 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025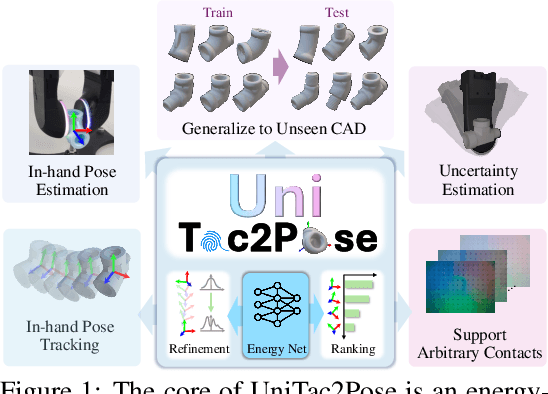
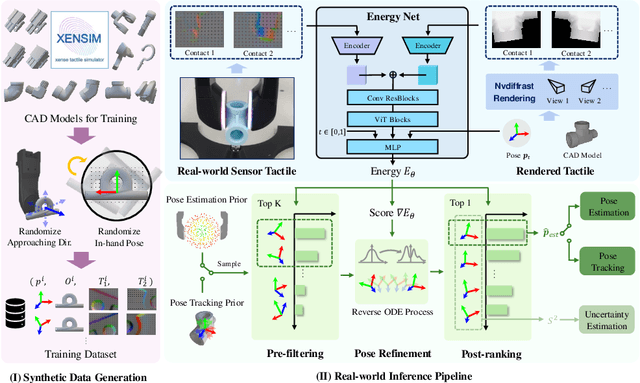

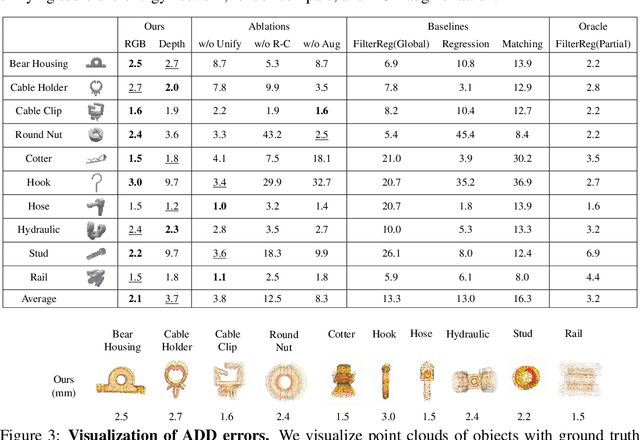
Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
Adaptive Visuo-Tactile Fusion with Predictive Force Attention for Dexterous Manipulation
May 20, 2025Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However, the heterogeneous nature of these modalities makes fusion challenging. Existing methods propose strategies to obtain comprehensively fused features but often ignore the fact that each modality requires different levels of attention at different manipulation stages. To address this, we propose a force-guided attention fusion module that adaptively adjusts the weights of visual and tactile features without human labeling. We also introduce a self-supervised future force prediction auxiliary task to reinforce the tactile modality, improve data imbalance, and encourage proper adjustment. Our method achieves an average success rate of 93% across three fine-grained, contactrich tasks in real-world experiments. Further analysis shows that our policy appropriately adjusts attention to each modality at different manipulation stages. The videos can be viewed at https://adaptac-dex.github.io/.
Boosting Universal LLM Reward Design through the Heuristic Reward Observation Space Evolution
Apr 10, 2025Large Language Models (LLMs) are emerging as promising tools for automated reinforcement learning (RL) reward design, owing to their robust capabilities in commonsense reasoning and code generation. By engaging in dialogues with RL agents, LLMs construct a Reward Observation Space (ROS) by selecting relevant environment states and defining their internal operations. However, existing frameworks have not effectively leveraged historical exploration data or manual task descriptions to iteratively evolve this space. In this paper, we propose a novel heuristic framework that enhances LLM-driven reward design by evolving the ROS through a table-based exploration caching mechanism and a text-code reconciliation strategy. Our framework introduces a state execution table, which tracks the historical usage and success rates of environment states, overcoming the Markovian constraint typically found in LLM dialogues and facilitating more effective exploration. Furthermore, we reconcile user-provided task descriptions with expert-defined success criteria using structured prompts, ensuring alignment in reward design objectives. Comprehensive evaluations on benchmark RL tasks demonstrate the effectiveness and stability of the proposed framework. Code and video demos are available at jingjjjjjie.github.io/LLM2Reward.
CordViP: Correspondence-based Visuomotor Policy for Dexterous Manipulation in Real-World
Feb 12, 2025Achieving human-level dexterity in robots is a key objective in the field of robotic manipulation. Recent advancements in 3D-based imitation learning have shown promising results, providing an effective pathway to achieve this goal. However, obtaining high-quality 3D representations presents two key problems: (1) the quality of point clouds captured by a single-view camera is significantly affected by factors such as camera resolution, positioning, and occlusions caused by the dexterous hand; (2) the global point clouds lack crucial contact information and spatial correspondences, which are necessary for fine-grained dexterous manipulation tasks. To eliminate these limitations, we propose CordViP, a novel framework that constructs and learns correspondences by leveraging the robust 6D pose estimation of objects and robot proprioception. Specifically, we first introduce the interaction-aware point clouds, which establish correspondences between the object and the hand. These point clouds are then used for our pre-training policy, where we also incorporate object-centric contact maps and hand-arm coordination information, effectively capturing both spatial and temporal dynamics. Our method demonstrates exceptional dexterous manipulation capabilities with an average success rate of 90\% in four real-world tasks, surpassing other baselines by a large margin. Experimental results also highlight the superior generalization and robustness of CordViP to different objects, viewpoints, and scenarios. Code and videos are available on https://aureleopku.github.io/CordViP.
MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-object Demand-driven Navigation
Oct 04, 2024The process of satisfying daily demands is a fundamental aspect of humans' daily lives. With the advancement of embodied AI, robots are increasingly capable of satisfying human demands. Demand-driven navigation (DDN) is a task in which an agent must locate an object to satisfy a specified demand instruction, such as ``I am thirsty.'' The previous study typically assumes that each demand instruction requires only one object to be fulfilled and does not consider individual preferences. However, the realistic human demand may involve multiple objects. In this paper, we introduce the Multi-object Demand-driven Navigation (MO-DDN) benchmark, which addresses these nuanced aspects, including multi-object search and personal preferences, thus making the MO-DDN task more reflective of real-life scenarios compared to DDN. Building upon previous work, we employ the concept of ``attribute'' to tackle this new task. However, instead of solely relying on attribute features in an end-to-end manner like DDN, we propose a modular method that involves constructing a coarse-to-fine attribute-based exploration agent (C2FAgent). Our experimental results illustrate that this coarse-to-fine exploration strategy capitalizes on the advantages of attributes at various decision-making levels, resulting in superior performance compared to baseline methods. Code and video can be found at https://sites.google.com/view/moddn.
Canonical Representation and Force-Based Pretraining of 3D Tactile for Dexterous Visuo-Tactile Policy Learning
Sep 26, 2024



Tactile sensing plays a vital role in enabling robots to perform fine-grained, contact-rich tasks. However, the high dimensionality of tactile data, due to the large coverage on dexterous hands, poses significant challenges for effective tactile feature learning, especially for 3D tactile data, as there are no large standardized datasets and no strong pretrained backbones. To address these challenges, we propose a novel canonical representation that reduces the difficulty of 3D tactile feature learning and further introduces a force-based self-supervised pretraining task to capture both local and net force features, which are crucial for dexterous manipulation. Our method achieves an average success rate of 78% across four fine-grained, contact-rich dexterous manipulation tasks in real-world experiments, demonstrating effectiveness and robustness compared to other methods. Further analysis shows that our method fully utilizes both spatial and force information from 3D tactile data to accomplish the tasks. The videos can be viewed at https://3dtacdex.github.io.
GFPack++: Improving 2D Irregular Packing by Learning Gradient Field with Attention
Jun 09, 20242D irregular packing is a classic combinatorial optimization problem with various applications, such as material utilization and texture atlas generation. This NP-hard problem requires efficient algorithms to optimize space utilization. Conventional numerical methods suffer from slow convergence and high computational cost. Existing learning-based methods, such as the score-based diffusion model, also have limitations, such as no rotation support, frequent collisions, and poor adaptability to arbitrary boundaries, and slow inferring. The difficulty of learning from teacher packing is to capture the complex geometric relationships among packing examples, which include the spatial (position, orientation) relationships of objects, their geometric features, and container boundary conditions. Representing these relationships in latent space is challenging. We propose GFPack++, an attention-based gradient field learning approach that addresses this challenge. It consists of two pivotal strategies: \emph{attention-based geometry encoding} for effective feature encoding and \emph{attention-based relation encoding} for learning complex relationships. We investigate the utilization distribution between the teacher and inference data and design a weighting function to prioritize tighter teacher data during training, enhancing learning effectiveness. Our diffusion model supports continuous rotation and outperforms existing methods on various datasets. We achieve higher space utilization over several widely used baselines, one-order faster than the previous diffusion-based method, and promising generalization for arbitrary boundaries. We plan to release our source code and datasets to support further research in this direction.
Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking
Jun 06, 2024
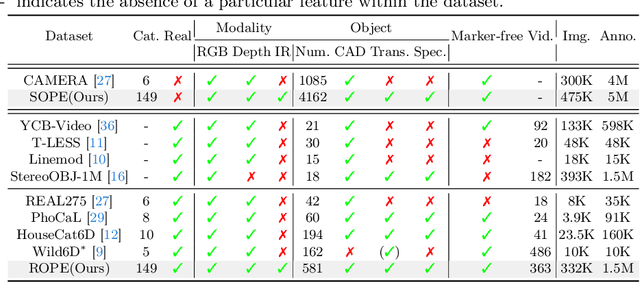

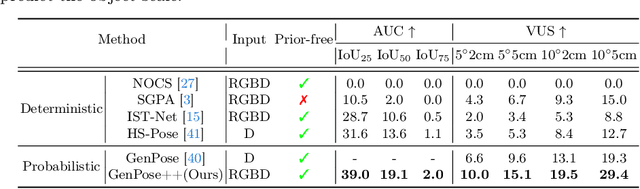
6D Object Pose Estimation is a crucial yet challenging task in computer vision, suffering from a significant lack of large-scale datasets. This scarcity impedes comprehensive evaluation of model performance, limiting research advancements. Furthermore, the restricted number of available instances or categories curtails its applications. To address these issues, this paper introduces Omni6DPose, a substantial dataset characterized by its diversity in object categories, large scale, and variety in object materials. Omni6DPose is divided into three main components: ROPE (Real 6D Object Pose Estimation Dataset), which includes 332K images annotated with over 1.5M annotations across 581 instances in 149 categories; SOPE(Simulated 6D Object Pose Estimation Dataset), consisting of 475K images created in a mixed reality setting with depth simulation, annotated with over 5M annotations across 4162 instances in the same 149 categories; and the manually aligned real scanned objects used in both ROPE and SOPE. Omni6DPose is inherently challenging due to the substantial variations and ambiguities. To address this challenge, we introduce GenPose++, an enhanced version of the SOTA category-level pose estimation framework, incorporating two pivotal improvements: Semantic-aware feature extraction and Clustering-based aggregation. Moreover, we provide a comprehensive benchmarking analysis to evaluate the performance of previous methods on this large-scale dataset in the realms of 6D object pose estimation and pose tracking.
SocialGFs: Learning Social Gradient Fields for Multi-Agent Reinforcement Learning
May 03, 2024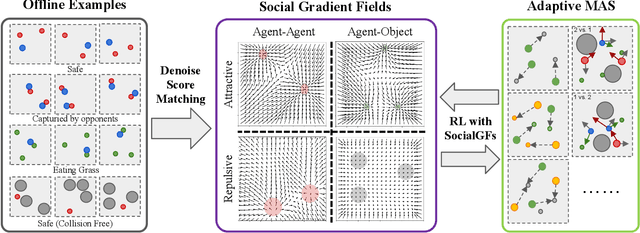
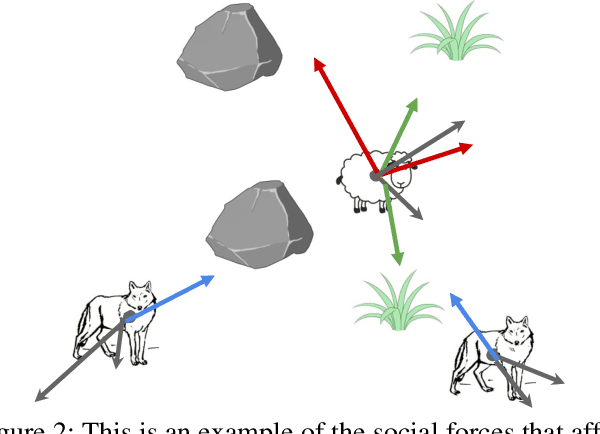

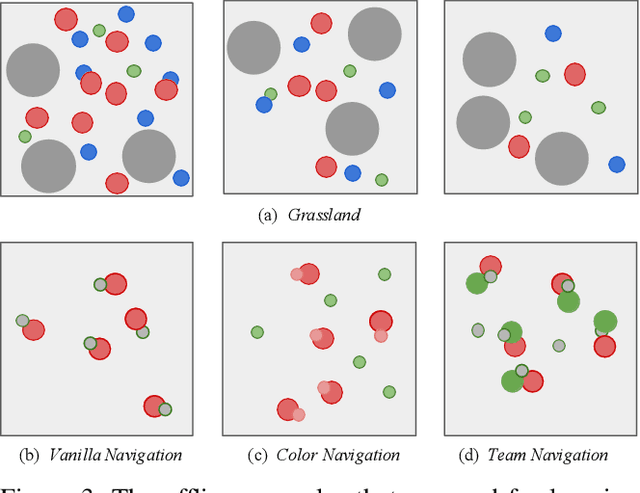
Multi-agent systems (MAS) need to adaptively cope with dynamic environments, changing agent populations, and diverse tasks. However, most of the multi-agent systems cannot easily handle them, due to the complexity of the state and task space. The social impact theory regards the complex influencing factors as forces acting on an agent, emanating from the environment, other agents, and the agent's intrinsic motivation, referring to the social force. Inspired by this concept, we propose a novel gradient-based state representation for multi-agent reinforcement learning. To non-trivially model the social forces, we further introduce a data-driven method, where we employ denoising score matching to learn the social gradient fields (SocialGFs) from offline samples, e.g., the attractive or repulsive outcomes of each force. During interactions, the agents take actions based on the multi-dimensional gradients to maximize their own rewards. In practice, we integrate SocialGFs into the widely used multi-agent reinforcement learning algorithms, e.g., MAPPO. The empirical results reveal that SocialGFs offer four advantages for multi-agent systems: 1) they can be learned without requiring online interaction, 2) they demonstrate transferability across diverse tasks, 3) they facilitate credit assignment in challenging reward settings, and 4) they are scalable with the increasing number of agents.
UniDexFPM: Universal Dexterous Functional Pre-grasp Manipulation Via Diffusion Policy
Mar 19, 2024
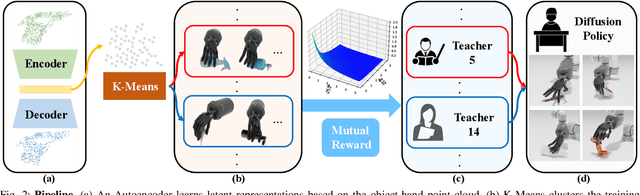

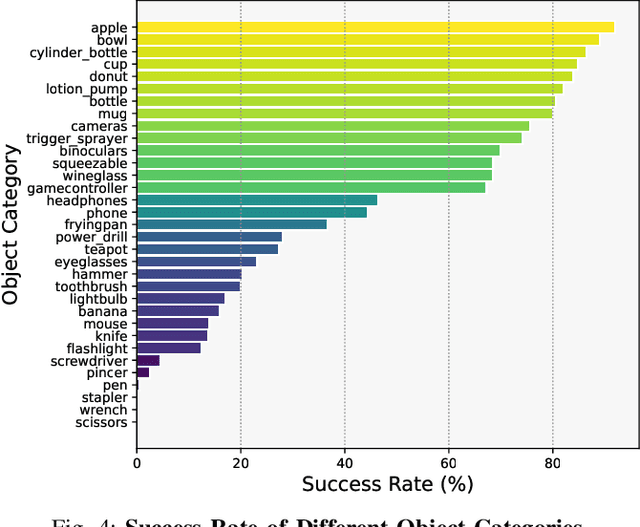
Objects in the real world are often not naturally positioned for functional grasping, which usually requires repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. However, effective learning of universal dexterous functional pre-grasp manipulation necessitates precise control over relative position, relative orientation, and contact between the hand and object, while generalizing to diverse dynamic scenarios with varying objects and goal poses. We address the challenge by using teacher-student learning. We propose a novel mutual reward that incentivizes agents to jointly optimize three key criteria. Furthermore, we introduce a pipeline that leverages a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across 30+ object categories encompassing 1400+ objects and 10k+ goal poses. Notably, our method relies solely on object pose information for universal dexterous functional pre-grasp manipulation by using extrinsic dexterity and adjusting from feedback. Additional experiments under noisy object pose observation showcase the robustness of our method and its potential for real-world applications. The demonstrations can be viewed at https://unidexfpm.github.io.