 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-ViLM: Efficient Video-Language Model via Masked Video Modeling with Semantic Vector-Quantized Tokenizer
Paper and Code
Nov 28, 2023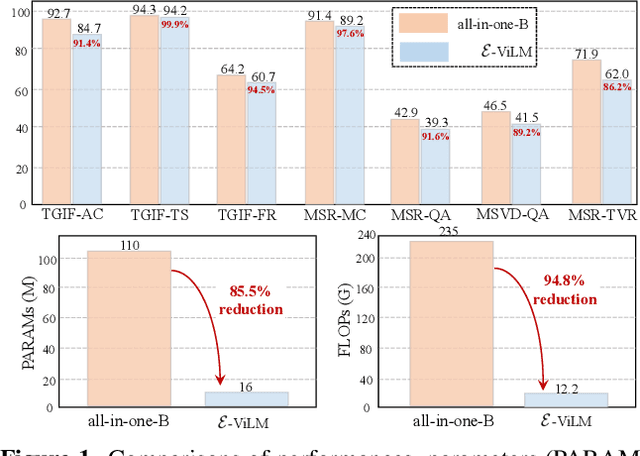
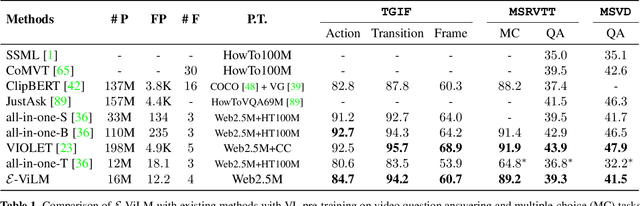
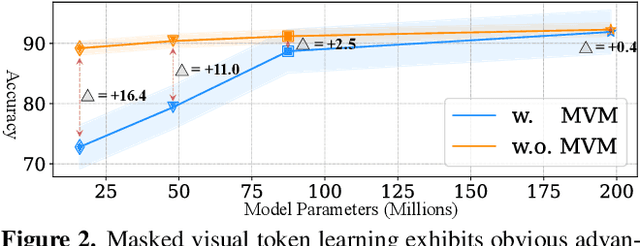
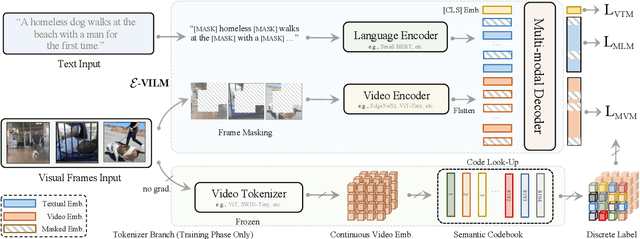
To build scalable models for challenging real-world tasks, it is important to learn from diverse, multi-modal data in various forms (e.g., videos, text, and images). Among the existing works, a plethora of them have focused on leveraging large but cumbersome cross-modal architectures. Regardless of their effectiveness, larger architectures unavoidably prevent the models from being extended to real-world applications, so building a lightweight VL architecture and an efficient learning schema is of great practical value. In this paper, we propose an Efficient Video-Language Model (dubbed as E-ViLM) and a masked video modeling (MVM) schema, assisted with a semantic vector-quantized tokenizer. In particular, our E-ViLM learns to reconstruct the semantic labels of masked video regions, produced by the pre-trained vector-quantized tokenizer, which discretizes the continuous visual signals into labels. We show that with our simple MVM task and regular VL pre-training modelings, our E-ViLM, despite its compactness, is able to learn expressive representations from Video-Language corpus and generalize well to extensive Video-Language tasks including video question answering, text-to-video retrieval, etc. In particular, our E-ViLM obtains obvious efficiency improvements by reaching competing performances with faster inference speed, i.e., our model reaches $39.3$% Top-$1$ accuracy on the MSRVTT benchmark, retaining $91.4$% of the accuracy of state-of-the-art larger VL architecture with only $15%$ parameters and $94.8%$ fewer GFLOPs. We also provide extensive ablative studies that validate the effectiveness of our proposed learning schema for E-ViLM.