 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDexFPM: Universal Dexterous Functional Pre-grasp Manipulation Via Diffusion Policy
Mar 19, 2024
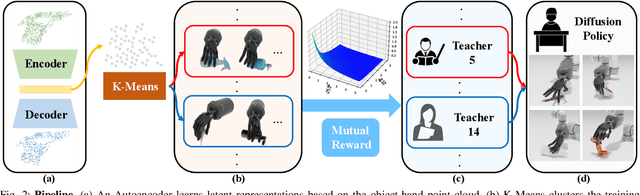

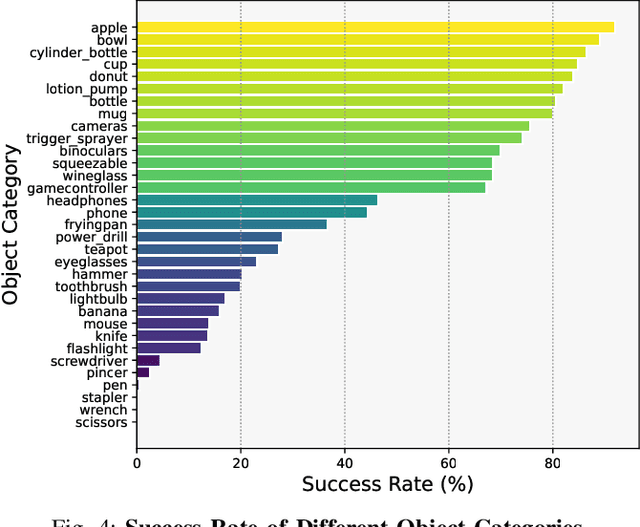
Objects in the real world are often not naturally positioned for functional grasping, which usually requires repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. However, effective learning of universal dexterous functional pre-grasp manipulation necessitates precise control over relative position, relative orientation, and contact between the hand and object, while generalizing to diverse dynamic scenarios with varying objects and goal poses. We address the challenge by using teacher-student learning. We propose a novel mutual reward that incentivizes agents to jointly optimize three key criteria. Furthermore, we introduce a pipeline that leverages a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across 30+ object categories encompassing 1400+ objects and 10k+ goal poses. Notably, our method relies solely on object pose information for universal dexterous functional pre-grasp manipulation by using extrinsic dexterity and adjusting from feedback. Additional experiments under noisy object pose observation showcase the robustness of our method and its potential for real-world applications. The demonstrations can be viewed at https://unidexfpm.github.io.
Learning Score-based Grasping Primitive for Human-assisting Dexterous Grasping
Sep 12, 2023The use of anthropomorphic robotic hands for assisting individuals in situations where human hands may be unavailable or unsuitable has gained significant importance. In this paper, we propose a novel task called human-assisting dexterous grasping that aims to train a policy for controlling a robotic hand's fingers to assist users in grasping objects. Unlike conventional dexterous grasping, this task presents a more complex challenge as the policy needs to adapt to diverse user intentions, in addition to the object's geometry. We address this challenge by proposing an approach consisting of two sub-modules: a hand-object-conditional grasping primitive called Grasping Gradient Field~(GraspGF), and a history-conditional residual policy. GraspGF learns `how' to grasp by estimating the gradient from a success grasping example set, while the residual policy determines `when' and at what speed the grasping action should be executed based on the trajectory history. Experimental results demonstrate the superiority of our proposed method compared to baselines, highlighting the user-awareness and practicality in real-world applications. The codes and demonstrations can be viewed at "https://sites.google.com/view/graspgf".