 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGS: Open-Vocabulary 3D Scene Understanding with Context-Aware Gaussian Splatting
Apr 16, 2025Open-vocabulary 3D scene understanding is crucial for applications requiring natural language-driven spatial interpretation, such as robotics and augmented reality. While 3D Gaussian Splatting (3DGS) offers a powerful representation for scene reconstruction, integrating it with open-vocabulary frameworks reveals a key challenge: cross-view granularity inconsistency. This issue, stemming from 2D segmentation methods like SAM, results in inconsistent object segmentations across views (e.g., a "coffee set" segmented as a single entity in one view but as "cup + coffee + spoon" in another). Existing 3DGS-based methods often rely on isolated per-Gaussian feature learning, neglecting the spatial context needed for cohesive object reasoning, leading to fragmented representations. We propose Context-Aware Gaussian Splatting (CAGS), a novel framework that addresses this challenge by incorporating spatial context into 3DGS. CAGS constructs local graphs to propagate contextual features across Gaussians, reducing noise from inconsistent granularity, employs mask-centric contrastive learning to smooth SAM-derived features across views, and leverages a precomputation strategy to reduce computational cost by precomputing neighborhood relationships, enabling efficient training in large-scale scenes. By integrating spatial context, CAGS significantly improves 3D instance segmentation and reduces fragmentation errors on datasets like LERF-OVS and ScanNet, enabling robust language-guided 3D scene understanding.
Depth-guided Texture Diffusion for Image Semantic Segmentation
Aug 17, 2024



Depth information provides valuable insights into the 3D structure especially the outline of objects, which can be utilized to improve the semantic segmentation tasks. However, a naive fusion of depth information can disrupt feature and compromise accuracy due to the modality gap between the depth and the vision. In this work, we introduce a Depth-guided Texture Diffusion approach that effectively tackles the outlined challenge. Our method extracts low-level features from edges and textures to create a texture image. This image is then selectively diffused across the depth map, enhancing structural information vital for precisely extracting object outlines. By integrating this enriched depth map with the original RGB image into a joint feature embedding, our method effectively bridges the disparity between the depth map and the image, enabling more accurate semantic segmentation. We conduct comprehensive experiments across diverse, commonly-used datasets spanning a wide range of semantic segmentation tasks, including Camouflaged Object Detection (COD), Salient Object Detection (SOD), and indoor semantic segmentation. With source-free estimated depth or depth captured by depth cameras, our method consistently outperforms existing baselines and achieves new state-of-theart results, demonstrating the effectiveness of our Depth-guided Texture Diffusion for image semantic segmentation.
Correspondence-Guided SfM-Free 3D Gaussian Splatting for NVS
Aug 16, 2024Novel View Synthesis (NVS) without Structure-from-Motion (SfM) pre-processed camera poses--referred to as SfM-free methods--is crucial for promoting rapid response capabilities and enhancing robustness against variable operating conditions. Recent SfM-free methods have integrated pose optimization, designing end-to-end frameworks for joint camera pose estimation and NVS. However, most existing works rely on per-pixel image loss functions, such as L2 loss. In SfM-free methods, inaccurate initial poses lead to misalignment issue, which, under the constraints of per-pixel image loss functions, results in excessive gradients, causing unstable optimization and poor convergence for NVS. In this study, we propose a correspondence-guided SfM-free 3D Gaussian splatting for NVS. We use correspondences between the target and the rendered result to achieve better pixel alignment, facilitating the optimization of relative poses between frames. We then apply the learned poses to optimize the entire scene. Each 2D screen-space pixel is associated with its corresponding 3D Gaussians through approximated surface rendering to facilitate gradient back propagation. Experimental results underline the superior performance and time efficiency of the proposed approach compared to the state-of-the-art baselines.
Uncertainty-guided Optimal Transport in Depth Supervised Sparse-View 3D Gaussian
May 30, 2024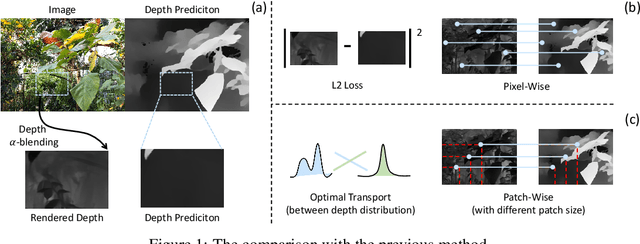
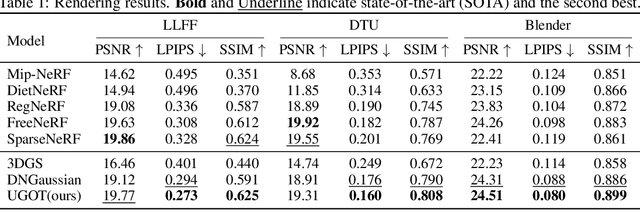
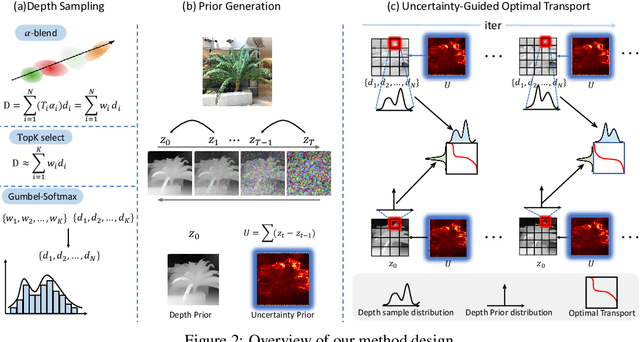
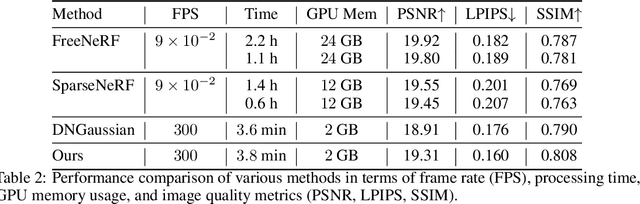
3D Gaussian splatting has demonstrated impressive performance in real-time novel view synthesis. However, achieving successful reconstruction from RGB images generally requires multiple input views captured under static conditions. To address the challenge of sparse input views, previous approaches have incorporated depth supervision into the training of 3D Gaussians to mitigate overfitting, using dense predictions from pretrained depth networks as pseudo-ground truth. Nevertheless, depth predictions from monocular depth estimation models inherently exhibit significant uncertainty in specific areas. Relying solely on pixel-wise L2 loss may inadvertently incorporate detrimental noise from these uncertain areas. In this work, we introduce a novel method to supervise the depth distribution of 3D Gaussians, utilizing depth priors with integrated uncertainty estimates. To address these localized errors in depth predictions, we integrate a patch-wise optimal transport strategy to complement traditional L2 loss in depth supervision. Extensive experiments conducted on the LLFF, DTU, and Blender datasets demonstrate that our approach, UGOT, achieves superior novel view synthesis and consistently outperforms state-of-the-art methods.
BEAM: Beta Distribution Ray Denoising for Multi-view 3D Object Detection
Feb 06, 2024



Multi-view 3D object detectors struggle with duplicate predictions due to the lack of depth information, resulting in false positive detections. In this study, we introduce BEAM, a novel Beta Distribution Ray Denoising approach that can be applied to any DETR-style multi-view 3D detector to explicitly incorporate structure prior knowledge of the scene. By generating rays from cameras to objects and sampling spatial denoising queries from the Beta distribution family along these rays, BEAM enhances the model's ability to distinguish spatial hard negative samples arising from ambiguous depths. BEAM is a plug-and-play technique that adds only marginal computational costs during training, while impressively preserving the inference speed. Extensive experiments and ablation studies on the NuScenes dataset demonstrate significant improvements over strong baselines, outperforming the state-of-the-art method StreamPETR by 1.9% mAP. The code will be available at https://github.com/LiewFeng/BEAM.
Deep Reason: A Strong Baseline for Real-World Visual Reasoning
May 24, 2019
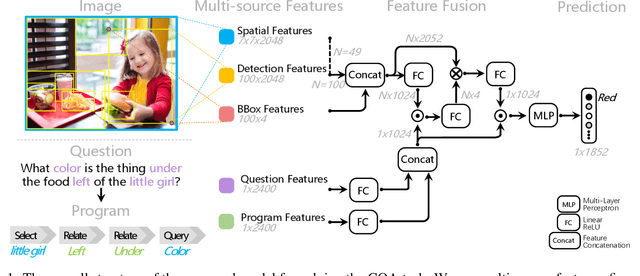


This paper presents a strong baseline for real-world visual reasoning (GQA), which achieves 60.93% in GQA 2019 challenge and won the sixth place. GQA is a large dataset with 22M questions involving spatial understanding and multi-step inference. To help further research in this area, we identified three crucial parts that improve the performance, namely: multi-source features, fine-grained encoder, and score-weighted ensemble. We provide a series of analysis on their impact on performance.
Weakly Supervised Instance Segmentation using Class Peak Response
Apr 03, 2018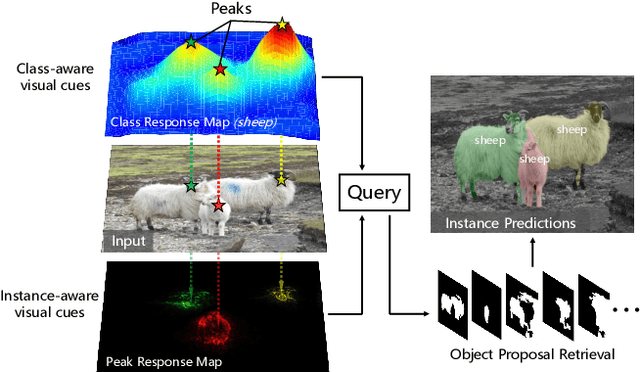
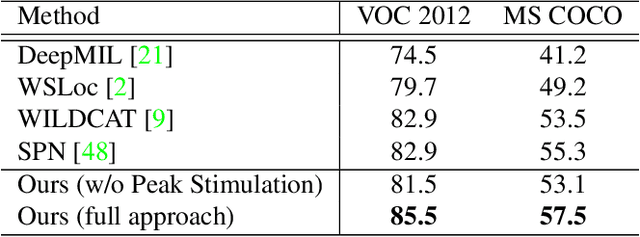


Weakly supervised instance segmentation with image-level labels, instead of expensive pixel-level masks, remains unexplored. In this paper, we tackle this challenging problem by exploiting class peak responses to enable a classification network for instance mask extraction. With image labels supervision only, CNN classifiers in a fully convolutional manner can produce class response maps, which specify classification confidence at each image location. We observed that local maximums, i.e., peaks, in a class response map typically correspond to strong visual cues residing inside each instance. Motivated by this, we first design a process to stimulate peaks to emerge from a class response map. The emerged peaks are then back-propagated and effectively mapped to highly informative regions of each object instance, such as instance boundaries. We refer to the above maps generated from class peak responses as Peak Response Maps (PRMs). PRMs provide a fine-detailed instance-level representation, which allows instance masks to be extracted even with some off-the-shelf methods. To the best of our knowledge, we for the first time report results for the challenging image-level supervised instance segmentation task. Extensive experiments show that our method also boosts weakly supervised pointwise localization as well as semantic segmentation performance, and reports state-of-the-art results on popular benchmarks, including PASCAL VOC 2012 and MS COCO.
Soft Proposal Networks for Weakly Supervised Object Localization
Sep 06, 2017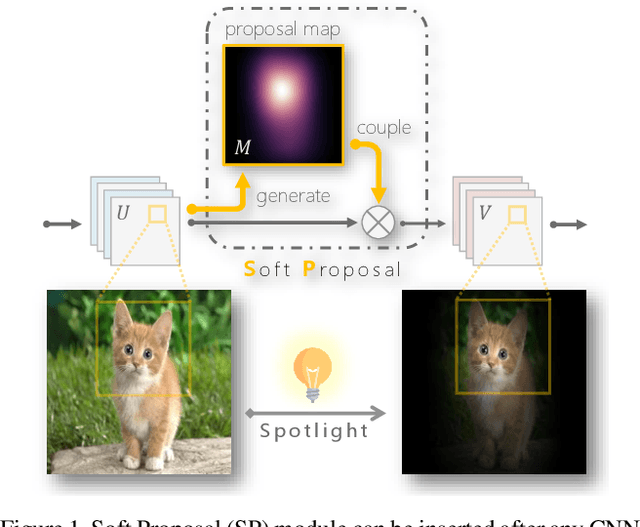
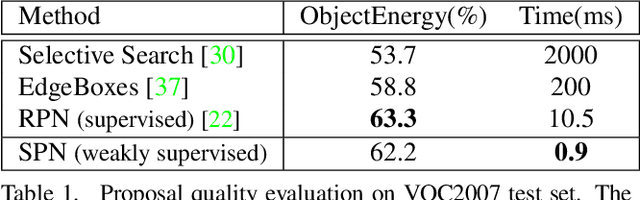
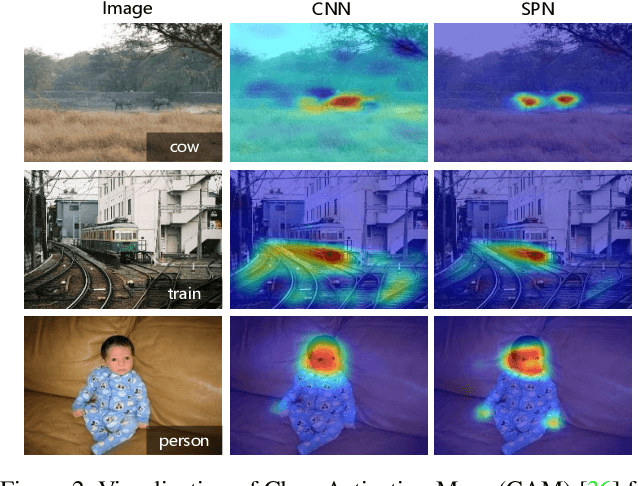
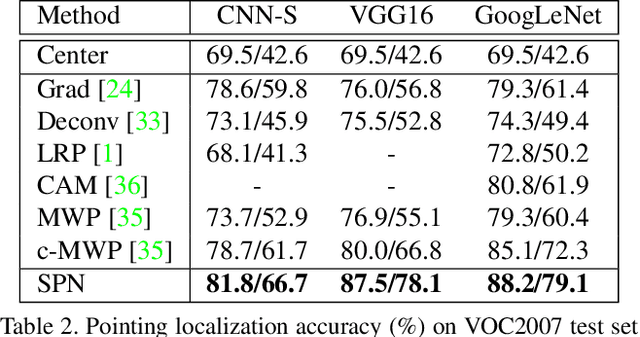
Weakly supervised object localization remains challenging, where only image labels instead of bounding boxes are available during training. Object proposal is an effective component in localization, but often computationally expensive and incapable of joint optimization with some of the remaining modules. In this paper, to the best of our knowledge, we for the first time integrate weakly supervised object proposal into convolutional neural networks (CNNs) in an end-to-end learning manner. We design a network component, Soft Proposal (SP), to be plugged into any standard convolutional architecture to introduce the nearly cost-free object proposal, orders of magnitude faster than state-of-the-art methods. In the SP-augmented CNNs, referred to as Soft Proposal Networks (SPNs), iteratively evolved object proposals are generated based on the deep feature maps then projected back, and further jointly optimized with network parameters, with image-level supervision only. Through the unified learning process, SPNs learn better object-centric filters, discover more discriminative visual evidence, and suppress background interference, significantly boosting both weakly supervised object localization and classification performance. We report the best results on popular benchmarks, including PASCAL VOC, MS COCO, and ImageNet.
Oriented Response Networks
Jul 13, 2017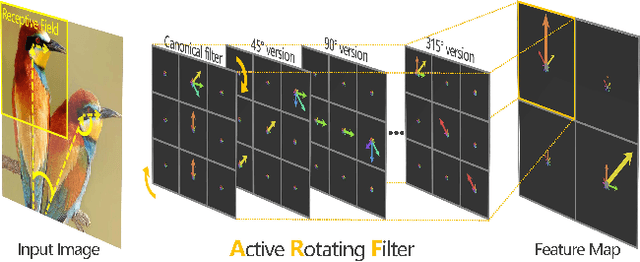
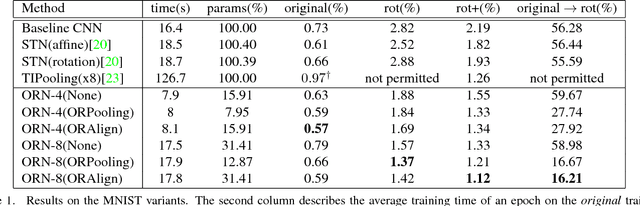
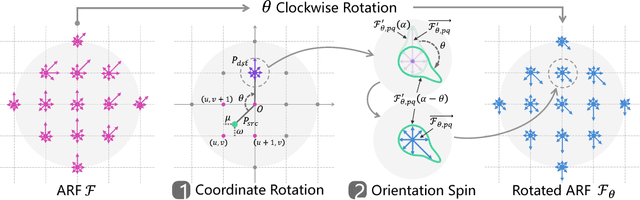
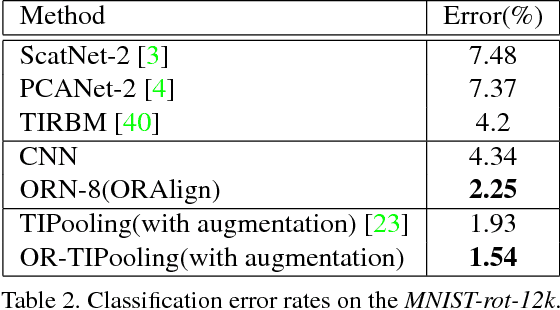
Deep Convolution Neural Networks (DCNNs) are capable of learning unprecedentedly effective image representations. However, their ability in handling significant local and global image rotations remains limited. In this paper, we propose Active Rotating Filters (ARFs) that actively rotate during convolution and produce feature maps with location and orientation explicitly encoded. An ARF acts as a virtual filter bank containing the filter itself and its multiple unmaterialised rotated versions. During back-propagation, an ARF is collectively updated using errors from all its rotated versions. DCNNs using ARFs, referred to as Oriented Response Networks (ORNs), can produce within-class rotation-invariant deep features while maintaining inter-class discrimination for classification tasks. The oriented response produced by ORNs can also be used for image and object orientation estimation tasks. Over multiple state-of-the-art DCNN architectures, such as VGG, ResNet, and STN, we consistently observe that replacing regular filters with the proposed ARFs leads to significant reduction in the number of network parameters and improvement in classification performance. We report the best results on several commonly used benchmarks.