 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
May 14, 2026Autonomous driving has progressed from modular pipelines toward end-to-end unification, and Vision-Language-Action (VLA) models are a natural extension of this journey beyond Vision-to-Action (VA). In practice, driving VLAs have often trailed VA on planning quality, suggesting that the difficulty is not simply model scale but the interface through which semantic reasoning, temporal context, and continuous control are combined. We argue that this gap reflects how VLA has been built -- as isolated subtask improvements that fail to compose coherent driving capabilities -- rather than what VLA is. We present MindVLA-U1, the first unified streaming VLA architecture for autonomous driving. A unified VLM backbone produces AR language tokens (optional) and flow-matching continuous action trajectories in a single forward pass over one shared representation, preserving the natural output form of each modality. A full streaming design processes the driving video framewise rather than as fixed video-action chunks under costly temporal VLM modeling. Planned trajectories evolve smoothly across frames while a learned streaming memory channel carries temporal context and updates. The unified architecture enables fast/slow systems on dense & sparse MoT backbones via flexible self-attention context management, and exposes a measurable language-control path for action: language-predicted driving intents steers the action diffusion via classifier-free guidance (CFG), turning language-side intent into control signals for continuous action planning. On the long-tail WOD-E2E benchmark, MindVLA-U1 surpasses experienced human drivers for the first time (8.20 RFS vs. 8.13 GT RFS) with 2 diffusion steps, achieves state-of-the-art planning ADEs over prior VA/VLA by large margins, and matches VA latency (16 FPS vs. RAP's 18 FPS at 1B scale) while preserving natural language interfaces for human-vehicle interaction.
ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning
Jan 08, 2025



Text-to-video generation has made remarkable advancements through diffusion models. However, Multi-Concept Video Customization (MCVC) remains a significant challenge. We identify two key challenges in this task: 1) the identity decoupling problem, where directly adopting existing customization methods inevitably mix attributes when handling multiple concepts simultaneously, and 2) the scarcity of high-quality video-entity pairs, which is crucial for training such a model that represents and decouples various concepts well. To address these challenges, we introduce ConceptMaster, an innovative framework that effectively tackles the critical issues of identity decoupling while maintaining concept fidelity in customized videos. Specifically, we introduce a novel strategy of learning decoupled multi-concept embeddings that are injected into the diffusion models in a standalone manner, which effectively guarantees the quality of customized videos with multiple identities, even for highly similar visual concepts. To further overcome the scarcity of high-quality MCVC data, we carefully establish a data construction pipeline, which enables systematic collection of precise multi-concept video-entity data across diverse concepts. A comprehensive benchmark is designed to validate the effectiveness of our model from three critical dimensions: concept fidelity, identity decoupling ability, and video generation quality across six different concept composition scenarios. Extensive experiments demonstrate that our ConceptMaster significantly outperforms previous approaches for this task, paving the way for generating personalized and semantically accurate videos across multiple concepts.
Advancing Medical Radiograph Representation Learning: A Hybrid Pre-training Paradigm with Multilevel Semantic Granularity
Oct 01, 2024

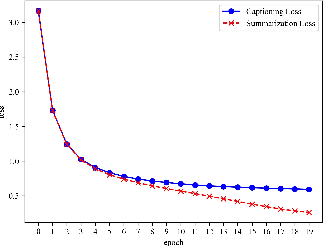

This paper introduces an innovative approach to Medical Vision-Language Pre-training (Med-VLP) area in the specialized context of radiograph representation learning. While conventional methods frequently merge textual annotations into unified reports, we acknowledge the intrinsic hierarchical relationship between the findings and impression section in radiograph datasets. To establish a targeted correspondence between images and texts, we propose a novel HybridMED framework to align global-level visual representations with impression and token-level visual representations with findings. Moreover, our framework incorporates a generation decoder that employs two proxy tasks, responsible for generating the impression from (1) images, via a captioning branch, and (2) findings, through a summarization branch. Additionally, knowledge distillation is leveraged to facilitate the training process. Experiments on the MIMIC-CXR dataset reveal that our summarization branch effectively distills knowledge to the captioning branch, enhancing model performance without significantly increasing parameter requirements due to the shared self-attention and feed-forward architecture.
* 18 pages
Story3D-Agent: Exploring 3D Storytelling Visualization with Large Language Models
Aug 21, 2024



Traditional visual storytelling is complex, requiring specialized knowledge and substantial resources, yet often constrained by human creativity and creation precision. While Large Language Models (LLMs) enhance visual storytelling, current approaches often limit themselves to 2D visuals or oversimplify stories through motion synthesis and behavioral simulation, failing to create comprehensive, multi-dimensional narratives. To this end, we present Story3D-Agent, a pioneering approach that leverages the capabilities of LLMs to transform provided narratives into 3D-rendered visualizations. By integrating procedural modeling, our approach enables precise control over multi-character actions and motions, as well as diverse decorative elements, ensuring the long-range and dynamic 3D representation. Furthermore, our method supports narrative extension through logical reasoning, ensuring that generated content remains consistent with existing conditions. We have thoroughly evaluated our Story3D-Agent to validate its effectiveness, offering a basic framework to advance 3D story representation.
MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control
Mar 19, 2024



It is a long-lasting goal to design a generalist-embodied agent that can follow diverse instructions in human-like ways. However, existing approaches often fail to steadily follow instructions due to difficulties in understanding abstract and sequential natural language instructions. To this end, we introduce MineDreamer, an open-ended embodied agent built upon the challenging Minecraft simulator with an innovative paradigm that enhances instruction-following ability in low-level control signal generation. Specifically, MineDreamer is developed on top of recent advances in Multimodal Large Language Models (MLLMs) and diffusion models, and we employ a Chain-of-Imagination (CoI) mechanism to envision the step-by-step process of executing instructions and translating imaginations into more precise visual prompts tailored to the current state; subsequently, the agent generates keyboard-and-mouse actions to efficiently achieve these imaginations, steadily following the instructions at each step. Extensive experiments demonstrate that MineDreamer follows single and multi-step instructions steadily, significantly outperforming the best generalist agent baseline and nearly doubling its performance. Moreover, qualitative analysis of the agent's imaginative ability reveals its generalization and comprehension of the open world.
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Dec 11, 2023



Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.