 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Calibrated Diffusion for Reliable 3D Molecular Graph Generation
Jun 01, 2026Bayesian inference provides a principled framework for modeling epistemic uncertainty in neural networks by treating predictions as distributions rather than deterministic values. Meanwhile, diffusion-based models for 3D molecular graph generation operate on fragile geometric structures governed by strict chemical constraints, making inference highly sensitive to uncertainty miscalibration. A largely overlooked issue is that epistemic uncertainty arising from the learned denoiser interacts with the aleatoric uncertainty intentionally injected during reverse diffusion, leading to systematic variance inflation and a mismatch between the true distribution and the simulated distribution. This effect is particularly detrimental for high-precision molecular generation, where even small deviations can violate chemical validity. In this work, we provide a theoretical and empirical analysis of how epistemic uncertainty propagates through diffusion inference and degrades sampling quality. Building on this investigation, we propose UCD (Uncertainty-Calibrated Diffusion), a simple yet effective method that calibrates the reverse diffusion process to account for epistemic uncertainty. Extensive experiments on standard 3D molecular benchmarks demonstrate that UCD consistently improves sampling quality across diverse baseline methods, establishing new state-of-the-art performance for 3D molecular diffusion. The code is available at https://github.com/jiuguaiwf/UCD.
asRoBallet: Closing the Sim2Real Gap via Friction-Aware Reinforcement Learning for Underactuated Spherical Dynamics
Apr 27, 2026We introduce asRoBallet, to the best of our knowledge, the first successful deployment of reinforcement learning (RL) on a humanoid ballbot hardware. Historically, ballbots have served as a canonical benchmark for underactuated and nonholonomic control, which are characterized by a reality gap in complex friction models for wheel-sphere-ground interactions. While current literature demonstrates successful handling of 3D balancing with LQR and MPC, transitioning to actual hardware for a humanoid ballbot using RL is currently hindered by critical gaps in contact modeling, actuator latency & jitter, and safe hardware exploration, and safe hardware exploration. This study proposes a high-fidelity MuJoCo simulation that explicitly models the discrete roller mechanics of ETH-type omni-wheels, thereby capturing parasitic vibrations and contact discontinuities that are previously ignored. We also developed a Friction-Aware Reinforcement Learning framework that achieves zero-shot Sim2Real transfer by mastering the coupled rolling, lateral, and torsional friction channels at the wheel-sphere and sphere-ground interfaces. We designed asRoBallet through subtractive reconfiguration, repurposing key components from an overconstrained quadruped and integrating them into a newly designed structural frame to achieve a robust research platform at low cost. We also developed a generalized iOS ecosystem that transforms consumer electronics into a low-latency interface, enabling a single operator to orchestrate expressive humanoid maneuvers via intuitive natural motion.
Thinking with Images via Self-Calling Agent
Dec 11, 2025Thinking-with-images paradigms have showcased remarkable visual reasoning capability by integrating visual information as dynamic elements into the Chain-of-Thought (CoT). However, optimizing interleaved multimodal CoT (iMCoT) through reinforcement learning remains challenging, as it relies on scarce high-quality reasoning data. In this study, we propose Self-Calling Chain-of-Thought (sCoT), a novel visual reasoning paradigm that reformulates iMCoT as a language-only CoT with self-calling. Specifically, a main agent decomposes the complex visual reasoning task to atomic subtasks and invokes its virtual replicas, i.e. parameter-sharing subagents, to solve them in isolated context. sCoT enjoys substantial training effectiveness and efficiency, as it requires no explicit interleaving between modalities. sCoT employs group-relative policy optimization to reinforce effective reasoning behavior to enhance optimization. Experiments on HR-Bench 4K show that sCoT improves the overall reasoning performance by up to $1.9\%$ with $\sim 75\%$ fewer GPU hours compared to strong baseline approaches. Code is available at https://github.com/YWenxi/think-with-images-through-self-calling.
One-DoF Robotic Design of Overconstrained Limbs with Energy-Efficient, Self-Collision-Free Motion
Sep 26, 2025While it is expected to build robotic limbs with multiple degrees of freedom (DoF) inspired by nature, a single DoF design remains fundamental, providing benefits that include, but are not limited to, simplicity, robustness, cost-effectiveness, and efficiency. Mechanisms, especially those with multiple links and revolute joints connected in closed loops, play an enabling factor in introducing motion diversity for 1-DoF systems, which are usually constrained by self-collision during a full-cycle range of motion. This study presents a novel computational approach to designing one-degree-of-freedom (1-DoF) overconstrained robotic limbs for a desired spatial trajectory, while achieving energy-efficient, self-collision-free motion in full-cycle rotations. Firstly, we present the geometric optimization problem of linkage-based robotic limbs in a generalized formulation for self-collision-free design. Next, we formulate the spatial trajectory generation problem with the overconstrained linkages by optimizing the similarity and dynamic-related metrics. We further optimize the geometric shape of the overconstrained linkage to ensure smooth and collision-free motion driven by a single actuator. We validated our proposed method through various experiments, including personalized automata and bio-inspired hexapod robots. The resulting hexapod robot, featuring overconstrained robotic limbs, demonstrated outstanding energy efficiency during forward walking.
Geometric-Mean Policy Optimization
Jul 28, 2025Recent advancements, such as Group Relative Policy Optimization (GRPO), have enhanced the reasoning capabilities of large language models by optimizing the arithmetic mean of token-level rewards. However, GRPO suffers from unstable policy updates when processing tokens with outlier importance-weighted rewards, which manifests as extreme importance sampling ratios during training, i.e., the ratio between the sampling probabilities assigned to a token by the current and old policies. In this work, we propose Geometric-Mean Policy Optimization (GMPO), a stabilized variant of GRPO. Instead of optimizing the arithmetic mean, GMPO maximizes the geometric mean of token-level rewards, which is inherently less sensitive to outliers and maintains a more stable range of importance sampling ratio. In addition, we provide comprehensive theoretical and experimental analysis to justify the design and stability benefits of GMPO. Beyond improved stability, GMPO-7B outperforms GRPO by an average of 4.1% on multiple mathematical benchmarks and 1.4% on multimodal reasoning benchmark, including AIME24, AMC, MATH500, OlympiadBench, Minerva, and Geometry3K. Code is available at https://github.com/callsys/GMPO.
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model
Nov 28, 2024


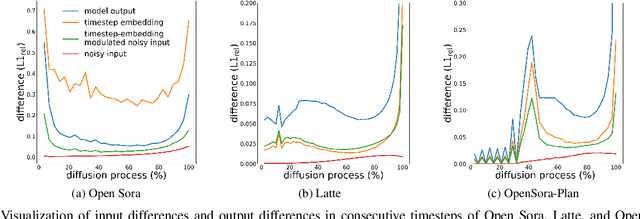
As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising. Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps. However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality. In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps. Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost. TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching. Experiments show that TeaCache achieves up to 4.41x acceleration over Open-Sora-Plan with negligible (-0.07% Vbench score) degradation of visual quality.
Correspondence-Guided SfM-Free 3D Gaussian Splatting for NVS
Aug 16, 2024Novel View Synthesis (NVS) without Structure-from-Motion (SfM) pre-processed camera poses--referred to as SfM-free methods--is crucial for promoting rapid response capabilities and enhancing robustness against variable operating conditions. Recent SfM-free methods have integrated pose optimization, designing end-to-end frameworks for joint camera pose estimation and NVS. However, most existing works rely on per-pixel image loss functions, such as L2 loss. In SfM-free methods, inaccurate initial poses lead to misalignment issue, which, under the constraints of per-pixel image loss functions, results in excessive gradients, causing unstable optimization and poor convergence for NVS. In this study, we propose a correspondence-guided SfM-free 3D Gaussian splatting for NVS. We use correspondences between the target and the rendered result to achieve better pixel alignment, facilitating the optimization of relative poses between frames. We then apply the learned poses to optimize the entire scene. Each 2D screen-space pixel is associated with its corresponding 3D Gaussians through approximated surface rendering to facilitate gradient back propagation. Experimental results underline the superior performance and time efficiency of the proposed approach compared to the state-of-the-art baselines.
On Flange-based 3D Hand-Eye Calibration for Soft Robotic Tactile Welding
Jul 27, 2024



This paper investigates the direct application of standardized designs on the robot for conducting robot hand-eye calibration by employing 3D scanners with collaborative robots. The well-established geometric features of the robot flange are exploited by directly capturing its point cloud data. In particular, an iterative method is proposed to facilitate point cloud processing toward a refined calibration outcome. Several extensive experiments are conducted over a range of collaborative robots, including Universal Robots UR5 & UR10 e-series, Franka Emika, and AUBO i5 using an industrial-grade 3D scanner Photoneo Phoxi S & M and a commercial-grade 3D scanner Microsoft Azure Kinect DK. Experimental results show that translational and rotational errors converge efficiently to less than 0.28 mm and 0.25 degrees, respectively, achieving a hand-eye calibration accuracy as high as the camera's resolution, probing the hardware limit. A welding seam tracking system is presented, combining the flange-based calibration method with soft tactile sensing. The experiment results show that the system enables the robot to adjust its motion in real-time, ensuring consistent weld quality and paving the way for more efficient and adaptable manufacturing processes.
Close the Sim2real Gap via Physically-based Structured Light Synthetic Data Simulation
Jul 17, 2024



Despite the substantial progress in deep learning, its adoption in industrial robotics projects remains limited, primarily due to challenges in data acquisition and labeling. Previous sim2real approaches using domain randomization require extensive scene and model optimization. To address these issues, we introduce an innovative physically-based structured light simulation system, generating both RGB and physically realistic depth images, surpassing previous dataset generation tools. We create an RGBD dataset tailored for robotic industrial grasping scenarios and evaluate it across various tasks, including object detection, instance segmentation, and embedding sim2real visual perception in industrial robotic grasping. By reducing the sim2real gap and enhancing deep learning training, we facilitate the application of deep learning models in industrial settings. Project details are available at https://baikaixinpublic.github.io/structured light 3D synthesizer/.
Evolutionary Morphology Towards Overconstrained Locomotion via Large-Scale, Multi-Terrain Deep Reinforcement Learning
Jul 01, 2024



While the animals' Fin-to-Limb evolution has been well-researched in biology, such morphological transformation remains under-adopted in the modern design of advanced robotic limbs. This paper investigates a novel class of overconstrained locomotion from a design and learning perspective inspired by evolutionary morphology, aiming to integrate the concept of `intelligent design under constraints' - hereafter referred to as constraint-driven design intelligence - in developing modern robotic limbs with superior energy efficiency. We propose a 3D-printable design of robotic limbs parametrically reconfigurable as a classical planar 4-bar linkage, an overconstrained Bennett linkage, and a spherical 4-bar linkage. These limbs adopt a co-axial actuation, identical to the modern legged robot platforms, with the added capability of upgrading into a wheel-legged system. Then, we implemented a large-scale, multi-terrain deep reinforcement learning framework to train these reconfigurable limbs for a comparative analysis of overconstrained locomotion in energy efficiency. Results show that the overconstrained limbs exhibit more efficient locomotion than planar limbs during forward and sideways walking over different terrains, including floors, slopes, and stairs, with or without random noises, by saving at least 22% mechanical energy in completing the traverse task, with the spherical limbs being the least efficient. It also achieves the highest average speed of 0.85 meters per second on flat terrain, which is 20% faster than the planar limbs. This study paves the path for an exciting direction for future research in overconstrained robotics leveraging evolutionary morphology and reconfigurable mechanism intelligence when combined with state-of-the-art methods in deep reinforcement learning.