 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
Action-Sketcher: From Reasoning to Action via Visual Sketches for Long-Horizon Robotic Manipulation
Jan 04, 2026Long-horizon robotic manipulation is increasingly important for real-world deployment, requiring spatial disambiguation in complex layouts and temporal resilience under dynamic interaction. However, existing end-to-end and hierarchical Vision-Language-Action (VLA) policies often rely on text-only cues while keeping plan intent latent, which undermines referential grounding in cluttered or underspecified scenes, impedes effective task decomposition of long-horizon goals with close-loop interaction, and limits causal explanation by obscuring the rationale behind action choices. To address these issues, we first introduce Visual Sketch, an implausible visual intermediate that renders points, boxes, arrows, and typed relations in the robot's current views to externalize spatial intent, connect language to scene geometry. Building on Visual Sketch, we present Action-Sketcher, a VLA framework that operates in a cyclic See-Think-Sketch-Act workflow coordinated by adaptive token-gated strategy for reasoning triggers, sketch revision, and action issuance, thereby supporting reactive corrections and human interaction while preserving real-time action prediction. To enable scalable training and evaluation, we curate diverse corpus with interleaved images, text, Visual Sketch supervision, and action sequences, and train Action-Sketcher with a multi-stage curriculum recipe that combines interleaved sequence alignment for modality unification, language-to-sketch consistency for precise linguistic grounding, and imitation learning augmented with sketch-to-action reinforcement for robustness. Extensive experiments on cluttered scenes and multi-object tasks, in simulation and on real-world tasks, show improved long-horizon success, stronger robustness to dynamic scene changes, and enhanced interpretability via editable sketches and step-wise plans. Project website: https://action-sketcher.github.io
RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
Oct 08, 2025
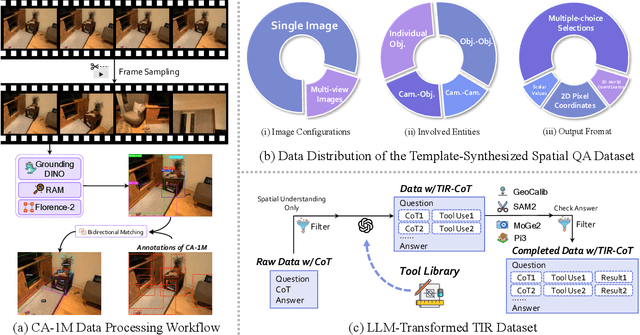
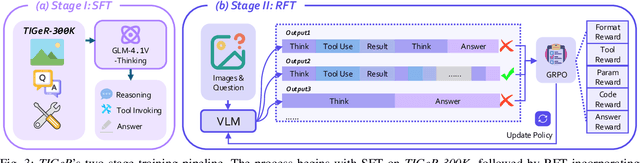
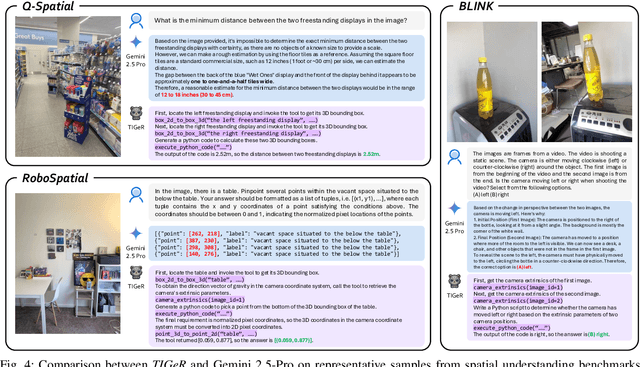
Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, trajectory generation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
Jun 04, 2025Spatial referring is a fundamental capability of embodied robots to interact with the 3D physical world. However, even with the powerful pretrained vision language models (VLMs), recent approaches are still not qualified to accurately understand the complex 3D scenes and dynamically reason about the instruction-indicated locations for interaction. To this end, we propose RoboRefer, a 3D-aware VLM that can first achieve precise spatial understanding by integrating a disentangled but dedicated depth encoder via supervised fine-tuning (SFT). Moreover, RoboRefer advances generalized multi-step spatial reasoning via reinforcement fine-tuning (RFT), with metric-sensitive process reward functions tailored for spatial referring tasks. To support SFT and RFT training, we introduce RefSpatial, a large-scale dataset of 20M QA pairs (2x prior), covering 31 spatial relations (vs. 15 prior) and supporting complex reasoning processes (up to 5 steps). In addition, we introduce RefSpatial-Bench, a challenging benchmark filling the gap in evaluating spatial referring with multi-step reasoning. Experiments show that SFT-trained RoboRefer achieves state-of-the-art spatial understanding, with an average success rate of 89.6%. RFT-trained RoboRefer further outperforms all other baselines by a large margin, even surpassing Gemini-2.5-Pro by 17.4% in average accuracy on RefSpatial-Bench. Notably, RoboRefer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (e,g., UR5, G1 humanoid) in cluttered real-world scenes.
CordViP: Correspondence-based Visuomotor Policy for Dexterous Manipulation in Real-World
Feb 12, 2025Achieving human-level dexterity in robots is a key objective in the field of robotic manipulation. Recent advancements in 3D-based imitation learning have shown promising results, providing an effective pathway to achieve this goal. However, obtaining high-quality 3D representations presents two key problems: (1) the quality of point clouds captured by a single-view camera is significantly affected by factors such as camera resolution, positioning, and occlusions caused by the dexterous hand; (2) the global point clouds lack crucial contact information and spatial correspondences, which are necessary for fine-grained dexterous manipulation tasks. To eliminate these limitations, we propose CordViP, a novel framework that constructs and learns correspondences by leveraging the robust 6D pose estimation of objects and robot proprioception. Specifically, we first introduce the interaction-aware point clouds, which establish correspondences between the object and the hand. These point clouds are then used for our pre-training policy, where we also incorporate object-centric contact maps and hand-arm coordination information, effectively capturing both spatial and temporal dynamics. Our method demonstrates exceptional dexterous manipulation capabilities with an average success rate of 90\% in four real-world tasks, surpassing other baselines by a large margin. Experimental results also highlight the superior generalization and robustness of CordViP to different objects, viewpoints, and scenarios. Code and videos are available on https://aureleopku.github.io/CordViP.