 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaDQ: Ultra-High Delta Compression for Fine-Tuned LLMs via Group-wise Dropout and Separate Quantization
Oct 11, 2024



Large language models achieve exceptional performance on various downstream tasks through supervised fine-tuning. However, the diversity of downstream tasks and practical requirements makes deploying multiple full-parameter fine-tuned models challenging. Current methods that compress the delta weight struggle to achieve ultra-high compression, failing to minimize the deployment overhead. To address the above issue, we propose a novel distribution-driven delta compression framework DeltaDQ, which utilizes Group-wise Dropout and Separate Quantization to achieve ultra-high compression for the delta weight. We have observed that the matrix-computed intermediate results for the delta weight exhibit extremely small variance and min-max range characteristics, referred to as Balanced Intermediate Results. Exploiting this phenomenon, we introduce Group-wise Dropout to perform dropout on the delta weight using an optimal group size. Furthermore, using Separate Quantization, sparse weights are quantized and decomposed to achieve a lower bit. Experimental results show that DeltaDQ achieves 16x compression with improved accuracy compared to baselines for WizardMath and WizardCoder models across different parameter scales. Moreover, DeltaDQ demonstrates the ability for ultra-high compression ratio, achieving 128x compression for the WizardMath-7B model and 512x compression for the WizardMath-70B model.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 24, 2024
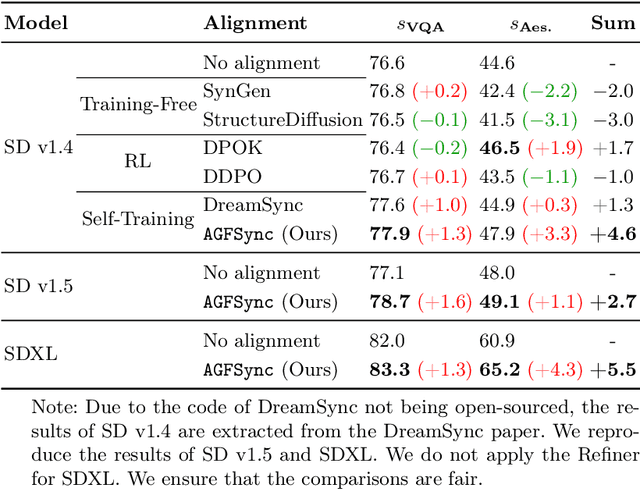
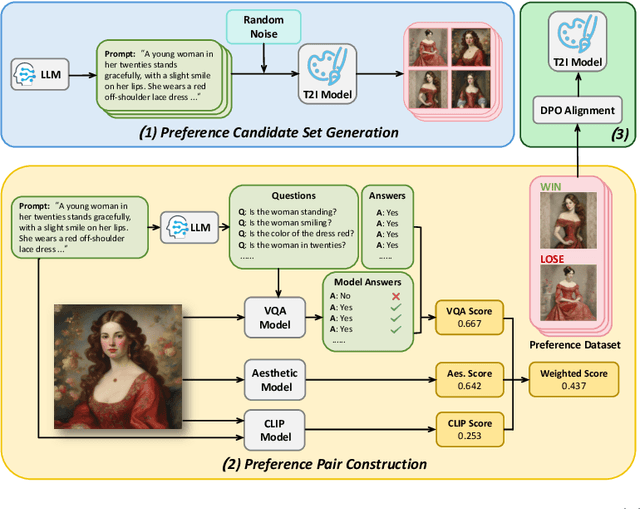
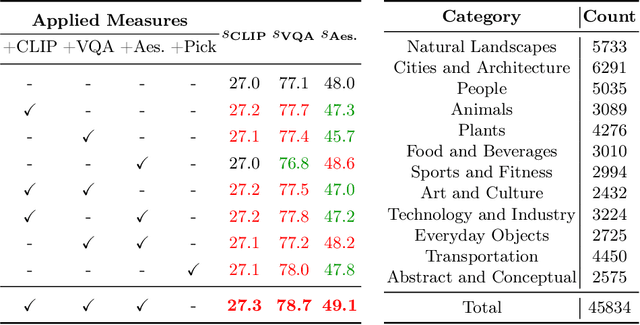
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
Jun 28, 2023



Large Language Models (LLMs) have shown the potential to revolutionize natural language processing tasks in various domains, sparking great interest in vertical-specific large models. However, unlike proprietary models such as BloombergGPT and FinGPT, which have leveraged their unique data accumulations to make strides in the finance domain, there hasn't not many similar large language models in the Chinese legal domain to facilitate its digital transformation. In this paper, we propose an open-source legal large language model named ChatLaw. Due to the importance of data quality, we carefully designed a legal domain fine-tuning dataset. Additionally, to overcome the problem of model hallucinations in legal data screening during reference data retrieval, we introduce a method that combines vector database retrieval with keyword retrieval to effectively reduce the inaccuracy of relying solely on vector database retrieval. Furthermore, we propose a self-attention method to enhance the ability of large models to overcome errors present in reference data, further optimizing the issue of model hallucinations at the model level and improving the problem-solving capabilities of large models. We also open-sourced our model and part of the data at https://github.com/PKU-YuanGroup/ChatLaw.