 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
RoboOS-NeXT: A Unified Memory-based Framework for Lifelong, Scalable, and Robust Multi-Robot Collaboration
Oct 30, 2025The proliferation of collaborative robots across diverse tasks and embodiments presents a central challenge: achieving lifelong adaptability, scalable coordination, and robust scheduling in multi-agent systems. Existing approaches, from vision-language-action (VLA) models to hierarchical frameworks, fall short due to their reliance on limited or dividual-agent memory. This fundamentally constrains their ability to learn over long horizons, scale to heterogeneous teams, or recover from failures, highlighting the need for a unified memory representation. To address these limitations, we introduce RoboOS-NeXT, a unified memory-based framework for lifelong, scalable, and robust multi-robot collaboration. At the core of RoboOS-NeXT is the novel Spatio-Temporal-Embodiment Memory (STEM), which integrates spatial scene geometry, temporal event history, and embodiment profiles into a shared representation. This memory-centric design is integrated into a brain-cerebellum framework, where a high-level brain model performs global planning by retrieving and updating STEM, while low-level controllers execute actions locally. This closed loop between cognition, memory, and execution enables dynamic task allocation, fault-tolerant collaboration, and consistent state synchronization. We conduct extensive experiments spanning complex coordination tasks in restaurants, supermarkets, and households. Our results demonstrate that RoboOS-NeXT achieves superior performance across heterogeneous embodiments, validating its effectiveness in enabling lifelong, scalable, and robust multi-robot collaboration. Project website: https://flagopen.github.io/RoboOS/
TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
Oct 08, 2025
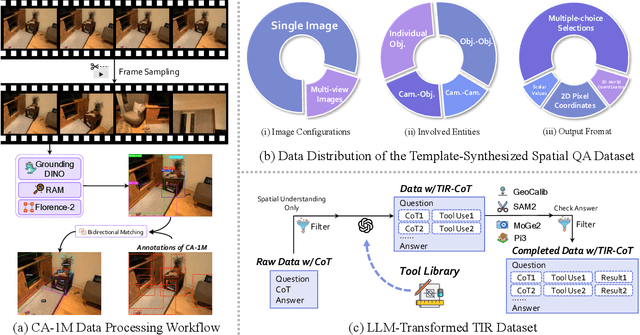
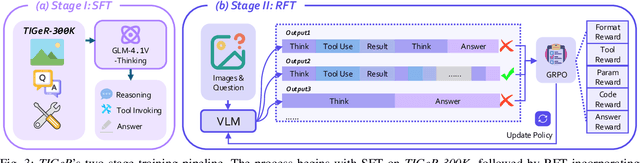
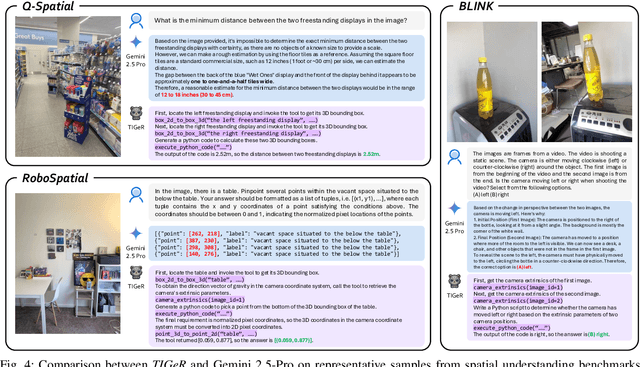
Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, trajectory generation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Oct 01, 2025We introduce \textsc{MathSticks}, a benchmark for Visual Symbolic Compositional Reasoning (VSCR), which unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation that must be corrected by moving one or two sticks under strict conservation rules. The benchmark includes both text-guided and purely visual settings, systematically covering digit scale, move complexity, solution multiplicity, and operator variation, with 1.4M generated instances and a curated test set. Evaluations of 14 vision--language models reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the visual regime, while humans exceed 90\% accuracy. These findings establish \textsc{MathSticks} as a rigorous testbed for advancing compositional reasoning across vision and symbols. Our code and dataset are publicly available at https://github.com/Yuheng2000/MathSticks.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
Jun 04, 2025Spatial referring is a fundamental capability of embodied robots to interact with the 3D physical world. However, even with the powerful pretrained vision language models (VLMs), recent approaches are still not qualified to accurately understand the complex 3D scenes and dynamically reason about the instruction-indicated locations for interaction. To this end, we propose RoboRefer, a 3D-aware VLM that can first achieve precise spatial understanding by integrating a disentangled but dedicated depth encoder via supervised fine-tuning (SFT). Moreover, RoboRefer advances generalized multi-step spatial reasoning via reinforcement fine-tuning (RFT), with metric-sensitive process reward functions tailored for spatial referring tasks. To support SFT and RFT training, we introduce RefSpatial, a large-scale dataset of 20M QA pairs (2x prior), covering 31 spatial relations (vs. 15 prior) and supporting complex reasoning processes (up to 5 steps). In addition, we introduce RefSpatial-Bench, a challenging benchmark filling the gap in evaluating spatial referring with multi-step reasoning. Experiments show that SFT-trained RoboRefer achieves state-of-the-art spatial understanding, with an average success rate of 89.6%. RFT-trained RoboRefer further outperforms all other baselines by a large margin, even surpassing Gemini-2.5-Pro by 17.4% in average accuracy on RefSpatial-Bench. Notably, RoboRefer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (e,g., UR5, G1 humanoid) in cluttered real-world scenes.
Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
Dec 05, 2024



Automatic detection and prevention of open-set failures are crucial in closed-loop robotic systems. Recent studies often struggle to simultaneously identify unexpected failures reactively after they occur and prevent foreseeable ones proactively. To this end, we propose Code-as-Monitor (CaM), a novel paradigm leveraging the vision-language model (VLM) for both open-set reactive and proactive failure detection. The core of our method is to formulate both tasks as a unified set of spatio-temporal constraint satisfaction problems and use VLM-generated code to evaluate them for real-time monitoring. To enhance the accuracy and efficiency of monitoring, we further introduce constraint elements that abstract constraint-related entities or their parts into compact geometric elements. This approach offers greater generality, simplifies tracking, and facilitates constraint-aware visual programming by leveraging these elements as visual prompts. Experiments show that CaM achieves a 28.7% higher success rate and reduces execution time by 31.8% under severe disturbances compared to baselines across three simulators and a real-world setting. Moreover, CaM can be integrated with open-loop control policies to form closed-loop systems, enabling long-horizon tasks in cluttered scenes with dynamic environments.
WorldSimBench: Towards Video Generation Models as World Simulators
Oct 23, 2024



Recent advancements in predictive models have demonstrated exceptional capabilities in predicting the future state of objects and scenes. However, the lack of categorization based on inherent characteristics continues to hinder the progress of predictive model development. Additionally, existing benchmarks are unable to effectively evaluate higher-capability, highly embodied predictive models from an embodied perspective. In this work, we classify the functionalities of predictive models into a hierarchy and take the first step in evaluating World Simulators by proposing a dual evaluation framework called WorldSimBench. WorldSimBench includes Explicit Perceptual Evaluation and Implicit Manipulative Evaluation, encompassing human preference assessments from the visual perspective and action-level evaluations in embodied tasks, covering three representative embodied scenarios: Open-Ended Embodied Environment, Autonomous, Driving, and Robot Manipulation. In the Explicit Perceptual Evaluation, we introduce the HF-Embodied Dataset, a video assessment dataset based on fine-grained human feedback, which we use to train a Human Preference Evaluator that aligns with human perception and explicitly assesses the visual fidelity of World Simulators. In the Implicit Manipulative Evaluation, we assess the video-action consistency of World Simulators by evaluating whether the generated situation-aware video can be accurately translated into the correct control signals in dynamic environments. Our comprehensive evaluation offers key insights that can drive further innovation in video generation models, positioning World Simulators as a pivotal advancement toward embodied artificial intelligence.
MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control
Mar 19, 2024



It is a long-lasting goal to design a generalist-embodied agent that can follow diverse instructions in human-like ways. However, existing approaches often fail to steadily follow instructions due to difficulties in understanding abstract and sequential natural language instructions. To this end, we introduce MineDreamer, an open-ended embodied agent built upon the challenging Minecraft simulator with an innovative paradigm that enhances instruction-following ability in low-level control signal generation. Specifically, MineDreamer is developed on top of recent advances in Multimodal Large Language Models (MLLMs) and diffusion models, and we employ a Chain-of-Imagination (CoI) mechanism to envision the step-by-step process of executing instructions and translating imaginations into more precise visual prompts tailored to the current state; subsequently, the agent generates keyboard-and-mouse actions to efficiently achieve these imaginations, steadily following the instructions at each step. Extensive experiments demonstrate that MineDreamer follows single and multi-step instructions steadily, significantly outperforming the best generalist agent baseline and nearly doubling its performance. Moreover, qualitative analysis of the agent's imaginative ability reveals its generalization and comprehension of the open world.