 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialGFs: Learning Social Gradient Fields for Multi-Agent Reinforcement Learning
Paper and Code
May 03, 2024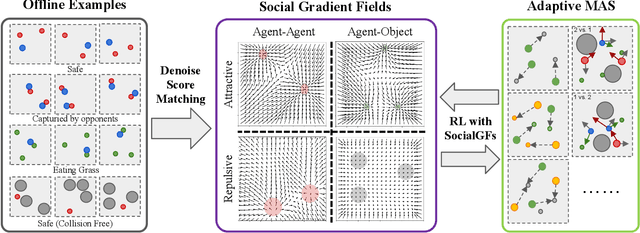
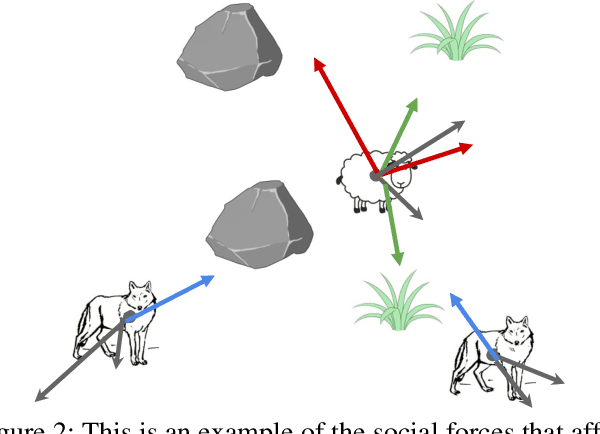

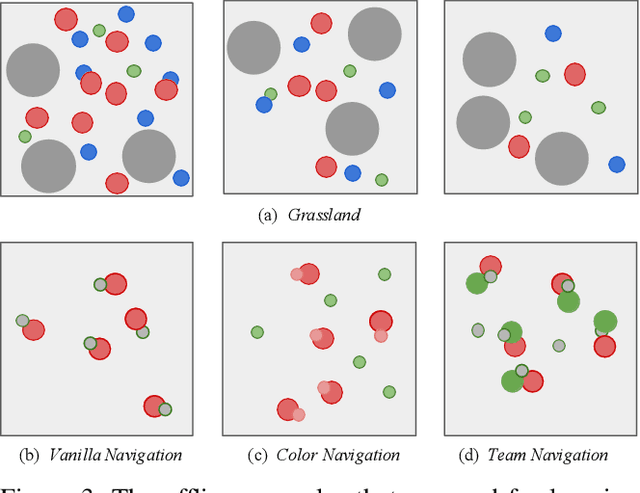
Multi-agent systems (MAS) need to adaptively cope with dynamic environments, changing agent populations, and diverse tasks. However, most of the multi-agent systems cannot easily handle them, due to the complexity of the state and task space. The social impact theory regards the complex influencing factors as forces acting on an agent, emanating from the environment, other agents, and the agent's intrinsic motivation, referring to the social force. Inspired by this concept, we propose a novel gradient-based state representation for multi-agent reinforcement learning. To non-trivially model the social forces, we further introduce a data-driven method, where we employ denoising score matching to learn the social gradient fields (SocialGFs) from offline samples, e.g., the attractive or repulsive outcomes of each force. During interactions, the agents take actions based on the multi-dimensional gradients to maximize their own rewards. In practice, we integrate SocialGFs into the widely used multi-agent reinforcement learning algorithms, e.g., MAPPO. The empirical results reveal that SocialGFs offer four advantages for multi-agent systems: 1) they can be learned without requiring online interaction, 2) they demonstrate transferability across diverse tasks, 3) they facilitate credit assignment in challenging reward settings, and 4) they are scalable with the increasing number of agents.