 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Adversarial Purification with DDIM Metric Loss for Stable Diffusion
Jan 12, 2026Stable Diffusion (SD) often produces degraded outputs when the training dataset contains adversarial noise. Adversarial purification offers a promising solution by removing adversarial noise from contaminated data. However, existing purification methods are primarily designed for classification tasks and fail to address SD-specific adversarial strategies, such as attacks targeting the VAE encoder, UNet denoiser, or both. To address the gap in SD security, we propose Universal Diffusion Adversarial Purification (UDAP), a novel framework tailored for defending adversarial attacks targeting SD models. UDAP leverages the distinct reconstruction behaviors of clean and adversarial images during Denoising Diffusion Implicit Models (DDIM) inversion to optimize the purification process. By minimizing the DDIM metric loss, UDAP can effectively remove adversarial noise. Additionally, we introduce a dynamic epoch adjustment strategy that adapts optimization iterations based on reconstruction errors, significantly improving efficiency without sacrificing purification quality. Experiments demonstrate UDAP's robustness against diverse adversarial methods, including PID (VAE-targeted), Anti-DreamBooth (UNet-targeted), MIST (hybrid), and robustness-enhanced variants like Anti-Diffusion (Anti-DF) and MetaCloak. UDAP also generalizes well across SD versions and text prompts, showcasing its practical applicability in real-world scenarios.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.
Lumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control
Mar 07, 2025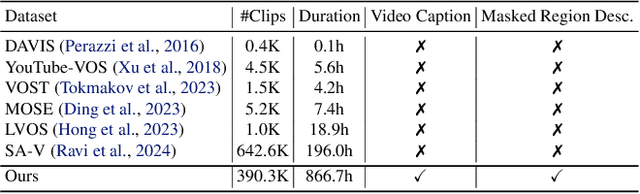
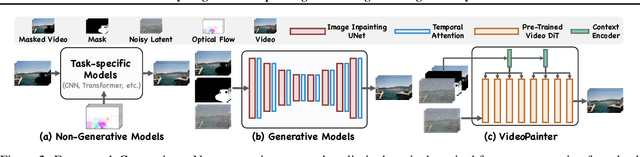
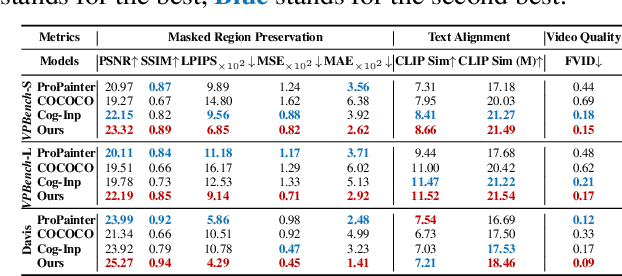
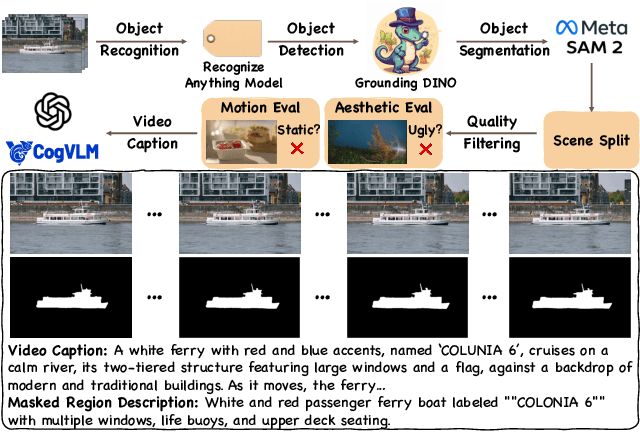
Video inpainting, which aims to restore corrupted video content, has experienced substantial progress. Despite these advances, existing methods, whether propagating unmasked region pixels through optical flow and receptive field priors, or extending image-inpainting models temporally, face challenges in generating fully masked objects or balancing the competing objectives of background context preservation and foreground generation in one model, respectively. To address these limitations, we propose a novel dual-stream paradigm VideoPainter that incorporates an efficient context encoder (comprising only 6% of the backbone parameters) to process masked videos and inject backbone-aware background contextual cues to any pre-trained video DiT, producing semantically consistent content in a plug-and-play manner. This architectural separation significantly reduces the model's learning complexity while enabling nuanced integration of crucial background context. We also introduce a novel target region ID resampling technique that enables any-length video inpainting, greatly enhancing our practical applicability. Additionally, we establish a scalable dataset pipeline leveraging current vision understanding models, contributing VPData and VPBench to facilitate segmentation-based inpainting training and assessment, the largest video inpainting dataset and benchmark to date with over 390K diverse clips. Using inpainting as a pipeline basis, we also explore downstream applications including video editing and video editing pair data generation, demonstrating competitive performance and significant practical potential. Extensive experiments demonstrate VideoPainter's superior performance in both any-length video inpainting and editing, across eight key metrics, including video quality, mask region preservation, and textual coherence.
Anti-Diffusion: Preventing Abuse of Modifications of Diffusion-Based Models
Mar 07, 2025Although diffusion-based techniques have shown remarkable success in image generation and editing tasks, their abuse can lead to severe negative social impacts. Recently, some works have been proposed to provide defense against the abuse of diffusion-based methods. However, their protection may be limited in specific scenarios by manually defined prompts or the stable diffusion (SD) version. Furthermore, these methods solely focus on tuning methods, overlooking editing methods that could also pose a significant threat. In this work, we propose Anti-Diffusion, a privacy protection system designed for general diffusion-based methods, applicable to both tuning and editing techniques. To mitigate the limitations of manually defined prompts on defense performance, we introduce the prompt tuning (PT) strategy that enables precise expression of original images. To provide defense against both tuning and editing methods, we propose the semantic disturbance loss (SDL) to disrupt the semantic information of protected images. Given the limited research on the defense against editing methods, we develop a dataset named Defense-Edit to assess the defense performance of various methods. Experiments demonstrate that our Anti-Diffusion achieves superior defense performance across a wide range of diffusion-based techniques in different scenarios.
Image Conductor: Precision Control for Interactive Video Synthesis
Jun 21, 2024Filmmaking and animation production often require sophisticated techniques for coordinating camera transitions and object movements, typically involving labor-intensive real-world capturing. Despite advancements in generative AI for video creation, achieving precise control over motion for interactive video asset generation remains challenging. To this end, we propose Image Conductor, a method for precise control of camera transitions and object movements to generate video assets from a single image. An well-cultivated training strategy is proposed to separate distinct camera and object motion by camera LoRA weights and object LoRA weights. To further address cinematographic variations from ill-posed trajectories, we introduce a camera-free guidance technique during inference, enhancing object movements while eliminating camera transitions. Additionally, we develop a trajectory-oriented video motion data curation pipeline for training. Quantitative and qualitative experiments demonstrate our method's precision and fine-grained control in generating motion-controllable videos from images, advancing the practical application of interactive video synthesis. Project webpage available at https://liyaowei-stu.github.io/project/ImageConductor/
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Dec 11, 2023



Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.
StyleAdapter: A Single-Pass LoRA-Free Model for Stylized Image Generation
Sep 04, 2023This paper presents a LoRA-free method for stylized image generation that takes a text prompt and style reference images as inputs and produces an output image in a single pass. Unlike existing methods that rely on training a separate LoRA for each style, our method can adapt to various styles with a unified model. However, this poses two challenges: 1) the prompt loses controllability over the generated content, and 2) the output image inherits both the semantic and style features of the style reference image, compromising its content fidelity. To address these challenges, we introduce StyleAdapter, a model that comprises two components: a two-path cross-attention module (TPCA) and three decoupling strategies. These components enable our model to process the prompt and style reference features separately and reduce the strong coupling between the semantic and style information in the style references. StyleAdapter can generate high-quality images that match the content of the prompts and adopt the style of the references (even for unseen styles) in a single pass, which is more flexible and efficient than previous methods. Experiments have been conducted to demonstrate the superiority of our method over previous works.
DeSRA: Detect and Delete the Artifacts of GAN-based Real-World Super-Resolution Models
Jul 05, 2023
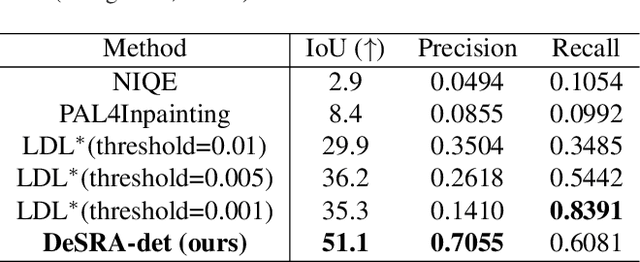

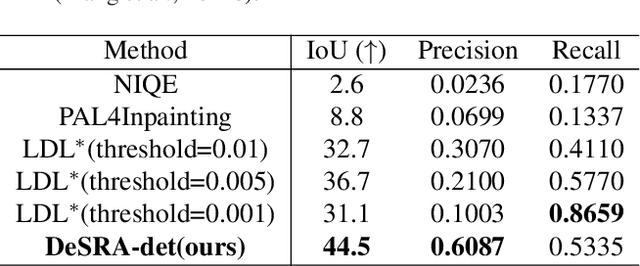
Image super-resolution (SR) with generative adversarial networks (GAN) has achieved great success in restoring realistic details. However, it is notorious that GAN-based SR models will inevitably produce unpleasant and undesirable artifacts, especially in practical scenarios. Previous works typically suppress artifacts with an extra loss penalty in the training phase. They only work for in-distribution artifact types generated during training. When applied in real-world scenarios, we observe that those improved methods still generate obviously annoying artifacts during inference. In this paper, we analyze the cause and characteristics of the GAN artifacts produced in unseen test data without ground-truths. We then develop a novel method, namely, DeSRA, to Detect and then Delete those SR Artifacts in practice. Specifically, we propose to measure a relative local variance distance from MSE-SR results and GAN-SR results, and locate the problematic areas based on the above distance and semantic-aware thresholds. After detecting the artifact regions, we develop a finetune procedure to improve GAN-based SR models with a few samples, so that they can deal with similar types of artifacts in more unseen real data. Equipped with our DeSRA, we can successfully eliminate artifacts from inference and improve the ability of SR models to be applied in real-world scenarios. The code will be available at https://github.com/TencentARC/DeSRA.