 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
Oct 08, 2025
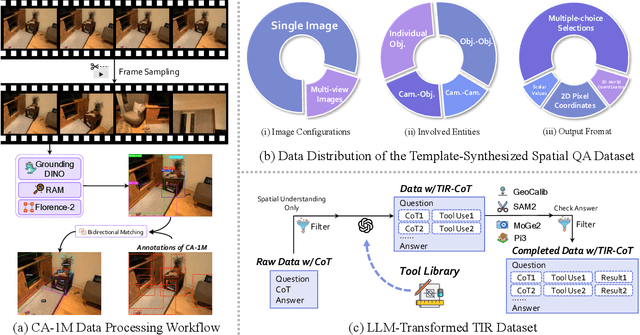
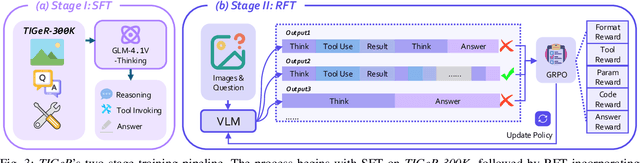
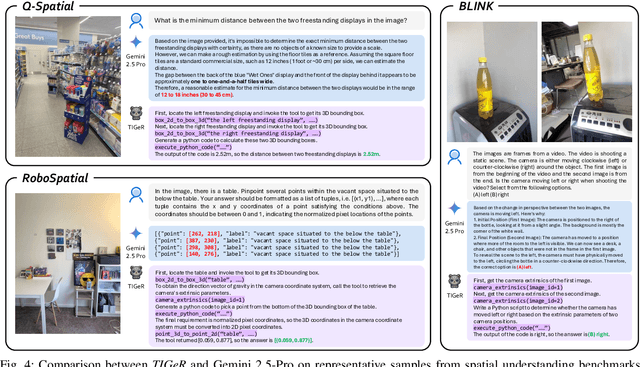
Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, trajectory generation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.
RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
Jun 04, 2025Spatial referring is a fundamental capability of embodied robots to interact with the 3D physical world. However, even with the powerful pretrained vision language models (VLMs), recent approaches are still not qualified to accurately understand the complex 3D scenes and dynamically reason about the instruction-indicated locations for interaction. To this end, we propose RoboRefer, a 3D-aware VLM that can first achieve precise spatial understanding by integrating a disentangled but dedicated depth encoder via supervised fine-tuning (SFT). Moreover, RoboRefer advances generalized multi-step spatial reasoning via reinforcement fine-tuning (RFT), with metric-sensitive process reward functions tailored for spatial referring tasks. To support SFT and RFT training, we introduce RefSpatial, a large-scale dataset of 20M QA pairs (2x prior), covering 31 spatial relations (vs. 15 prior) and supporting complex reasoning processes (up to 5 steps). In addition, we introduce RefSpatial-Bench, a challenging benchmark filling the gap in evaluating spatial referring with multi-step reasoning. Experiments show that SFT-trained RoboRefer achieves state-of-the-art spatial understanding, with an average success rate of 89.6%. RFT-trained RoboRefer further outperforms all other baselines by a large margin, even surpassing Gemini-2.5-Pro by 17.4% in average accuracy on RefSpatial-Bench. Notably, RoboRefer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (e,g., UR5, G1 humanoid) in cluttered real-world scenes.
Cross-Modality Jailbreak and Mismatched Attacks on Medical Multimodal Large Language Models
May 26, 2024



Security concerns related to Large Language Models (LLMs) have been extensively explored, yet the safety implications for Multimodal Large Language Models (MLLMs), particularly in medical contexts (MedMLLMs), remain insufficiently studied. This paper delves into the underexplored security vulnerabilities of MedMLLMs, especially when deployed in clinical environments where the accuracy and relevance of question-and-answer interactions are critically tested against complex medical challenges. By combining existing clinical medical data with atypical natural phenomena, we redefine two types of attacks: mismatched malicious attack (2M-attack) and optimized mismatched malicious attack (O2M-attack). Using our own constructed voluminous 3MAD dataset, which covers a wide range of medical image modalities and harmful medical scenarios, we conduct a comprehensive analysis and propose the MCM optimization method, which significantly enhances the attack success rate on MedMLLMs. Evaluations with this dataset and novel attack methods, including white-box attacks on LLaVA-Med and transfer attacks on four other state-of-the-art models, indicate that even MedMLLMs designed with enhanced security features are vulnerable to security breaches. Our work underscores the urgent need for a concerted effort to implement robust security measures and enhance the safety and efficacy of open-source MedMLLMs, particularly given the potential severity of jailbreak attacks and other malicious or clinically significant exploits in medical settings. For further research and replication, anonymous access to our code is available at https://github.com/dirtycomputer/O2M_attack. Warning: Medical large model jailbreaking may generate content that includes unverified diagnoses and treatment recommendations. Always consult professional medical advice.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024
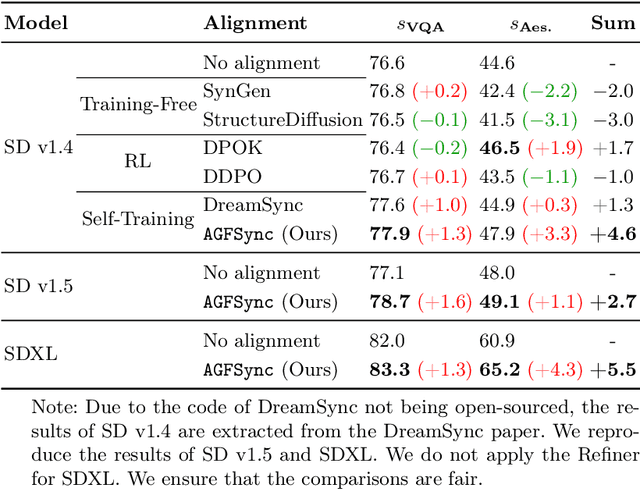
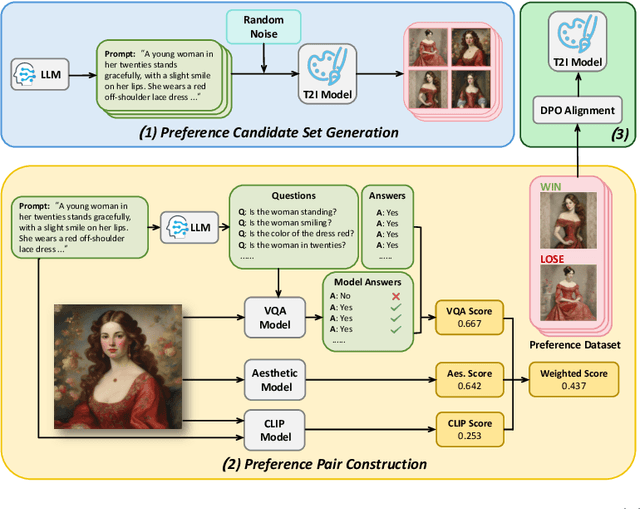
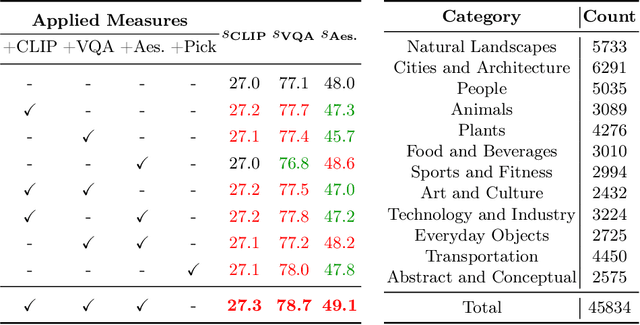
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
Prompting Large Language Models for Zero-Shot Clinical Prediction with Structured Longitudinal Electronic Health Record Data
Jan 25, 2024The inherent complexity of structured longitudinal Electronic Health Records (EHR) data poses a significant challenge when integrated with Large Language Models (LLMs), which are traditionally tailored for natural language processing. Motivated by the urgent need for swift decision-making during new disease outbreaks, where traditional predictive models often fail due to a lack of historical data, this research investigates the adaptability of LLMs, like GPT-4, to EHR data. We particularly focus on their zero-shot capabilities, which enable them to make predictions in scenarios in which they haven't been explicitly trained. In response to the longitudinal, sparse, and knowledge-infused nature of EHR data, our prompting approach involves taking into account specific EHR characteristics such as units and reference ranges, and employing an in-context learning strategy that aligns with clinical contexts. Our comprehensive experiments on the MIMIC-IV and TJH datasets demonstrate that with our elaborately designed prompting framework, LLMs can improve prediction performance in key tasks such as mortality, length-of-stay, and 30-day readmission by about 35\%, surpassing ML models in few-shot settings. Our research underscores the potential of LLMs in enhancing clinical decision-making, especially in urgent healthcare situations like the outbreak of emerging diseases with no labeled data. The code is publicly available at https://github.com/yhzhu99/llm4healthcare for reproducibility.
Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
Sep 17, 2023
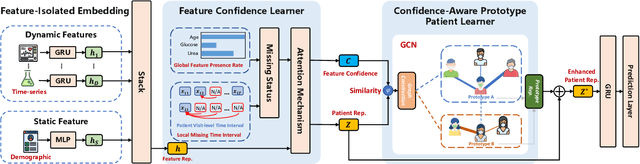
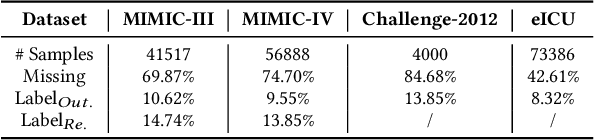
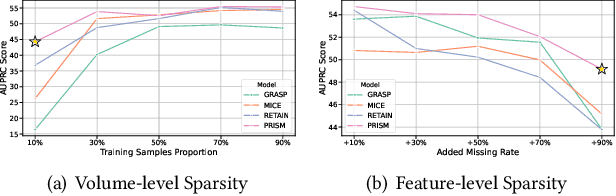
Electronic Health Record (EHR) data frequently exhibits sparse characteristics, posing challenges for predictive modeling. Current direct imputation such as matrix imputation approaches hinge on referencing analogous rows or columns to complete raw missing data and do not differentiate between imputed and actual values. As a result, models may inadvertently incorporate irrelevant or deceptive information with respect to the prediction objective, thereby compromising the efficacy of downstream performance. While some methods strive to recalibrate or augment EHR embeddings after direct imputation, they often mistakenly prioritize imputed features. This misprioritization can introduce biases or inaccuracies into the model. To tackle these issues, our work resorts to indirect imputation, where we leverage prototype representations from similar patients to obtain a denser embedding. Recognizing the limitation that missing features are typically treated the same as present ones when measuring similar patients, our approach designs a feature confidence learner module. This module is sensitive to the missing feature status, enabling the model to better judge the reliability of each feature. Moreover, we propose a novel patient similarity metric that takes feature confidence into account, ensuring that evaluations are not based merely on potentially inaccurate imputed values. Consequently, our work captures dense prototype patient representations with feature-missing-aware calibration process. Comprehensive experiments demonstrate that designed model surpasses established EHR-focused models with a statistically significant improvement on MIMIC-III and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code is publicly available at \url{https://github.com/yhzhu99/SparseEHR} to assure the reproducibility.
M$^3$Fair: Mitigating Bias in Healthcare Data through Multi-Level and Multi-Sensitive-Attribute Reweighting Method
Jun 07, 2023
In the data-driven artificial intelligence paradigm, models heavily rely on large amounts of training data. However, factors like sampling distribution imbalance can lead to issues of bias and unfairness in healthcare data. Sensitive attributes, such as race, gender, age, and medical condition, are characteristics of individuals that are commonly associated with discrimination or bias. In healthcare AI, these attributes can play a significant role in determining the quality of care that individuals receive. For example, minority groups often receive fewer procedures and poorer-quality medical care than white individuals in US. Therefore, detecting and mitigating bias in data is crucial to enhancing health equity. Bias mitigation methods include pre-processing, in-processing, and post-processing. Among them, Reweighting (RW) is a widely used pre-processing method that performs well in balancing machine learning performance and fairness performance. RW adjusts the weights for samples within each (group, label) combination, where these weights are utilized in loss functions. However, RW is limited to considering only a single sensitive attribute when mitigating bias and assumes that each sensitive attribute is equally important. This may result in potential inaccuracies when addressing intersectional bias. To address these limitations, we propose M3Fair, a multi-level and multi-sensitive-attribute reweighting method by extending the RW method to multiple sensitive attributes at multiple levels. Our experiments on real-world datasets show that the approach is effective, straightforward, and generalizable in addressing the healthcare fairness issues.