 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
Paper and Code

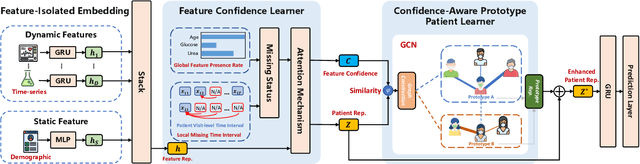
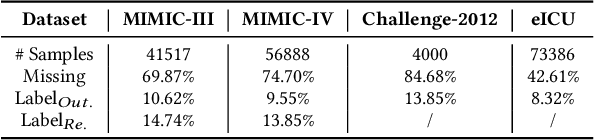
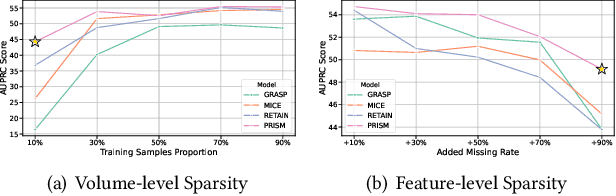
Electronic Health Record (EHR) data frequently exhibits sparse characteristics, posing challenges for predictive modeling. Current direct imputation such as matrix imputation approaches hinge on referencing analogous rows or columns to complete raw missing data and do not differentiate between imputed and actual values. As a result, models may inadvertently incorporate irrelevant or deceptive information with respect to the prediction objective, thereby compromising the efficacy of downstream performance. While some methods strive to recalibrate or augment EHR embeddings after direct imputation, they often mistakenly prioritize imputed features. This misprioritization can introduce biases or inaccuracies into the model. To tackle these issues, our work resorts to indirect imputation, where we leverage prototype representations from similar patients to obtain a denser embedding. Recognizing the limitation that missing features are typically treated the same as present ones when measuring similar patients, our approach designs a feature confidence learner module. This module is sensitive to the missing feature status, enabling the model to better judge the reliability of each feature. Moreover, we propose a novel patient similarity metric that takes feature confidence into account, ensuring that evaluations are not based merely on potentially inaccurate imputed values. Consequently, our work captures dense prototype patient representations with feature-missing-aware calibration process. Comprehensive experiments demonstrate that designed model surpasses established EHR-focused models with a statistically significant improvement on MIMIC-III and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code is publicly available at \url{https://github.com/yhzhu99/SparseEHR} to assure the reproducibility.