 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFipTR: A Simple yet Effective Transformer Framework for Future Instance Prediction in Autonomous Driving
Apr 19, 2024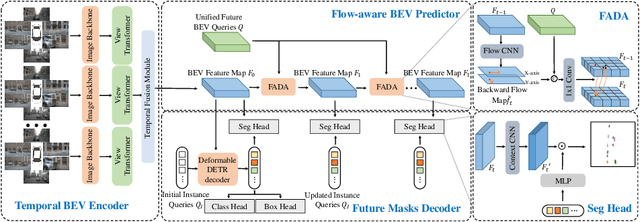
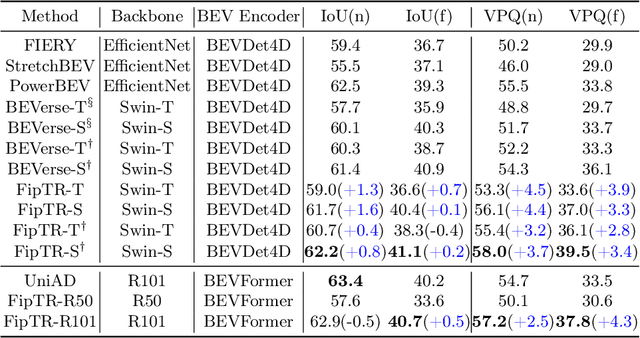
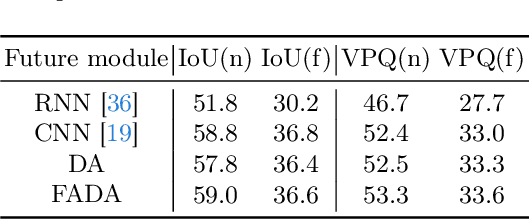

The future instance prediction from a Bird's Eye View(BEV) perspective is a vital component in autonomous driving, which involves future instance segmentation and instance motion prediction. Existing methods usually rely on a redundant and complex pipeline which requires multiple auxiliary outputs and post-processing procedures. Moreover, estimated errors on each of the auxiliary predictions will lead to degradation of the prediction performance. In this paper, we propose a simple yet effective fully end-to-end framework named Future Instance Prediction Transformer(FipTR), which views the task as BEV instance segmentation and prediction for future frames. We propose to adopt instance queries representing specific traffic participants to directly estimate the corresponding future occupied masks, and thus get rid of complex post-processing procedures. Besides, we devise a flow-aware BEV predictor for future BEV feature prediction composed of a flow-aware deformable attention that takes backward flow guiding the offset sampling. A novel future instance matching strategy is also proposed to further improve the temporal coherence. Extensive experiments demonstrate the superiority of FipTR and its effectiveness under different temporal BEV encoders.
BEAM: Beta Distribution Ray Denoising for Multi-view 3D Object Detection
Feb 06, 2024



Multi-view 3D object detectors struggle with duplicate predictions due to the lack of depth information, resulting in false positive detections. In this study, we introduce BEAM, a novel Beta Distribution Ray Denoising approach that can be applied to any DETR-style multi-view 3D detector to explicitly incorporate structure prior knowledge of the scene. By generating rays from cameras to objects and sampling spatial denoising queries from the Beta distribution family along these rays, BEAM enhances the model's ability to distinguish spatial hard negative samples arising from ambiguous depths. BEAM is a plug-and-play technique that adds only marginal computational costs during training, while impressively preserving the inference speed. Extensive experiments and ablation studies on the NuScenes dataset demonstrate significant improvements over strong baselines, outperforming the state-of-the-art method StreamPETR by 1.9% mAP. The code will be available at https://github.com/LiewFeng/BEAM.
EPNet++: Cascade Bi-directional Fusion for Multi-Modal 3D Object Detection
Jan 12, 2022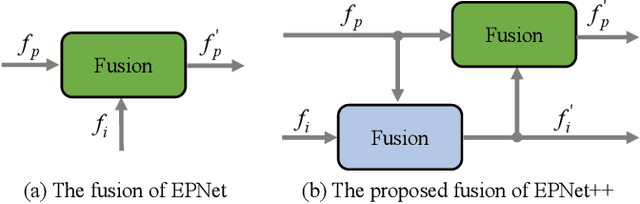



Recently, fusing the LiDAR point cloud and camera image to improve the performance and robustness of 3D object detection has received more and more attention, as these two modalities naturally possess strong complementarity. In this paper, we propose EPNet++ for multi-modal 3D object detection by introducing a novel Cascade Bi-directional Fusion~(CB-Fusion) module and a Multi-Modal Consistency~(MC) loss. More concretely, the proposed CB-Fusion module boosts the plentiful semantic information of point features with the image features in a cascade bi-directional interaction fusion manner, leading to more comprehensive and discriminative feature representations. The MC loss explicitly guarantees the consistency between predicted scores from two modalities to obtain more comprehensive and reliable confidence scores. The experiment results on the KITTI, JRDB and SUN-RGBD datasets demonstrate the superiority of EPNet++ over the state-of-the-art methods. Besides, we emphasize a critical but easily overlooked problem, which is to explore the performance and robustness of a 3D detector in a sparser scene. Extensive experiments present that EPNet++ outperforms the existing SOTA methods with remarkable margins in highly sparse point cloud cases, which might be an available direction to reduce the expensive cost of LiDAR sensors. Code will be released in the future.
Multi-Centroid Representation Network for Domain Adaptive Person Re-ID
Dec 22, 2021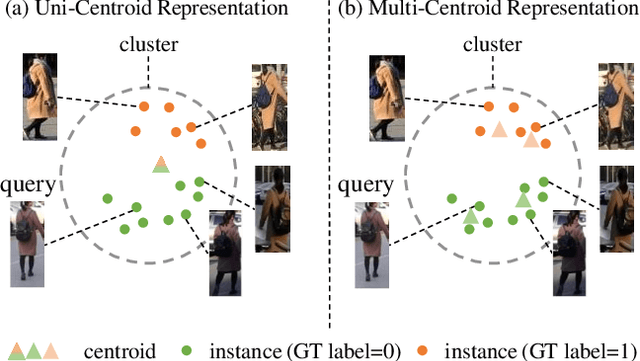
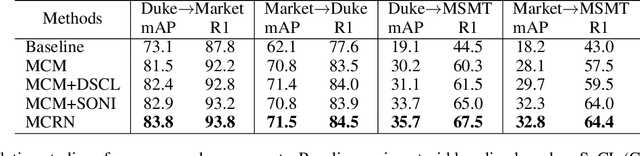
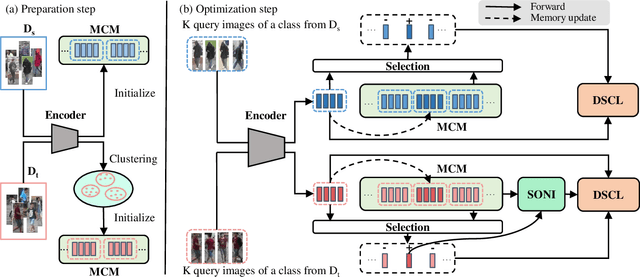
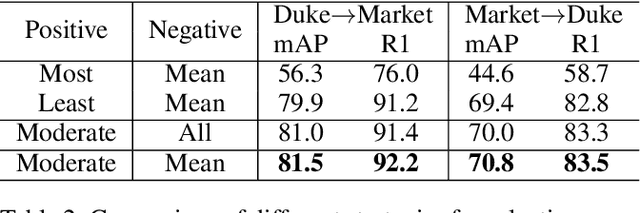
Recently, many approaches tackle the Unsupervised Domain Adaptive person re-identification (UDA re-ID) problem through pseudo-label-based contrastive learning. During training, a uni-centroid representation is obtained by simply averaging all the instance features from a cluster with the same pseudo label. However, a cluster may contain images with different identities (label noises) due to the imperfect clustering results, which makes the uni-centroid representation inappropriate. In this paper, we present a novel Multi-Centroid Memory (MCM) to adaptively capture different identity information within the cluster. MCM can effectively alleviate the issue of label noises by selecting proper positive/negative centroids for the query image. Moreover, we further propose two strategies to improve the contrastive learning process. First, we present a Domain-Specific Contrastive Learning (DSCL) mechanism to fully explore intradomain information by comparing samples only from the same domain. Second, we propose Second-Order Nearest Interpolation (SONI) to obtain abundant and informative negative samples. We integrate MCM, DSCL, and SONI into a unified framework named Multi-Centroid Representation Network (MCRN). Extensive experiments demonstrate the superiority of MCRN over state-of-the-art approaches on multiple UDA re-ID tasks and fully unsupervised re-ID tasks.
Spatial Ensemble: a Novel Model Smoothing Mechanism for Student-Teacher Framework
Oct 04, 2021


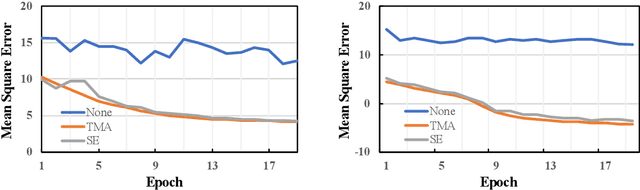
Model smoothing is of central importance for obtaining a reliable teacher model in the student-teacher framework, where the teacher generates surrogate supervision signals to train the student. A popular model smoothing method is the Temporal Moving Average (TMA), which continuously averages the teacher parameters with the up-to-date student parameters. In this paper, we propose "Spatial Ensemble", a novel model smoothing mechanism in parallel with TMA. Spatial Ensemble randomly picks up a small fragment of the student model to directly replace the corresponding fragment of the teacher model. Consequentially, it stitches different fragments of historical student models into a unity, yielding the "Spatial Ensemble" effect. Spatial Ensemble obtains comparable student-teacher learning performance by itself and demonstrates valuable complementarity with temporal moving average. Their integration, named Spatial-Temporal Smoothing, brings general (sometimes significant) improvement to the student-teacher learning framework on a variety of state-of-the-art methods. For example, based on the self-supervised method BYOL, it yields +0.9% top-1 accuracy improvement on ImageNet, while based on the semi-supervised approach FixMatch, it increases the top-1 accuracy by around +6% on CIFAR-10 when only few training labels are available. Codes and models are available at: https://github.com/tengteng95/Spatial_Ensemble.
Progressive and Aligned Pose Attention Transfer for Person Image Generation
Mar 22, 2021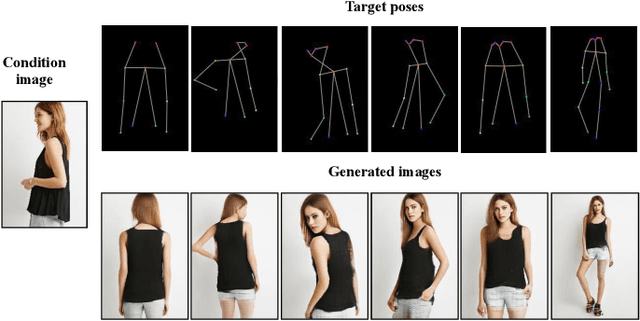
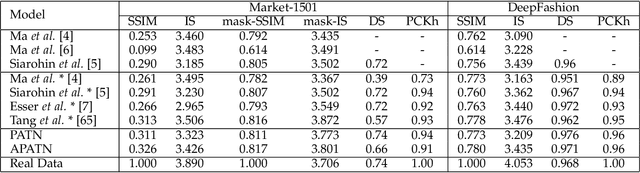
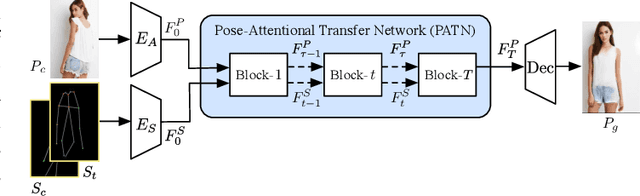
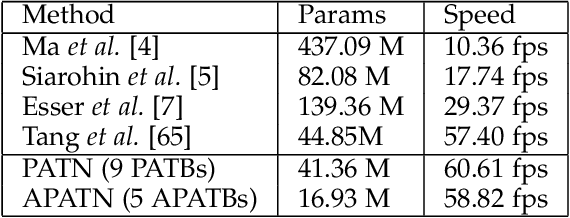
This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship between the condition and the target poses with attention mechanism. Two types of blocks are introduced, namely Pose-Attentional Transfer Block (PATB) and Aligned Pose-Attentional Transfer Bloc ~(APATB). Compared with previous works, our model generates more photorealistic person images that retain better appearance consistency and shape consistency compared with input images. We verify the efficacy of the model on the Market-1501 and DeepFashion datasets, using quantitative and qualitative measures. Furthermore, we show that our method can be used for data augmentation for the person re-identification task, alleviating the issue of data insufficiency. Code and pretrained models are available at https://github.com/tengteng95/Pose-Transfer.git.
EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
Jul 17, 2020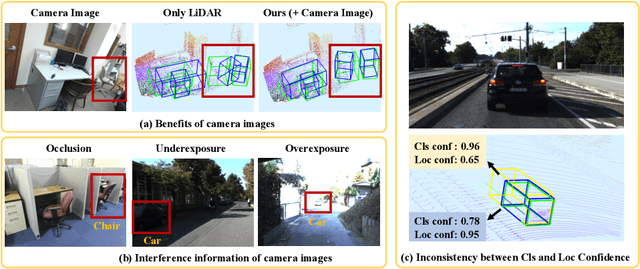
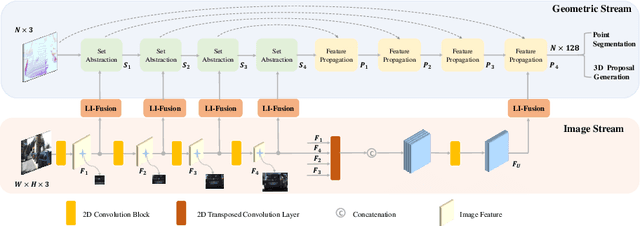


In this paper, we aim at addressing two critical issues in the 3D detection task, including the exploitation of multiple sensors~(namely LiDAR point cloud and camera image), as well as the inconsistency between the localization and classification confidence. To this end, we propose a novel fusion module to enhance the point features with semantic image features in a point-wise manner without any image annotations. Besides, a consistency enforcing loss is employed to explicitly encourage the consistency of both the localization and classification confidence. We design an end-to-end learnable framework named EPNet to integrate these two components. Extensive experiments on the KITTI and SUN-RGBD datasets demonstrate the superiority of EPNet over the state-of-the-art methods. Codes and models are available at: \url{https://github.com/happinesslz/EPNet}.
TANet: Robust 3D Object Detection from Point Clouds with Triple Attention
Dec 11, 2019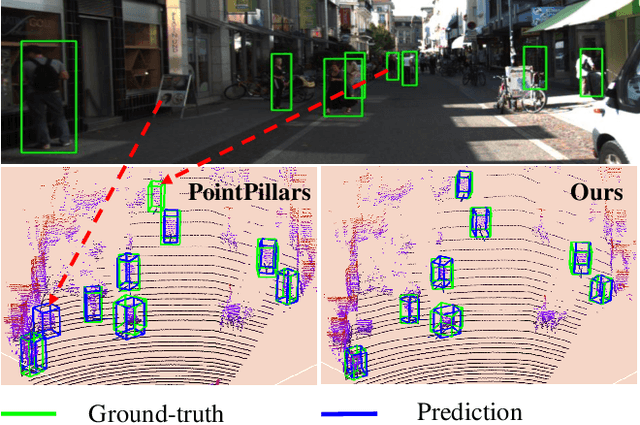

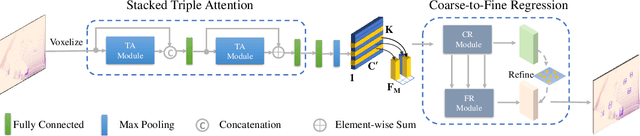

In this paper, we focus on exploring the robustness of the 3D object detection in point clouds, which has been rarely discussed in existing approaches. We observe two crucial phenomena: 1) the detection accuracy of the hard objects, e.g., Pedestrians, is unsatisfactory, 2) when adding additional noise points, the performance of existing approaches decreases rapidly. To alleviate these problems, a novel TANet is introduced in this paper, which mainly contains a Triple Attention (TA) module, and a Coarse-to-Fine Regression (CFR) module. By considering the channel-wise, point-wise and voxel-wise attention jointly, the TA module enhances the crucial information of the target while suppresses the unstable cloud points. Besides, the novel stacked TA further exploits the multi-level feature attention. In addition, the CFR module boosts the accuracy of localization without excessive computation cost. Experimental results on the validation set of KITTI dataset demonstrate that, in the challenging noisy cases, i.e., adding additional random noisy points around each object,the presented approach goes far beyond state-of-the-art approaches. Furthermore, for the 3D object detection task of the KITTI benchmark, our approach ranks the first place on Pedestrian class, by using the point clouds as the only input. The running speed is around 29 frames per second.
Asymmetric Non-local Neural Networks for Semantic Segmentation
Aug 29, 2019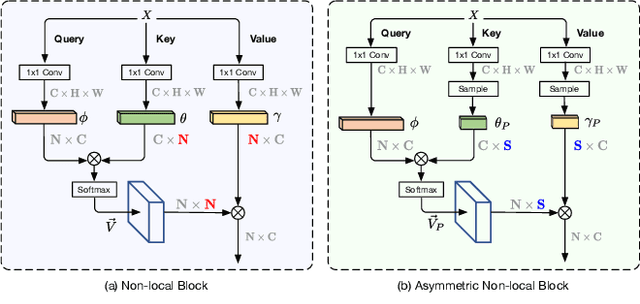
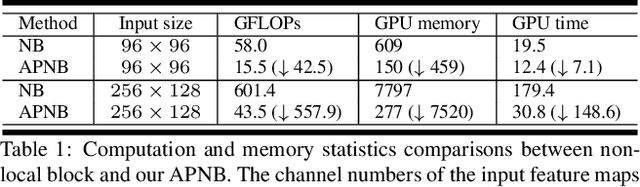
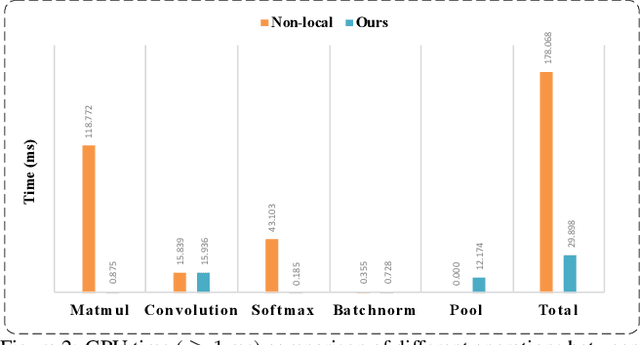
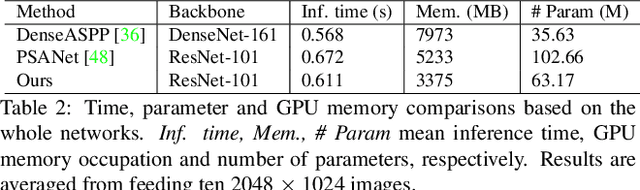
The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). APNB leverages a pyramid sampling module into the non-local block to largely reduce the computation and memory consumption without sacrificing the performance. AFNB is adapted from APNB to fuse the features of different levels under a sufficient consideration of long range dependencies and thus considerably improves the performance. Extensive experiments on semantic segmentation benchmarks demonstrate the effectiveness and efficiency of our work. In particular, we report the state-of-the-art performance of 81.3 mIoU on the Cityscapes test set. For a 256x128 input, APNB is around 6 times faster than a non-local block on GPU while 28 times smaller in GPU running memory occupation. Code is available at: https://github.com/MendelXu/ANN.git.
View N-gram Network for 3D Object Retrieval
Aug 15, 2019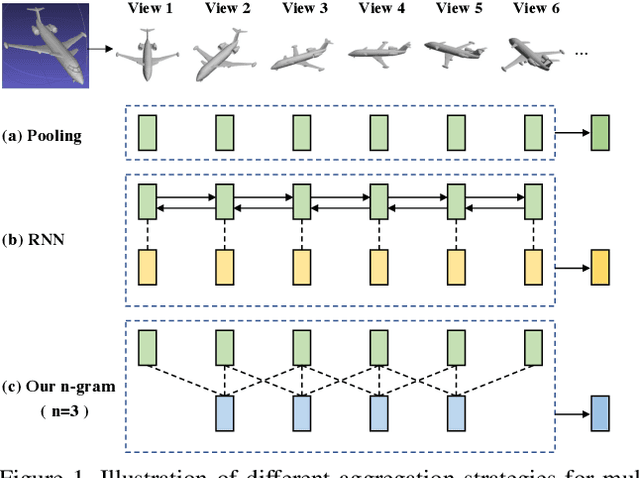

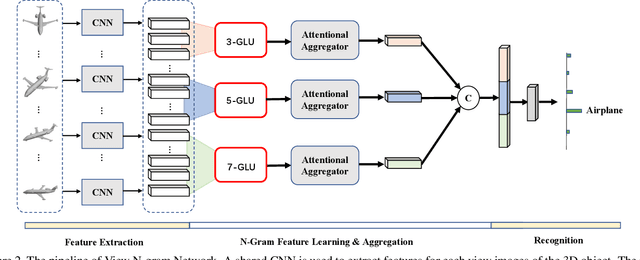
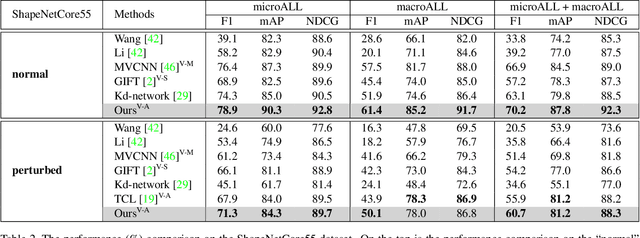
How to aggregate multi-view representations of a 3D object into an informative and discriminative one remains a key challenge for multi-view 3D object retrieval. Existing methods either use view-wise pooling strategies which neglect the spatial information across different views or employ recurrent neural networks which may face the efficiency problem. To address these issues, we propose an effective and efficient framework called View N-gram Network (VNN). Inspired by n-gram models in natural language processing, VNN divides the view sequence into a set of visual n-grams, which involve overlapping consecutive view sub-sequences. By doing so, spatial information across multiple views is captured, which helps to learn a discriminative global embedding for each 3D object. Experiments on 3D shape retrieval benchmarks, including ModelNet10, ModelNet40 and ShapeNetCore55 datasets, demonstrate the superiority of our proposed method.