical value. In this paper, we propose an Efficient Video-Language Model (dubbed as E-ViLM) and a masked video modeling (MVM) schema, assisted with a semantic vector-quantized tokenizer. In particular, our E-ViLM learns to reconstruct the semantic labels of masked video regions, produced by the pre-trained vector-quantized tokenizer, which discretizes the continuous visual signals into labels. We show that with our simple MVM task and regular VL pre-training modelings, our E-ViLM, despite its compactness, is able to learn expressive representations from Video-Language corpus and generalize well to extensive Video-Language tasks including video question answering, text-to-video retrieval, etc. In particular, our E-ViLM obtains obvious efficiency improvements by reaching competing performances with faster inference speed, i.e., our model reaches $39.3$% Top-$1$ accuracy on the MSRVTT benchmark, retaining $91.4$% of the accuracy of state-of-the-art larger VL architecture with only $15%$ parameters and $94.8%$ fewer GFLOPs. We also provide extensive ablative studies that validate the effectiveness of our proposed learning schema for E-ViLM.
Characterizing Video Question Answering with Sparsified Inputs
Nov 27, 2023



In Video Question Answering, videos are often processed as a full-length sequence of frames to ensure minimal loss of information. Recent works have demonstrated evidence that sparse video inputs are sufficient to maintain high performance. However, they usually discuss the case of single frame selection. In our work, we extend the setting to multiple number of inputs and other modalities. We characterize the task with different input sparsity and provide a tool for doing that. Specifically, we use a Gumbel-based learnable selection module to adaptively select the best inputs for the final task. In this way, we experiment over public VideoQA benchmarks and provide analysis on how sparsified inputs affect the performance. From our experiments, we have observed only 5.2%-5.8% loss of performance with only 10% of video lengths, which corresponds to 2-4 frames selected from each video. Meanwhile, we also observed the complimentary behaviour between visual and textual inputs, even under highly sparsified settings, suggesting the potential of improving data efficiency for video-and-language tasks.
Decision Making for Human-in-the-loop Robotic Agents via Uncertainty-Aware Reinforcement Learning
Mar 14, 2023In a Human-in-the-Loop paradigm, a robotic agent is able to act mostly autonomously in solving a task, but can request help from an external expert when needed. However, knowing when to request such assistance is critical: too few requests can lead to the robot making mistakes, but too many requests can overload the expert. In this paper, we present a Reinforcement Learning based approach to this problem, where a semi-autonomous agent asks for external assistance when it has low confidence in the eventual success of the task. The confidence level is computed by estimating the variance of the return from the current state. We show that this estimate can be iteratively improved during training using a Bellman-like recursion. On discrete navigation problems with both fully- and partially-observable state information, we show that our method makes effective use of a limited budget of expert calls at run-time, despite having no access to the expert at training time.