 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See and Act: Task-Aware View Planning for Robotic Manipulation
Aug 07, 2025Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-Aware View Planning (TAVP), a framework designed to overcome these challenges by integrating active view planning with task-specific representation learning. TAVP employs an efficient exploration policy, accelerated by a novel pseudo-environment, to actively acquire informative views. Furthermore, we introduce a Mixture-of-Experts (MoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TAVP generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. Extensive experiments on RLBench tasks show that our proposed TAVP model achieves superior performance over state-of-the-art fixed-view approaches. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.
ObjectClear: Complete Object Removal via Object-Effect Attention
May 28, 2025Object removal requires eliminating not only the target object but also its effects, such as shadows and reflections. However, diffusion-based inpainting methods often produce artifacts, hallucinate content, alter background, and struggle to remove object effects accurately. To address this challenge, we introduce a new dataset for OBject-Effect Removal, named OBER, which provides paired images with and without object effects, along with precise masks for both objects and their associated visual artifacts. The dataset comprises high-quality captured and simulated data, covering diverse object categories and complex multi-object scenes. Building on OBER, we propose a novel framework, ObjectClear, which incorporates an object-effect attention mechanism to guide the model toward the foreground removal regions by learning attention masks, effectively decoupling foreground removal from background reconstruction. Furthermore, the predicted attention map enables an attention-guided fusion strategy during inference, greatly preserving background details. Extensive experiments demonstrate that ObjectClear outperforms existing methods, achieving improved object-effect removal quality and background fidelity, especially in complex scenarios.
ObjCtrl-2.5D: Training-free Object Control with Camera Poses
Dec 10, 2024



This study aims to achieve more precise and versatile object control in image-to-video (I2V) generation. Current methods typically represent the spatial movement of target objects with 2D trajectories, which often fail to capture user intention and frequently produce unnatural results. To enhance control, we present ObjCtrl-2.5D, a training-free object control approach that uses a 3D trajectory, extended from a 2D trajectory with depth information, as a control signal. By modeling object movement as camera movement, ObjCtrl-2.5D represents the 3D trajectory as a sequence of camera poses, enabling object motion control using an existing camera motion control I2V generation model (CMC-I2V) without training. To adapt the CMC-I2V model originally designed for global motion control to handle local object motion, we introduce a module to isolate the target object from the background, enabling independent local control. In addition, we devise an effective way to achieve more accurate object control by sharing low-frequency warped latent within the object's region across frames. Extensive experiments demonstrate that ObjCtrl-2.5D significantly improves object control accuracy compared to training-free methods and offers more diverse control capabilities than training-based approaches using 2D trajectories, enabling complex effects like object rotation. Code and results are available at https://wzhouxiff.github.io/projects/ObjCtrl-2.5D/.
Analysis and Benchmarking of Extending Blind Face Image Restoration to Videos
Oct 15, 2024

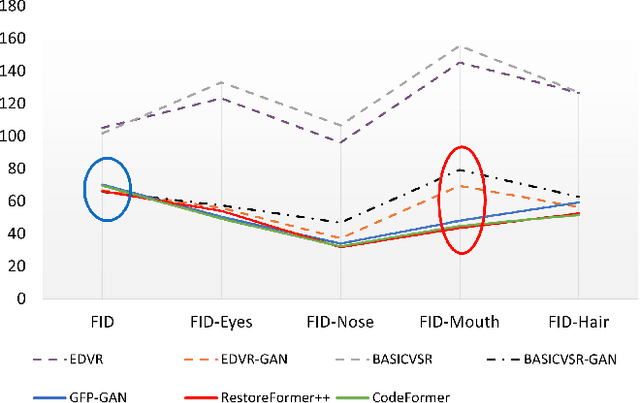
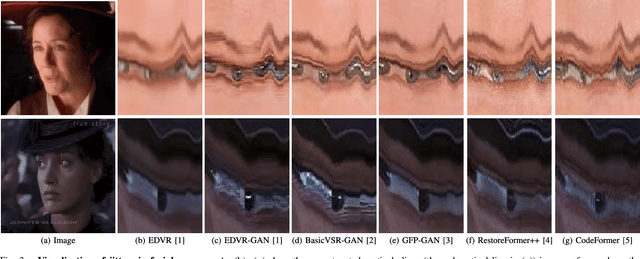
Recent progress in blind face restoration has resulted in producing high-quality restored results for static images. However, efforts to extend these advancements to video scenarios have been minimal, partly because of the absence of benchmarks that allow for a comprehensive and fair comparison. In this work, we first present a fair evaluation benchmark, in which we first introduce a Real-world Low-Quality Face Video benchmark (RFV-LQ), evaluate several leading image-based face restoration algorithms, and conduct a thorough systematical analysis of the benefits and challenges associated with extending blind face image restoration algorithms to degraded face videos. Our analysis identifies several key issues, primarily categorized into two aspects: significant jitters in facial components and noise-shape flickering between frames. To address these issues, we propose a Temporal Consistency Network (TCN) cooperated with alignment smoothing to reduce jitters and flickers in restored videos. TCN is a flexible component that can be seamlessly plugged into the most advanced face image restoration algorithms, ensuring the quality of image-based restoration is maintained as closely as possible. Extensive experiments have been conducted to evaluate the effectiveness and efficiency of our proposed TCN and alignment smoothing operation. Project page: https://wzhouxiff.github.io/projects/FIR2FVR/FIR2FVR.
* Accepted by TIP'2024; Project page: https://wzhouxiff.github.io/projects/FIR2FVR/FIR2FVR
Denoising as Adaptation: Noise-Space Domain Adaptation for Image Restoration
Jun 26, 2024



Although deep learning-based image restoration methods have made significant progress, they still struggle with limited generalization to real-world scenarios due to the substantial domain gap caused by training on synthetic data. Existing methods address this issue by improving data synthesis pipelines, estimating degradation kernels, employing deep internal learning, and performing domain adaptation and regularization. Previous domain adaptation methods have sought to bridge the domain gap by learning domain-invariant knowledge in either feature or pixel space. However, these techniques often struggle to extend to low-level vision tasks within a stable and compact framework. In this paper, we show that it is possible to perform domain adaptation via the noise-space using diffusion models. In particular, by leveraging the unique property of how the multi-step denoising process is influenced by auxiliary conditional inputs, we obtain meaningful gradients from noise prediction to gradually align the restored results of both synthetic and real-world data to a common clean distribution. We refer to this method as denoising as adaptation. To prevent shortcuts during training, we present useful techniques such as channel shuffling and residual-swapping contrastive learning. Experimental results on three classical image restoration tasks, namely denoising, deblurring, and deraining, demonstrate the effectiveness of the proposed method. Code will be released at: https://github.com/KangLiao929/Noise-DA/.
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
Jun 24, 2024

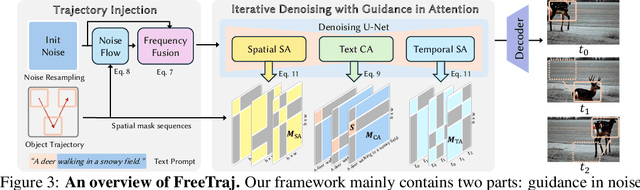
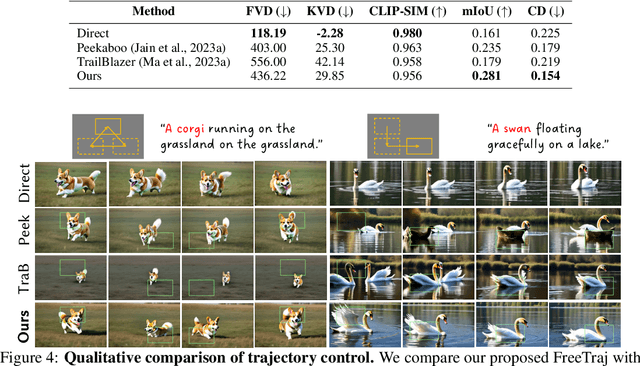
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomenons and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.
Image Conductor: Precision Control for Interactive Video Synthesis
Jun 21, 2024Filmmaking and animation production often require sophisticated techniques for coordinating camera transitions and object movements, typically involving labor-intensive real-world capturing. Despite advancements in generative AI for video creation, achieving precise control over motion for interactive video asset generation remains challenging. To this end, we propose Image Conductor, a method for precise control of camera transitions and object movements to generate video assets from a single image. An well-cultivated training strategy is proposed to separate distinct camera and object motion by camera LoRA weights and object LoRA weights. To further address cinematographic variations from ill-posed trajectories, we introduce a camera-free guidance technique during inference, enhancing object movements while eliminating camera transitions. Additionally, we develop a trajectory-oriented video motion data curation pipeline for training. Quantitative and qualitative experiments demonstrate our method's precision and fine-grained control in generating motion-controllable videos from images, advancing the practical application of interactive video synthesis. Project webpage available at https://liyaowei-stu.github.io/project/ImageConductor/
Diffusion-based Blind Text Image Super-Resolution
Dec 13, 2023Recovering degraded low-resolution text images is challenging, especially for Chinese text images with complex strokes and severe degradation in real-world scenarios. Ensuring both text fidelity and style realness is crucial for high-quality text image super-resolution. Recently, diffusion models have achieved great success in natural image synthesis and restoration due to their powerful data distribution modeling abilities and data generation capabilities. In this work, we propose an Image Diffusion Model (IDM) to restore text images with realistic styles. For diffusion models, they are not only suitable for modeling realistic image distribution but also appropriate for learning text distribution. Since text prior is important to guarantee the correctness of the restored text structure according to existing arts, we also propose a Text Diffusion Model (TDM) for text recognition which can guide IDM to generate text images with correct structures. We further propose a Mixture of Multi-modality module (MoM) to make these two diffusion models cooperate with each other in all the diffusion steps. Extensive experiments on synthetic and real-world datasets demonstrate that our Diffusion-based Blind Text Image Super-Resolution (DiffTSR) can restore text images with more accurate text structures as well as more realistic appearances simultaneously.
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation
Dec 06, 2023



Motions in a video primarily consist of camera motion, induced by camera movement, and object motion, resulting from object movement. Accurate control of both camera and object motion is essential for video generation. However, existing works either mainly focus on one type of motion or do not clearly distinguish between the two, limiting their control capabilities and diversity. Therefore, this paper presents MotionCtrl, a unified and flexible motion controller for video generation designed to effectively and independently control camera and object motion. The architecture and training strategy of MotionCtrl are carefully devised, taking into account the inherent properties of camera motion, object motion, and imperfect training data. Compared to previous methods, MotionCtrl offers three main advantages: 1) It effectively and independently controls camera motion and object motion, enabling more fine-grained motion control and facilitating flexible and diverse combinations of both types of motion. 2) Its motion conditions are determined by camera poses and trajectories, which are appearance-free and minimally impact the appearance or shape of objects in generated videos. 3) It is a relatively generalizable model that can adapt to a wide array of camera poses and trajectories once trained. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of MotionCtrl over existing methods.
StyleAdapter: A Single-Pass LoRA-Free Model for Stylized Image Generation
Sep 04, 2023This paper presents a LoRA-free method for stylized image generation that takes a text prompt and style reference images as inputs and produces an output image in a single pass. Unlike existing methods that rely on training a separate LoRA for each style, our method can adapt to various styles with a unified model. However, this poses two challenges: 1) the prompt loses controllability over the generated content, and 2) the output image inherits both the semantic and style features of the style reference image, compromising its content fidelity. To address these challenges, we introduce StyleAdapter, a model that comprises two components: a two-path cross-attention module (TPCA) and three decoupling strategies. These components enable our model to process the prompt and style reference features separately and reduce the strong coupling between the semantic and style information in the style references. StyleAdapter can generate high-quality images that match the content of the prompts and adopt the style of the references (even for unseen styles) in a single pass, which is more flexible and efficient than previous methods. Experiments have been conducted to demonstrate the superiority of our method over previous works.