 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling World Model for Hierarchical Manipulation Policies
Feb 12, 2026Vision-Language-Action (VLA) models are promising for generalist robot manipulation but remain brittle in out-of-distribution (OOD) settings, especially with limited real-robot data. To resolve the generalization bottleneck, we introduce a hierarchical Vision-Language-Action framework \our{} that leverages the generalization of large-scale pre-trained world model for robust and generalizable VIsual Subgoal TAsk decomposition VISTA. Our hierarchical framework \our{} consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios. We validate both visual goal synthesis and our hierarchical VLA policies in massive out-of-distribution scenarios, and the performance of the same-structured VLA in novel scenarios could boost from 14% to 69% with the guidance generated by the world model. Results demonstrate that our method outperforms previous baselines with a clear margin, particularly in out-of-distribution scenarios. Project page: \href{https://vista-wm.github.io/}{https://vista-wm.github.io}
Muon-Accelerated Attention Distillation for Real-Time Edge Synthesis via Optimized Latent Diffusion
Apr 11, 2025Recent advances in visual synthesis have leveraged diffusion models and attention mechanisms to achieve high-fidelity artistic style transfer and photorealistic text-to-image generation. However, real-time deployment on edge devices remains challenging due to computational and memory constraints. We propose Muon-AD, a co-designed framework that integrates the Muon optimizer with attention distillation for real-time edge synthesis. By eliminating gradient conflicts through orthogonal parameter updates and dynamic pruning, Muon-AD achieves 3.2 times faster convergence compared to Stable Diffusion-TensorRT, while maintaining synthesis quality (15% lower FID, 4% higher SSIM). Our framework reduces peak memory to 7GB on Jetson Orin and enables 24FPS real-time generation through mixed-precision quantization and curriculum learning. Extensive experiments on COCO-Stuff and ImageNet-Texture demonstrate Muon-AD's Pareto-optimal efficiency-quality trade-offs. Here, we show a 65% reduction in communication overhead during distributed training and real-time 10s/image generation on edge GPUs. These advancements pave the way for democratizing high-quality visual synthesis in resource-constrained environments.
TeamCraft: A Benchmark for Multi-Modal Multi-Agent Systems in Minecraft
Dec 06, 2024



Collaboration is a cornerstone of society. In the real world, human teammates make use of multi-sensory data to tackle challenging tasks in ever-changing environments. It is essential for embodied agents collaborating in visually-rich environments replete with dynamic interactions to understand multi-modal observations and task specifications. To evaluate the performance of generalizable multi-modal collaborative agents, we present TeamCraft, a multi-modal multi-agent benchmark built on top of the open-world video game Minecraft. The benchmark features 55,000 task variants specified by multi-modal prompts, procedurally-generated expert demonstrations for imitation learning, and carefully designed protocols to evaluate model generalization capabilities. We also perform extensive analyses to better understand the limitations and strengths of existing approaches. Our results indicate that existing models continue to face significant challenges in generalizing to novel goals, scenes, and unseen numbers of agents. These findings underscore the need for further research in this area. The TeamCraft platform and dataset are publicly available at https://github.com/teamcraft-bench/teamcraft.
Inverse Attention Agent for Multi-Agent System
Oct 29, 2024
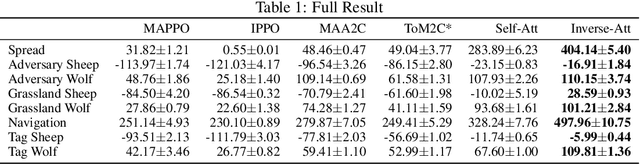

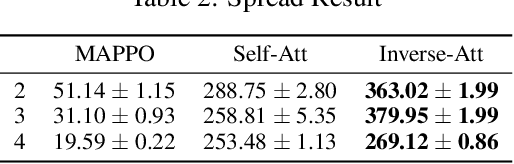
A major challenge for Multi-Agent Systems is enabling agents to adapt dynamically to diverse environments in which opponents and teammates may continually change. Agents trained using conventional methods tend to excel only within the confines of their training cohorts; their performance drops significantly when confronting unfamiliar agents. To address this shortcoming, we introduce Inverse Attention Agents that adopt concepts from the Theory of Mind, implemented algorithmically using an attention mechanism and trained in an end-to-end manner. Crucial to determining the final actions of these agents, the weights in their attention model explicitly represent attention to different goals. We furthermore propose an inverse attention network that deduces the ToM of agents based on observations and prior actions. The network infers the attentional states of other agents, thereby refining the attention weights to adjust the agent's final action. We conduct experiments in a continuous environment, tackling demanding tasks encompassing cooperation, competition, and a blend of both. They demonstrate that the inverse attention network successfully infers the attention of other agents, and that this information improves agent performance. Additional human experiments show that, compared to baseline agent models, our inverse attention agents exhibit superior cooperation with humans and better emulate human behaviors.
T2V-Turbo-v2: Enhancing Video Generation Model Post-Training through Data, Reward, and Conditional Guidance Design
Oct 08, 2024



In this paper, we focus on enhancing a diffusion-based text-to-video (T2V) model during the post-training phase by distilling a highly capable consistency model from a pretrained T2V model. Our proposed method, T2V-Turbo-v2, introduces a significant advancement by integrating various supervision signals, including high-quality training data, reward model feedback, and conditional guidance, into the consistency distillation process. Through comprehensive ablation studies, we highlight the crucial importance of tailoring datasets to specific learning objectives and the effectiveness of learning from diverse reward models for enhancing both the visual quality and text-video alignment. Additionally, we highlight the vast design space of conditional guidance strategies, which centers on designing an effective energy function to augment the teacher ODE solver. We demonstrate the potential of this approach by extracting motion guidance from the training datasets and incorporating it into the ODE solver, showcasing its effectiveness in improving the motion quality of the generated videos with the improved motion-related metrics from VBench and T2V-CompBench. Empirically, our T2V-Turbo-v2 establishes a new state-of-the-art result on VBench, with a Total score of 85.13, surpassing proprietary systems such as Gen-3 and Kling.
SocialGFs: Learning Social Gradient Fields for Multi-Agent Reinforcement Learning
May 03, 2024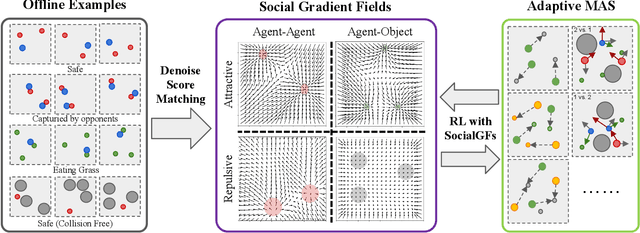
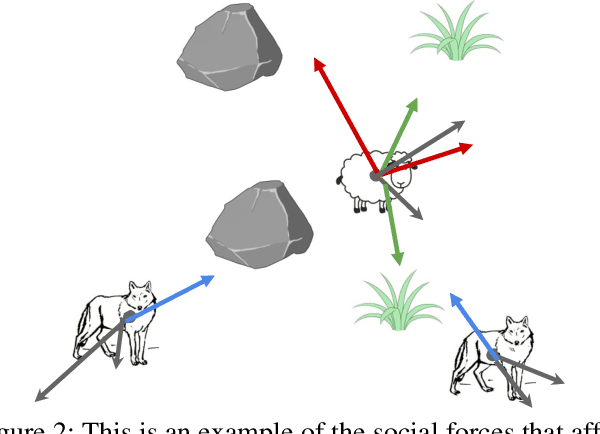

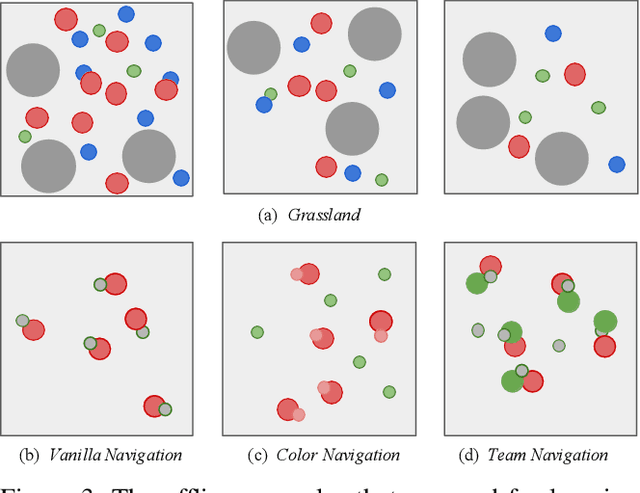
Multi-agent systems (MAS) need to adaptively cope with dynamic environments, changing agent populations, and diverse tasks. However, most of the multi-agent systems cannot easily handle them, due to the complexity of the state and task space. The social impact theory regards the complex influencing factors as forces acting on an agent, emanating from the environment, other agents, and the agent's intrinsic motivation, referring to the social force. Inspired by this concept, we propose a novel gradient-based state representation for multi-agent reinforcement learning. To non-trivially model the social forces, we further introduce a data-driven method, where we employ denoising score matching to learn the social gradient fields (SocialGFs) from offline samples, e.g., the attractive or repulsive outcomes of each force. During interactions, the agents take actions based on the multi-dimensional gradients to maximize their own rewards. In practice, we integrate SocialGFs into the widely used multi-agent reinforcement learning algorithms, e.g., MAPPO. The empirical results reveal that SocialGFs offer four advantages for multi-agent systems: 1) they can be learned without requiring online interaction, 2) they demonstrate transferability across diverse tasks, 3) they facilitate credit assignment in challenging reward settings, and 4) they are scalable with the increasing number of agents.
Sim2Plan: Robot Motion Planning via Message Passing between Simulation and Reality
Jul 15, 2023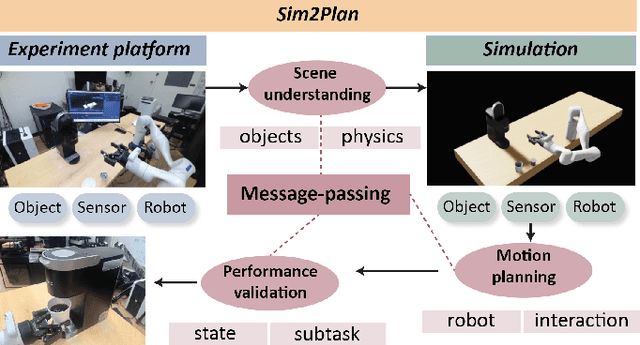
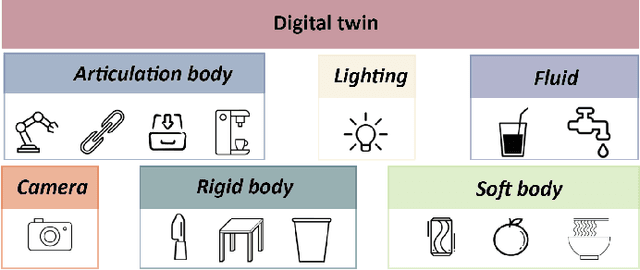

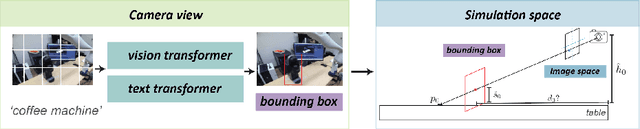
Simulation-to-real is the task of training and developing machine learning models and deploying them in real settings with minimal additional training. This approach is becoming increasingly popular in fields such as robotics. However, there is often a gap between the simulated environment and the real world, and machine learning models trained in simulation may not perform as well in the real world. We propose a framework that utilizes a message-passing pipeline to minimize the information gap between simulation and reality. The message-passing pipeline is comprised of three modules: scene understanding, robot planning, and performance validation. First, the scene understanding module aims to match the scene layout between the real environment set-up and its digital twin. Then, the robot planning module solves a robotic task through trial and error in the simulation. Finally, the performance validation module varies the planning results by constantly checking the status difference of the robot and object status between the real set-up and the simulation. In the experiment, we perform a case study that requires a robot to make a cup of coffee. Results show that the robot is able to complete the task under our framework successfully. The robot follows the steps programmed into its system and utilizes its actuators to interact with the coffee machine and other tools required for the task. The results of this case study demonstrate the potential benefits of our method that drive robots for tasks that require precision and efficiency. Further research in this area could lead to the development of even more versatile and adaptable robots, opening up new possibilities for automation in various industries.
Evolutionary Population Curriculum for Scaling Multi-Agent Reinforcement Learning
Mar 23, 2020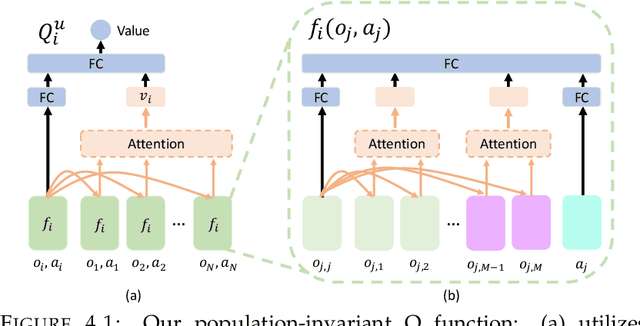
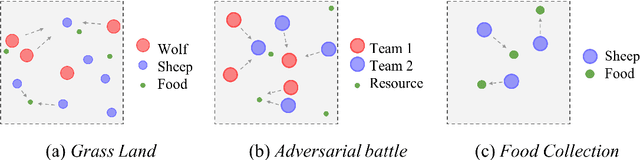
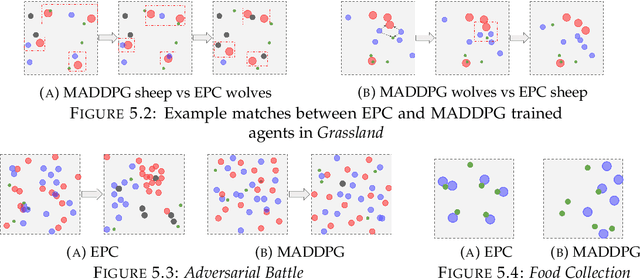

In multi-agent games, the complexity of the environment can grow exponentially as the number of agents increases, so it is particularly challenging to learn good policies when the agent population is large. In this paper, we introduce Evolutionary Population Curriculum (EPC), a curriculum learning paradigm that scales up Multi-Agent Reinforcement Learning (MARL) by progressively increasing the population of training agents in a stage-wise manner. Furthermore, EPC uses an evolutionary approach to fix an objective misalignment issue throughout the curriculum: agents successfully trained in an early stage with a small population are not necessarily the best candidates for adapting to later stages with scaled populations. Concretely, EPC maintains multiple sets of agents in each stage, performs mix-and-match and fine-tuning over these sets and promotes the sets of agents with the best adaptability to the next stage. We implement EPC on a popular MARL algorithm, MADDPG, and empirically show that our approach consistently outperforms baselines by a large margin as the number of agents grows exponentially.
A Robust Real-Time Computing-based Environment Sensing System for Intelligent Vehicle
Jan 27, 2020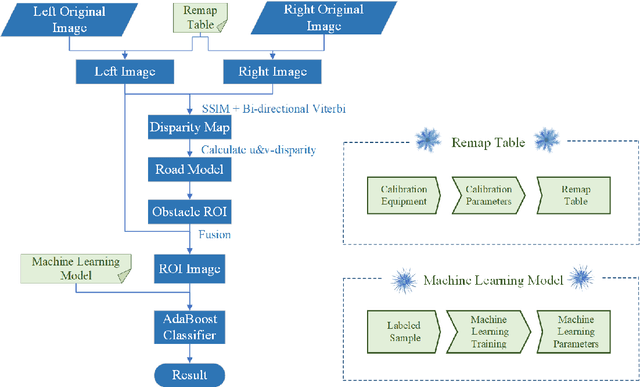
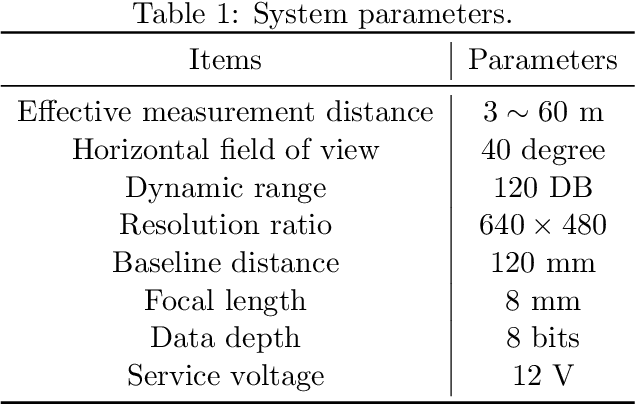
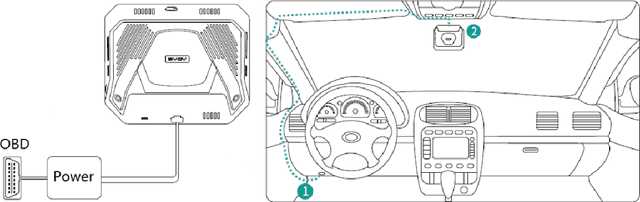

For intelligent vehicles, sensing the 3D environment is the first but crucial step. In this paper, we build a real-time advanced driver assistance system based on a low-power mobile platform. The system is a real-time multi-scheme integrated innovation system, which combines stereo matching algorithm with machine learning based obstacle detection approach and takes advantage of the distributed computing technology of a mobile platform with GPU and CPUs. First of all, a multi-scale fast MPV (Multi-Path-Viterbi) stereo matching algorithm is proposed, which can generate robust and accurate disparity map. Then a machine learning, which is based on fusion technology of monocular and binocular, is applied to detect the obstacles. We also advance an automatic fast calibration mechanism based on Zhang's calibration method. Finally, the distributed computing and reasonable data flow programming are applied to ensure the operational efficiency of the system. The experimental results show that the system can achieve robust and accurate real-time environment perception for intelligent vehicles, which can be directly used in the commercial real-time intelligent driving applications.