 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimestep Embedding Tells: It's Time to Cache for Video Diffusion Model
Paper and Code



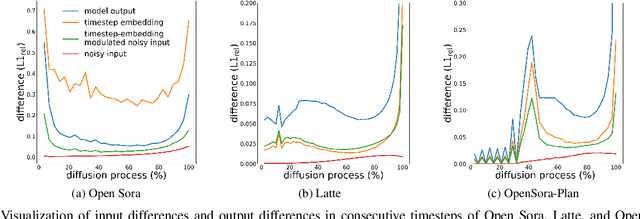
As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising. Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps. However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality. In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps. Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost. TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching. Experiments show that TeaCache achieves up to 4.41x acceleration over Open-Sora-Plan with negligible (-0.07% Vbench score) degradation of visual quality.