 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025
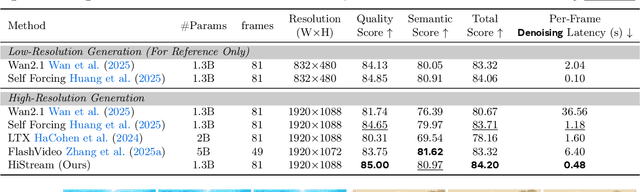
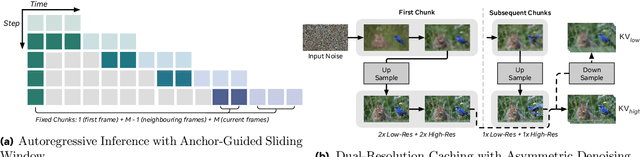
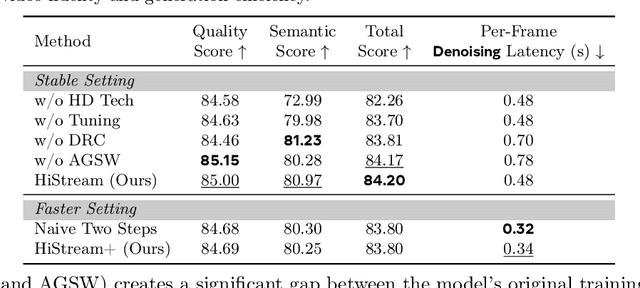
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
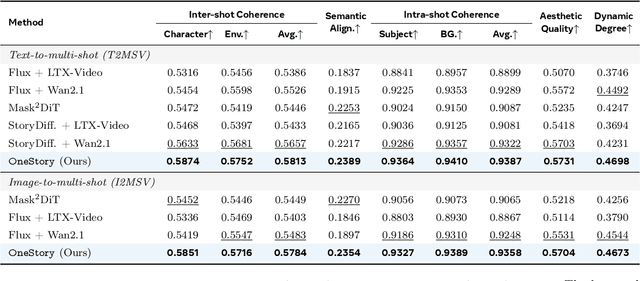
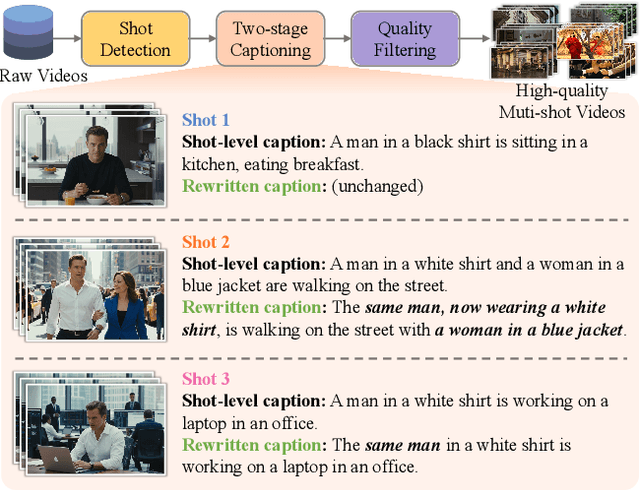

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
Oct 06, 2025Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.
FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Dec 12, 2024



Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions. Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns. The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors. To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components. Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model
Nov 28, 2024


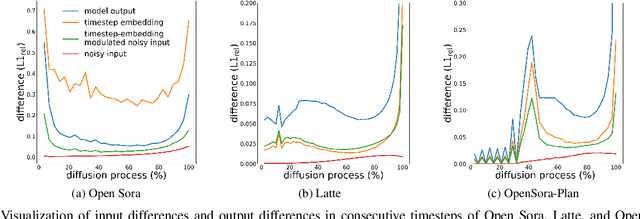
As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising. Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps. However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality. In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps. Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost. TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching. Experiments show that TeaCache achieves up to 4.41x acceleration over Open-Sora-Plan with negligible (-0.07% Vbench score) degradation of visual quality.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024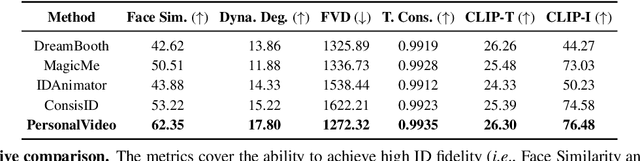
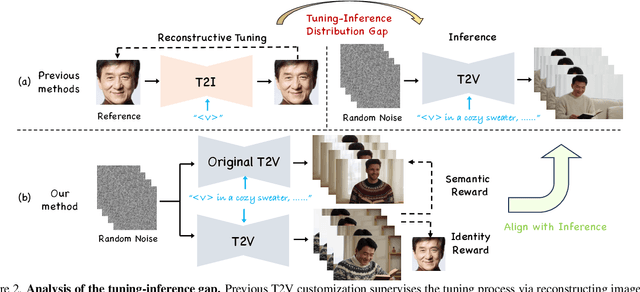
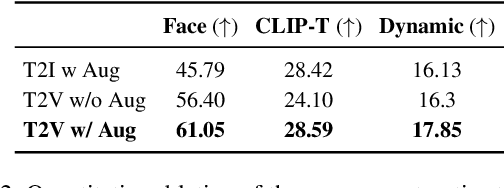
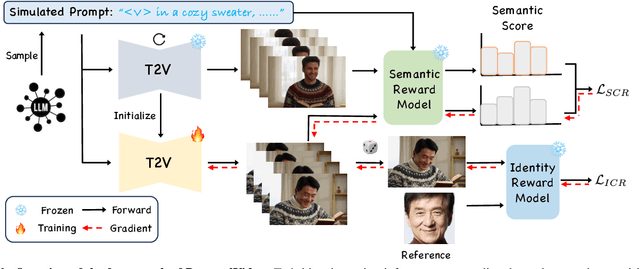
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Oct 17, 2024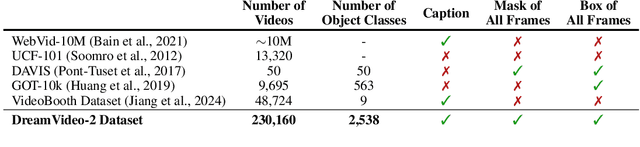
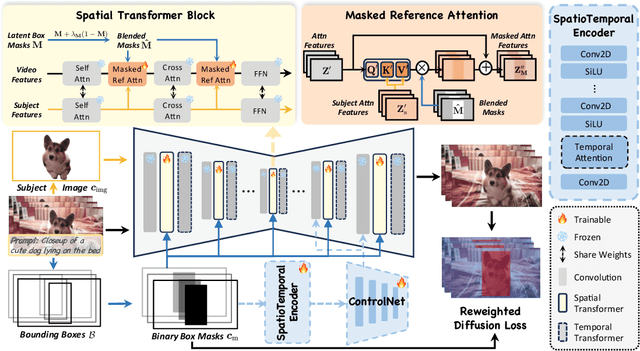


Recent advances in customized video generation have enabled users to create videos tailored to both specific subjects and motion trajectories. However, existing methods often require complicated test-time fine-tuning and struggle with balancing subject learning and motion control, limiting their real-world applications. In this paper, we present DreamVideo-2, a zero-shot video customization framework capable of generating videos with a specific subject and motion trajectory, guided by a single image and a bounding box sequence, respectively, and without the need for test-time fine-tuning. Specifically, we introduce reference attention, which leverages the model's inherent capabilities for subject learning, and devise a mask-guided motion module to achieve precise motion control by fully utilizing the robust motion signal of box masks derived from bounding boxes. While these two components achieve their intended functions, we empirically observe that motion control tends to dominate over subject learning. To address this, we propose two key designs: 1) the masked reference attention, which integrates a blended latent mask modeling scheme into reference attention to enhance subject representations at the desired positions, and 2) a reweighted diffusion loss, which differentiates the contributions of regions inside and outside the bounding boxes to ensure a balance between subject and motion control. Extensive experimental results on a newly curated dataset demonstrate that DreamVideo-2 outperforms state-of-the-art methods in both subject customization and motion control. The dataset, code, and models will be made publicly available.
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
Jun 24, 2024

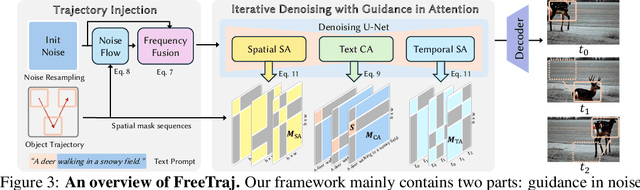
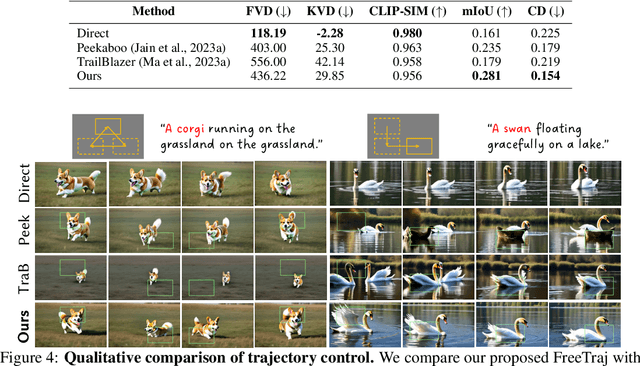
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomenons and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.
FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling
Oct 27, 2023



With the availability of large-scale video datasets and the advances of diffusion models, text-driven video generation has achieved substantial progress. However, existing video generation models are typically trained on a limited number of frames, resulting in the inability to generate high-fidelity long videos during inference. Furthermore, these models only support single-text conditions, whereas real-life scenarios often require multi-text conditions as the video content changes over time. To tackle these challenges, this study explores the potential of extending the text-driven capability to generate longer videos conditioned on multiple texts. 1) We first analyze the impact of initial noise in video diffusion models. Then building upon the observation of noise, we propose FreeNoise, a tuning-free and time-efficient paradigm to enhance the generative capabilities of pretrained video diffusion models while preserving content consistency. Specifically, instead of initializing noises for all frames, we reschedule a sequence of noises for long-range correlation and perform temporal attention over them by window-based function. 2) Additionally, we design a novel motion injection method to support the generation of videos conditioned on multiple text prompts. Extensive experiments validate the superiority of our paradigm in extending the generative capabilities of video diffusion models. It is noteworthy that compared with the previous best-performing method which brought about 255% extra time cost, our method incurs only negligible time cost of approximately 17%. Generated video samples are available at our website: http://haonanqiu.com/projects/FreeNoise.html.